
你應該知道的9篇深度學習論文(CNNs 理解)
想象一個很深的CNN架構,把它的層數翻兩番,它的深度可能還比不上ResNet,它是微軟亞研MRA在2015年提出的架構。ResNet是一個擁有152層網路架構的新秀,它集分類、檢測與翻譯功能於一身。除開層數破了紀錄,ResNet自身的表現也破了ILSVRC2015的記錄,達到了不可思議的3.6%(通常人類也只能達到5~10%的出錯率,跟專業領域和技能相關。請參考Andrej Karpathy以自身經驗撰寫的,有關ImageNet挑戰中人類與卷積網路ConvNet競賽的雄文great post)。
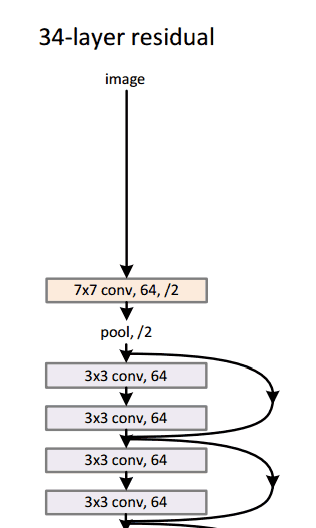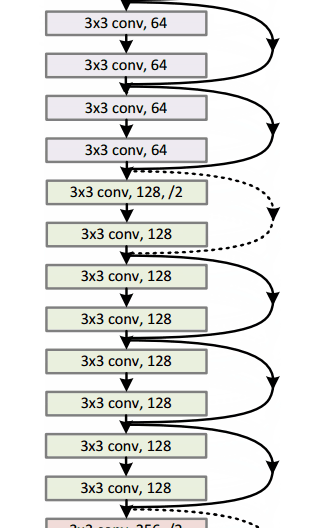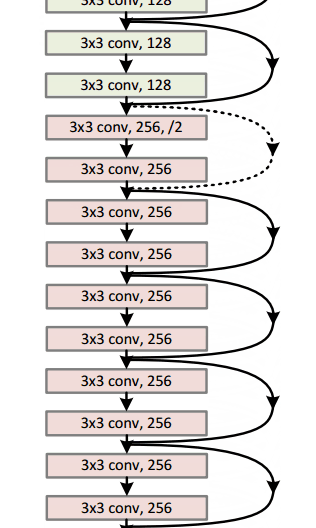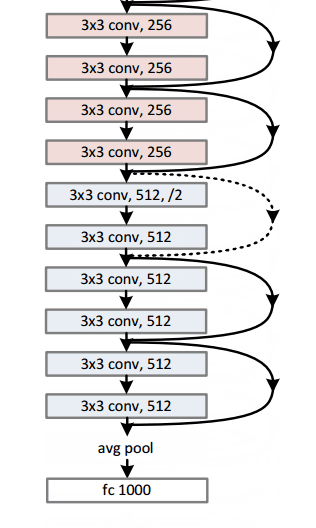
Residual Block
文章中提出的殘差區塊residual block概念,其設計思路是這樣的:當我們的輸入x通過卷積-線性整流-卷積系列操作後,產生的結果設為F(x),將其與原始輸入x相加,就有H(x)=F(x)+x。對比傳統CNN,只有H(x)=F(x)。而ResNet需要把卷積結果F(x)與輸入x相加。下圖的子模組表現了這樣一個計算過程,它相當於對輸入x計算了一個微小變化"delta",這樣輸出H(x)就是x與變化delta的疊加(在傳統CNN中,輸出F(x)完全是一個全新的表達,它並不包含輸入x的資訊)。文章作者認為,“這種殘差對映關係residual mapping比起之前的無關對映unreferenced mapping更加容易優化”。
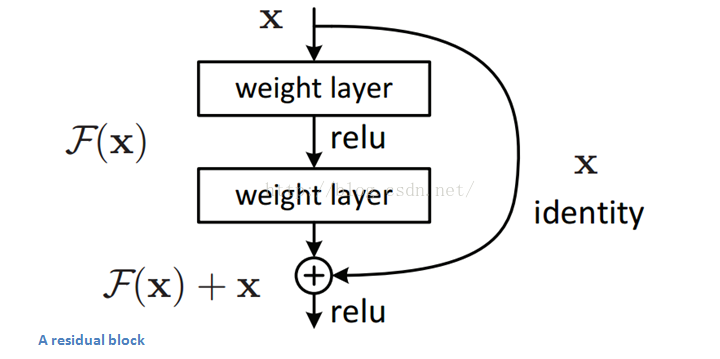
殘差區塊的另外一個優勢在於反向傳播操作時,梯度資訊流由於這些附加的計算,從而更加容易傳播flow easily through the effective。
文章要點
- “極度深寒Ultra-deep” - Yann LeCun
- 152層...
