深度學習筆記——理論與推導之Structured Learning【Sequence Labeling Problem】(八)
Sequence Labeling(序列標註問題),可以用RNN解決,也可以用Structured Learning(two steps,three problems)解決
常見問題:
- POS tagging(標記句子中每個詞的詞性):
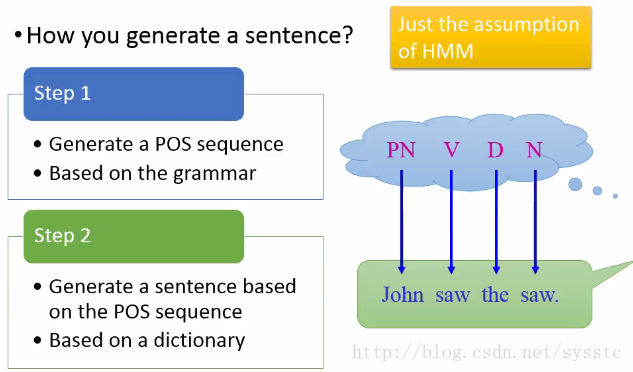
如:John saw the saw–>PN V D N
Hidden Markov Model(HMM)
問題引入
- 生成一個句子的兩個步驟:
- Step1:
- 基於語法,生成一個POS sequence(詞性標註序列)
- Step2:
- POS sequence 轉變為 word sequence
- 圖示如下:
詳細步驟如下:
Step1:根據腦中的文法,生成一個Markov Chain。
Step2:
- Step1:
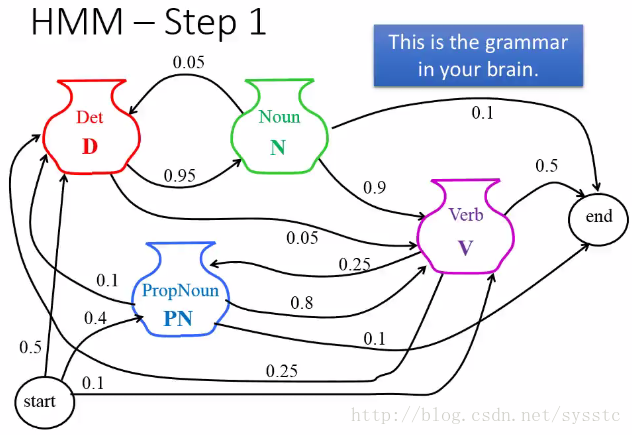
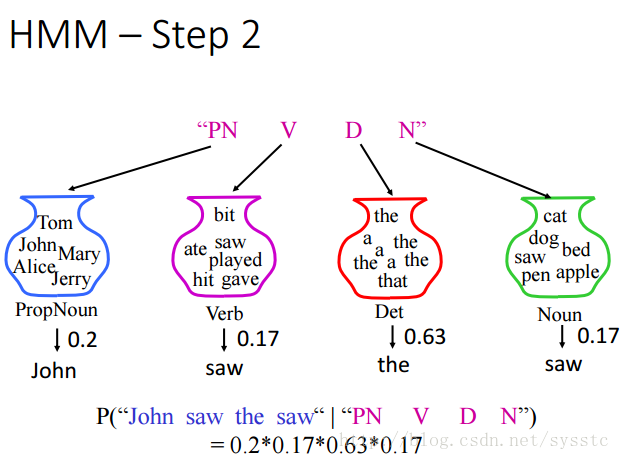
HMM是什麼
HMM的定義:Estimating the probabilities
描述我們是如何說出一句話的,即描述根據POS tagging sequence說出word sequence的機率。也就是下圖x和y同時出現的機率,因此這裡涉及到兩個概率:P(y)和P(x|y)

HMM的兩個概率:
我們可以得到下面的詳細公式,P(y)代表的是Transition probability(轉換概率),P(x|y)代表的是Emission probability(輸出概率)。

