
BloomFilter布隆過濾器使用
從上一篇可以得知,BloomFilter的關鍵在於hash演算法的設定和bit陣列的大小確定,通過權衡得到一個錯誤概率可以接受的結果。
演算法比較複雜,也不是我們研究的範疇,我們直接使用已有的實現。
google的guava包中提供了BloomFilter類,我們直接使用它來進行一下簡單的測試。
測試分兩步:
一 我們往過濾器裡放一百萬個數,然後去驗證這一百萬個數是否能通過過濾器,目的是校驗是壞人是否一定被抓。
二 我們另找1萬個不在這一百萬範圍內的數,去驗證漏網之魚的概率,也就是布隆過濾器的誤傷情況。
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; import java.util.ArrayList; import java.util.List; /** * Created by admin on 17/7/7. * 布隆過濾器 */ public class Test { private static int size = 1000000; private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size); public static void main(String[] args) { for (int i = 0; i < size; i++) { bloomFilter.put(i); } for (int i = 0; i < size; i++) { if (!bloomFilter.mightContain(i)) { System.out.println("有壞人逃脫了"); } } List<Integer> list = new ArrayList<Integer>(1000); for (int i = size + 10000; i < size + 20000; i++) { if (bloomFilter.mightContain(i)) { list.add(i); } } System.out.println("有誤傷的數量:" + list.size()); } }