- 一個有意思的特點是,最初兩層處理後,輸入影象的空間尺寸由224*224壓縮至56*56
- 作者宣告若在平層網路plain nets中隨意增加層數會導致訓練計算量以及錯誤率上升(參考論文paper圖1)
- 研究團隊曾嘗試使用1202層網路架構,結果精確度反而降低了,推測原因是過擬合。
- 訓練使用一個8GPU的機器,持續了2~3周
文章重要性
模型達到的3.6%錯誤率本身就極具說服力了。ResNet模型是目前最棒的CNN架構,同時是殘差學習residual learning的一項重要創新。2012年以來,隨著錯誤率逐年下降,我很懷疑在ILSVRC2016上是否能看到更好的成績。我想我們也許已經到了一個瓶頸,僅依靠往模型中堆砌更多的卷積層已經難以獲取演算法效能上的提升了。就像之前的兩年那樣,今年的競賽一定會有更具創造性的新型模型架構。2016.9.16,這是今年比賽結果揭曉之日。別忘了。
Region Based CNNs (R-CNN - 2013, - 2015, - 2015)
也許會有人認為比起之前所說的那些新架構,R-CNN才是最重要,對業內影響最大的CNN模型。UC Berkeley的Ross Girshick團隊發明了這種在機器視覺領域有著深遠影響的模型,其相關論文被引量超過了1600次。如同標題所說的,Fast R-CNN以及Faster R-CNN方法使我們的模型能夠更好更快地解決機器視覺中的目標檢測問題。
目標檢測的主要目的是:給出一副影象,把其中所有物體都框起來。這個過程可以分為兩個主要的部分:目標標定、分類。
作者提出,針對區域標定方法,任何類不可知區域檢測法class agnostic region proposal method都是合適的。其中Selective Search方法特別適用於RCNN模型。Selective Search演算法在執行的過程中會生成2000個不同的,有最大可能性標定影象中的目標的區域標定region proposals。獲取到這些標定區域後,演算法把它們“變形warped”轉換為一幅影象並輸入一個已訓練好的CNN中(例如AlexNet),進行特徵向量的提取。隨後將這些向量作為一系列線性SVM分類器的輸入進行分類。同樣將這些向量輸入給區域邊界的迴歸分析器regressor,用於進一步精確獲取目標的位置。
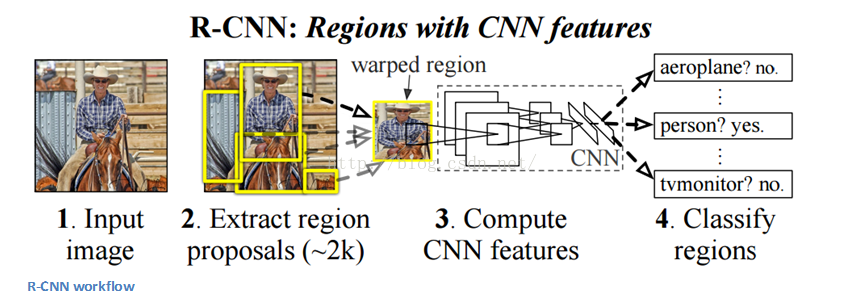
隨後,模型採用一個非極大值抑制演算法用於去除那些互相重疊的區域。
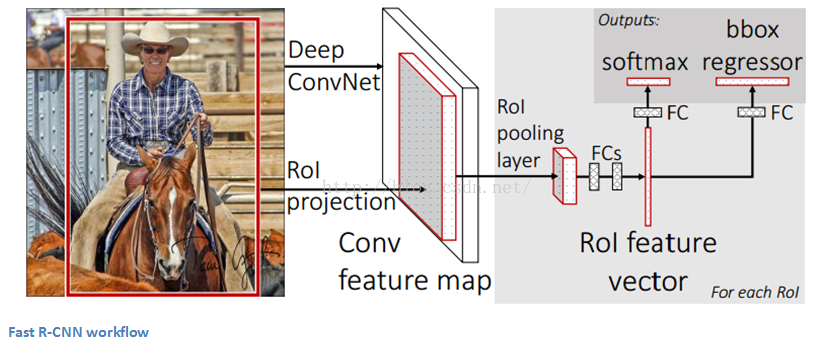
Fast R-CNN
Fast R-CNN針對之前模型的改進主要集中在這3個方面的問題。多個階段的訓練(卷積網路ConvNet、SVM、區域邊界迴歸分析)計算負載很大且十分耗時。Fast R-CNN通過優化流程與改變各生成標定區域的順序,先計算卷積層,再將其結果用於多個不同的功能計算模組,以此解決速度的問題。在模型中,輸入影象首先通過一個ConvNet,從其最後輸出的特徵圖層中獲取特徵標定區域(更多資訊參考論文2.1節paper),最後將其同時輸入全連通層、迴歸分析模組以及分類模組。(譯者按:這段基本上為字面翻譯,然而有許多不合常理的地方。從圖中看出標定區域似乎是在ConvNet之前,跟文中所述矛盾;另外圖中似乎應該有多個ROI區域,並行地進行ConvNet,輸出結果再並行輸入FC,regressor等)