那麼我們應該如何得到上面兩個概率呢?我們可以通過Training data獲取上面兩個概率:

如何處理POS Tagging:
任務:給定一個句子x,找出詞性y,其實就是要計算出P(x,y)。
思路:

步驟:
窮舉所有的y,判斷哪個P(x,y)最大。窮舉所有的y,可能會很大,因此我們用到了Viterbi algorithm

HMM- Summary:
HMM也是Structured Learning的一種方法,因此我們要回答下述問題:
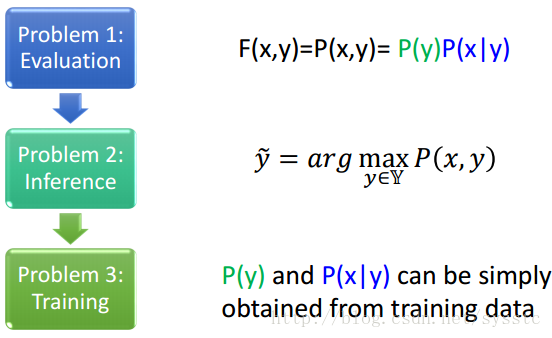
HMM-Drawbacks:
- 在做Inference時,我們希望讓(x,y head)> (x,y),但是HMM可以做到這件事情嗎?我們發現,HMM並沒有保證讓P(x,y head)>P(x,y)一定成立。
案例如下:

這時候,已知了yl-1 = N,xl = a,則我們得到yl = V的概率是0.9*0.5 = 0.45與,yl = D的概率是0.1*1 = 0.1,通過概率計算,我們知道yl = V的概率比較大。

- 然而,如果今天N->V->c在training data中出現9次,P->V->a在training data中出現9次,N->D->a在training data中出現1次。那麼,按照結構圖來說(N->?->a),?應該為D。