執行後發現,沒有壞人逃脫,當我們去遍歷這一百萬個數時,他們都在過濾器內被識別了出來。
誤傷的數量是330.也就是有330個不在過濾器內的值,被認為在過濾器裡,被誤傷了。
錯誤概率是3%作用,為毛是3%呢。我們跟蹤原始碼看一下就知道了。
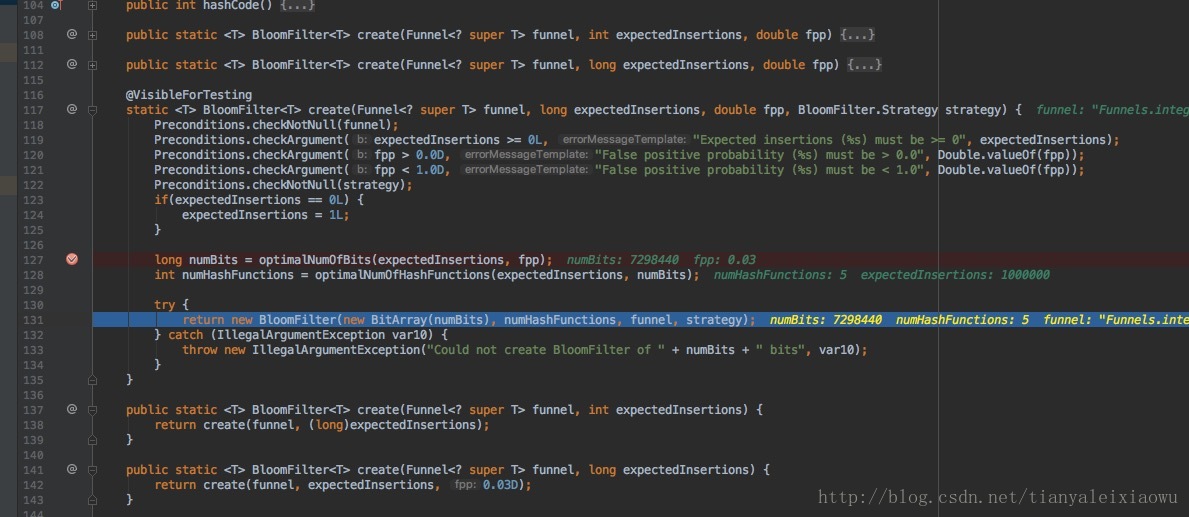
在create的多個過載方法中,最終走的是有4個引數的那個。我們上面用的是有2個引數的,注意看圖片最下面,我們不填第三方引數時,預設補了一個0.03,這個就代表了允許的錯誤概率是3%。第四個引數是雜湊演算法,預設是BloomFilterStrategies.MURMUR128_MITZ_64,這個我們不去管它,反正也不懂。
在第127行可以看到,要存下這一百萬個數,位陣列的大小是7298440,700多萬位,實際上要完整存下100萬個數,一個int是4位元組32位,我們需要4X8X1000000=3千2百萬位,差不多隻用了1/5的容量,如果是HashMap,按HashMap 50%的儲存效率,我們需要6千4百萬位,所有布隆過濾器佔用空間很小,只有HashMap的1/10-1/5作用。
128行是hash函式的數量,是5,也就是說系統覺得要保證3%的錯誤率,需要5個函式外加700多萬位即可。用3%誤差換十分之一的記憶體佔用。
我們也可以修改這個錯誤概率,譬如我們改為0.0001萬分之一。
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.0001);再次執行看看
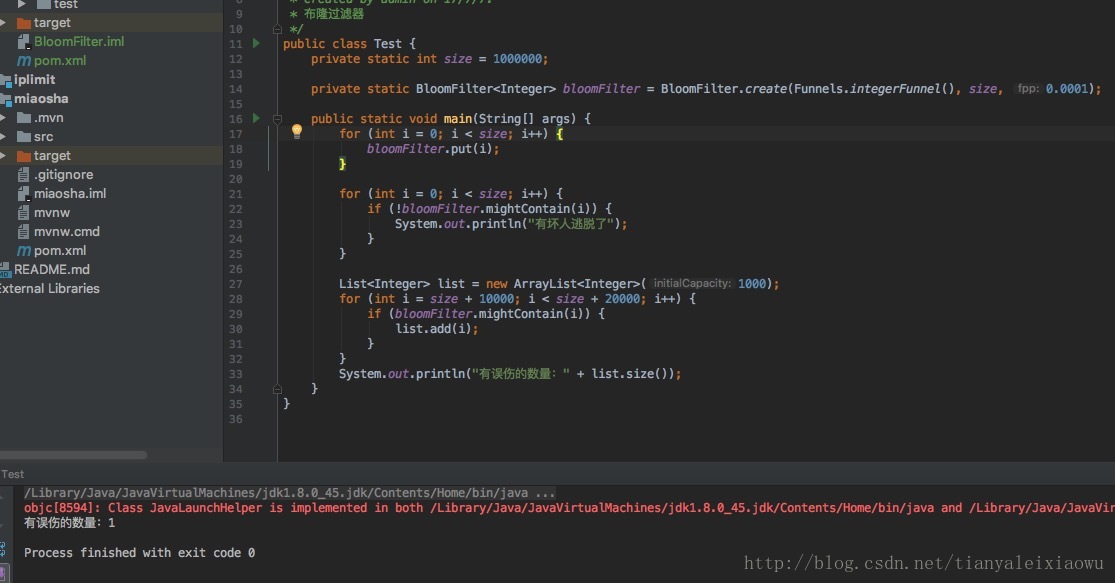
我們將28行改為10萬個數,發現結果為“誤傷12”。可以看到這個概率是比較靠譜的。
當概率為萬分之一時,我們看看空間佔用。
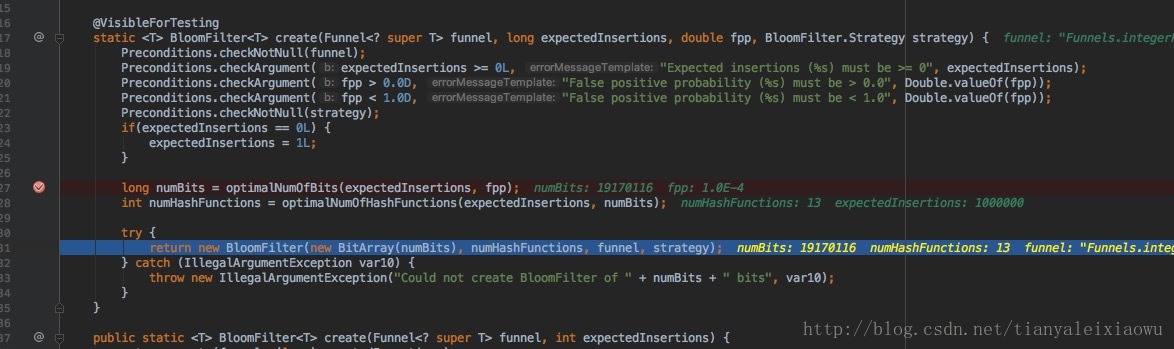
此時bit容量已經從700多萬到1900萬了,函式數量也從5變成了13.概率從3%縮減到萬分之一。
這就是布隆過濾器的簡單使用。具體的應用場景,具體實現。