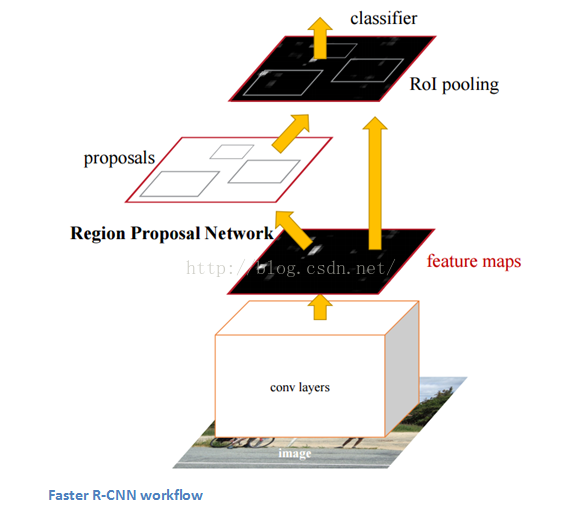
Faster R-CNN
Faster R-CNN用於解決在R-CNN和Fast R-CNN中的一些複雜的訓練流程。作者在最後一層卷積層後插入了一個區域標定網路region proposal network(RPN)。RPN能夠從其輸入的特徵圖層中生成標定區域region proposals。之後流程則跟R-CNN一樣(ROI池化、全連通、分類以及迴歸)
文章重要性
首先它能檢測影象中的特定物體;更重要的是它能夠找到這個物體在影象中的具體位置,這是機器學習的一個重要進步。目前,Faster R-CNN已經成為目標檢測演算法的標杆。
根據Yann LeCun的說法Yann LeCun,這個網路架構可以說又是一個大進步。在介紹這篇文章之前,我們先談談對抗樣本adversarial examples。例如,有一個經過ImageNet資料訓練好的CNN,現在給一副圖(如下圖左)加一些擾動或微小修改(中,右),輸入後導致預測錯誤率增加了許多。雖然影象看起來跟原來似乎是一樣的,但是最終分類卻與原先已經不同了。歸納起來,對抗樣本就是那些故意愚弄並破壞卷積網路ConvNets結果的影象。

圖中文字:左列影象為正確樣本,中間一列表示左和右圖之間的擾動,右列影象的大部分都被歸類為鴕鳥ostrich。事實上,人眼幾乎難以分辨左右圖之間的差異,然而卷積網路ConvNet在分類時竟會產生如此誇張的錯誤。
對抗樣本Adversarial examples (paper) 嚇到了許多研究人員並馬上成為議論的熱點。現在讓我們談談這個generative adversarial networks模型。這裡有兩個模型:產生模型generative model和判別模型discriminative model。判別模型discriminative model用於判斷某幅影象是天然的(直接來自資料集裡)還是人為製造的。產生模型generator則創造樣本供給判別模型discriminator訓練。這可以看成是一個零和zero-sum遊戲或是最小最大minimax遊戲。文章中用的類比是這樣的,產生模型generative model就像是“一群造假幣的”,而判別模型discriminative model則像是“抓造假幣者的警察”。產生模型不停地試圖欺騙判別模型而判別模型試圖識破欺騙。隨著模型的訓練,二者的能力不斷提升最後達到“贗品和正品已經完全分不清楚了”的程度。
論文重要性
聽起來這麼的簡單,那為什麼我們要關注這個模型呢?就像Yann LeCun在Quora網站上的帖子post所述,因為判別模型discriminator已經能夠識別來自資料集中的真實影象以及人工仿造的影象,因此可以說其探悉了“資料的內在表達”。因此,這個模型可用作CNN中的特徵提取器;另外你也可以用它來仿造一些以假亂真的影象。(link).
