Spark筆記三之RDD,運算元
RDD核心概念
Resilientdistributed DataSet,彈性分散式資料集
1是隻讀的,分割槽記錄的集合物件
2分割槽(partition)是RDD的基本組成單位,其決定了平行計算的粒度。應用程式對RDD的轉換最終都是對其分割槽的轉換。
3使用者可以指定RDD的分割槽個數,如果不指定則預設程式分配到的CPU的core數
4每個分割槽被影射為一個block,在呼叫hdfs底層時此block對應於hdfs的block(預設128M),spark通過blockManager來管理block是一個block管理器。
RDD的建立
例
sc.textFile("hdfs://shb01:9000/word").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).collect
1檔案系統載入
通過textFile從檔案系統(hive,hdfs)載入資料建立一個RDD
2RDD之間的轉換
例子中flatMap方法會產生RDD,之後在此RDD的基礎上每呼叫一個方法就會建立一個RDD,如果前面的父RDD如果不呼叫cache方法儲存則會消失。
3通過函式轉換
通過parallelize,makeRDD方法也可以轉換生成RDD
val rdd1 =sc.makeRDD(Array(("A",1),("B",2),("C",3)))
val rdd1 =sc.parallelize(Array(10,12,3,5,23))//sc.parallelize(seq, numSlices)
運算元
在spark中函式又稱為運算元,運算元分為兩大類轉換運算元(Transformations)和行動(Action)運算元.
轉換型運算元:不會立即執行,不會觸發計算通常使RDD之間互相轉換,轉換型運算元又分為value型運算元和key-value型運算元
行動行運算元:立即執行觸發DAG計算
Value型運算元:
Key-value型運算元:使用key-value型運算元必須引入SparkContext._
importorg.apache.spark.SparkContext._
運算元作用於rdd上,但由於rdd是由partition(分割槽)組成,所以運算元最終還是作用於分割槽上。
例:
val file =sc.textFile("hdfs://shb01:9000/word")
val errors = file.filter(line =>line.contains("ERROR")).count()
這是一個過濾日誌的程式碼,filter會在file基礎上再產生一個rdd,會作用於每個分割槽上然後得到一個新分割槽,這些新分割槽的總和組成一個rdd。另外一個分割槽對應一個task。
spark-core_包下的rdd類可以檢視運算元的定義
package org.apache.spark.rdd
分割槽依賴關係
運算元操作父rdd中的分割槽併產生子rdd和分割槽,父rdd如果不儲存就會被丟棄,一旦子rdd計算失敗就需要重新計算父rdd。Spark中通過rdd之間的依賴關係來確定需要重新計算那些父rdd。
依賴關係分為兩種窄依賴(NarrowDependencies)和寬依賴(Wide Dependencies)
窄依賴:子rdd的一個分割槽依賴一個或多個父rdd中的一個分割槽
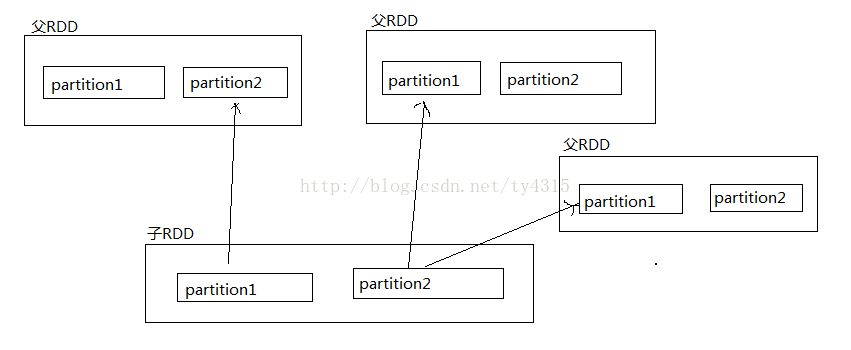
寬依賴:子RDD中的一個分割槽依賴父RDD的兩個或多個或全部分割槽
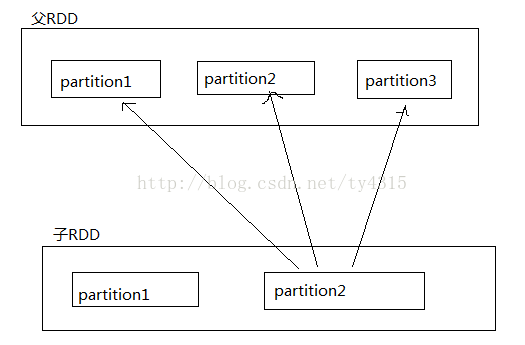
窄依賴:重新計算時代價小,只需要計算一個partition在一臺機器上就能完成
寬依賴:重新計算時代價大,可能需要計算多個partition,而partition對應的是叢集中的block,而這些block很有可能會儲存在叢集的多個節點上。
所以一般需要將寬依賴的RDD進行快取
判斷寬依賴:
1一般情況下value型的運算元產生的RDD是窄依賴,key-value型的運算元產生的RDD是寬依賴。
2通過呼叫dependencies來判斷是那種分割槽依賴關係
顯示oneToOne是窄依賴,反之如果顯示shuffledRDD則是寬依賴