當你把CNN和RNN(迴圈神經網路)結合在一起會產生什麼?抱歉,別想錯了,你並不能得到R-CNN;-);但確實能得到一個很不錯的模型。Andrej Karpathy(我個人最喜歡的作者之一)和Fei-Fei Li所寫的這篇文章就是著重於研究將CNN與雙向RNN bidirectional RNN相結合生成用於描述影象區域的自然語言描述器。基本上這個模型通過輸入一副影象,產生如下的輸出:

看起來非常不可思議。讓我們看看它跟普通CNN有什麼不同。在傳統的模型中,針對訓練資料中的每一張圖片,都只有一個確定的標籤與之對應。但本文所描述的模型則通過一個句子(或標題)與影象相關聯。這種標籤形式被稱為弱標籤,其語句中的成分與影象中的(未知)部分相關聯。使用這樣的訓練集,讓一個深度神經網路模型“推斷語句成分與其描述的影象區域之間的潛在結合alignment關係(文中語)”;另外還有一個網路模型則將影象作為輸入,生成其文字描述。現在讓我們分別看看這兩個部分:配對alignment與產生generation。
Alignment Model
這個部分的主要目的在於將視覺資訊和文字資訊進行配對結合(影象和描述文字)。模型輸入一幅影象與一句話,然後對它們倆的匹配程度進行打分作為輸出(有關這個模型工作的具體細節,作者Karpathy引用了另外一篇論文paper。模型主要使用相容/不相容圖文對compatible and incompatible image-sentence pairs進行訓練。)
現在看一下該如何表現一幅影象。首先,把一幅影象輸入一個用ImageNet資料訓練過的R-CNN網路,檢測其中的物體。前19個檢測出來的物體(加上自身)表現為深度為500維的維度空間。那麼現在我們有了20個500維向量(文章中表示為v),這就是影象中的資訊。隨後,我們需要獲取語句中的資訊。我們利用雙向RNN架構,把輸入語句嵌入同樣的多模態維度空間。在模型的最高層,輸入的語句內容會以給定的句式(given sentence)表現出來。這樣,影象的資訊和語句資訊就處於同一個建模空間內,我們通過計算其內積就可以求得相似度了。
Generation Model
剛才說了,配對alignment模型建立了一個存放影象資訊(通過RCNN)和對應文字資訊(通過BRNN)的資料集。現在我們就可以利用這個資料集來訓練產生generation模型,讓模型從給定影象中生成一個新的描述文字資訊。模型將一幅影象輸入CNN,忽略其softmax層,其全連通層的輸出直接作為另一個RNN的輸入。這個RNN的主要功能則是為語句的不同單詞形成一個概率分佈函式。(同樣需要另外訓練)
宣告:這絕對是最難懂的文章之一,如果大家對我的講述有不同意見和建議,請一定在評論區留言。

文章重要性
對我來說,本文要點在於利用了看起來似乎不同的兩種模型RNN和CNN,創造了一個結合機器視覺和自然語言處理兩方面功能的應用。它打開了新世界的大門,提供了一個新的思路,使得深度學習模型更加聰明並能夠勝任跨學科領域的任務。
最後,讓我們介紹一個最近的文章。這篇文章是由Google Deepmind研究組在一年前撰寫的。它提出了一種空間變形模組Spatial Transformer module。模組將輸入影象進行某種變形從而使得後續層處理時更加省時省力。比起修改CNN的主要結構,作者更關注於對輸入影象進行改造。它進行的改造主要有兩條:姿態正規化pose normalization(主要指影象場景中的物體是否傾斜、是否拉伸)以及空間聚焦spatial attention(主要指在一個擁擠的影象中如何聚焦某個物體)。在傳統CNN中,如果想要保證模型對尺度和旋轉具有不變性,那麼需要對應的大量訓練樣本。而在這個變形模組中,則不需要如此麻煩,下面就讓我們看看它是怎麼做的。
在傳統CNN中,應對空間不變性的模組主要是最大池化maxpooling層。其背後的直觀原因在於最大池化層能夠提取特徵資訊(在輸入影象中有著高啟用值的那些區域)的相對位置作為一個重要屬性,而不是絕對位置。而文中所述的空間變形模組則是通過一種動態的方式對輸入影象進行變換(扭曲、變形)。這種形式不像傳統的最大池化操作那樣簡單與死板。讓我們看看它的組成:
- 一個區域性網路結構,通過輸入影象計算出應該對影象採用的形變引數並將其輸出。形變引數稱作theta,定義為一個6維的仿射變換向量。
- 一個正規化網格經過上述引數的仿射變換之後生成的取樣網格產物。
- 用作對輸入圖層變換的取樣器sampler
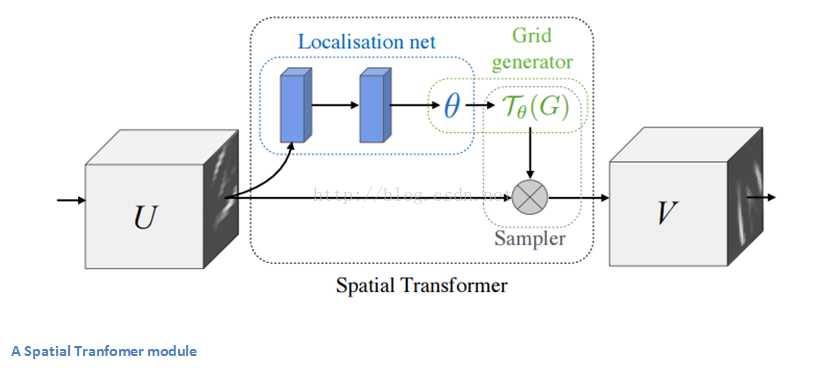
這樣的一個模組可以插入於CNN網路的任何地方,幫助整個網路結構學習特徵圖層形變,降低訓練成本。
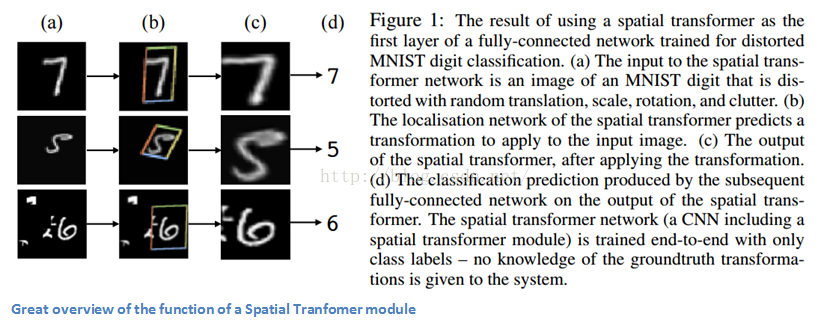
文章重要性
這篇文章吸引眼球的地方在於它提出這樣的一種可能性:對CNN的改進並不一定要對網路架構的大規模修改,也不需要創造出另外一個ResNet或Inception module這樣的複雜模型。這篇文章通過實現了一個對輸入影象進行仿射變換的簡單功能從而讓模型擁有了很強的形變、伸縮、旋轉不變性。如果對本文所述的模型還有興趣的同學,可以看一下這個Deepmind團隊的視訊video,對CNN加空間形變模組的結果有很好的展示,同時也可以參考這個Quora討論貼discussion。
這就是我們的卷積網路入門的三部曲。希望大家能從中獲益。如果你覺得文中遺漏了什麼重要的資訊,請在評論區告知我。如果你想知道更多這方面的資訊,我再次強烈推薦Stanford的CS 231n視訊課程,你只需在YouTube上搜一下就能找到。