- 而概率計算卻告訴我們,應該為N->V->a
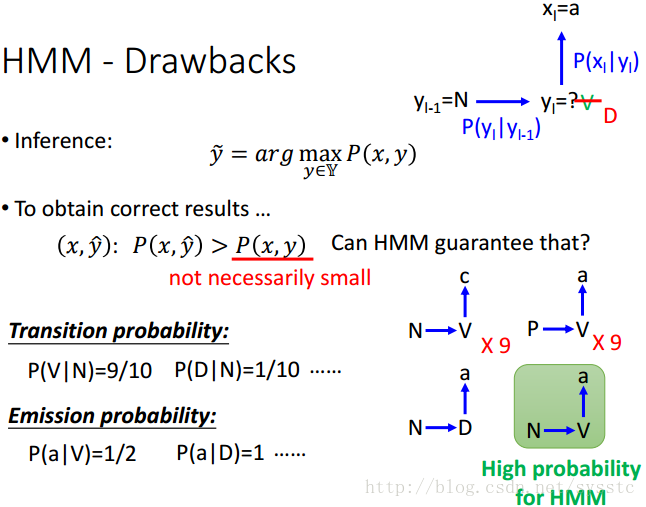
HMM優缺點分析:
缺點:從未在training data中出現的(x,y),甚至比在training data中出現過的(x,y)概率更高;
優點:但training data比較少的時候。
缺點解決方法:更加複雜的模型可以解決這個問題。
Conditional Random Field(CRF)
CRF引入
P(x,y)∝exp(w·Φ(x,y))
- Φ(x,y)是一個feature vector
- w是一個weight vector,它可以從training data中得到
- exp(w·Φ(x,y))是一個正值,它有可能大於1
我們可以根據這個正比公式做推導:
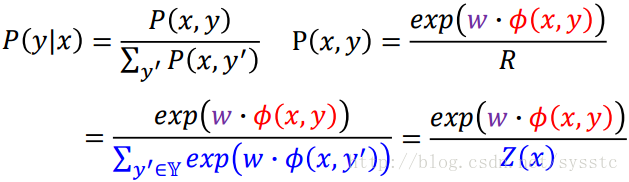
那麼CRF和HMM有什麼區別呢?
1. 在HMM中,我們可以得到以下推導:
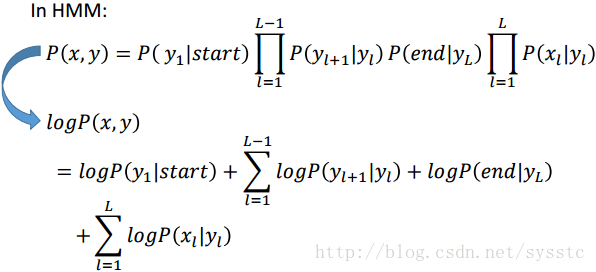
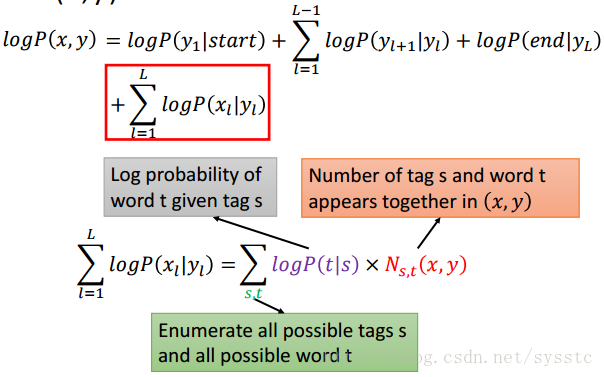
- 在CRF中,我們可以得到以下推導,N這一項,代表的是s,t在(x,y)pair中出現的次數:
為什麼可以做上述變換呢,下面看一個例子:
那麼對其他項我們也可以做上述變換:
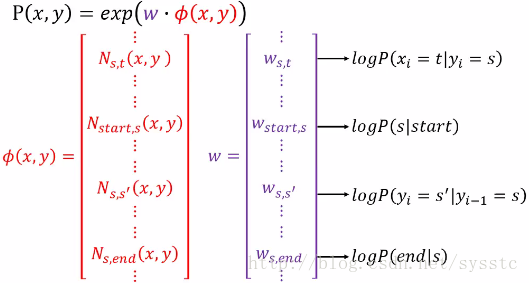
接下來對上述變換做element-wise,我們可以用w代表紫色部分,由於紅色部分每個都是和x,y有關的,所以我們可以說這個是(x,y)pair形成的function,所以我們的P(x,y) = exp(w·Φ(x,y)):
我們可以把w和HMM中的機率做對應,如下:
所以,你可以對w做exp,就可以得到概率,然而由於weight中的element沒有任何限制,可正可負,所以我們說P(x,y)∝exp(w·Φ(x,y)):




Feature Vector
- 那麼Feature Vector長什麼樣呢?
根據上面推導,我們知道Φ(x,y)應該由下面兩部分構成:
- Part1:詞性和單詞之間的關係
- Part2:詞性之間的關係
那麼如果是有|S|個可能的tags,|L|個可能的words,那麼Part1就是|S|×|L|維的,Part2就是|S|×|S|+2|S|(2|S|是因為還有個Start和End)維的。



CRF-Training Criterion
- 我們這裡需要求得是給定一組training data,我們需要找到一個weight vector w*使得給定一個x,找到正確的y head的概率取log後求和後越大越好(最大化)。我們發現這裡的O(w)和之前的cost function有點像,maximizing正確的機率再取log。
接下來,由於下圖右上角的公式,所以我們可以得到下面的log公式,所以CRF在做training時,由於要O(w)最大化,所以,我們需要讓前一項的,也就是我們觀察到的(x,y)的概率變大,我們沒觀察到的(x,y)的概率變小。

CRF-Gradient Ascent
- 如何maximizing O(w),這裡就需要Gradient Ascent:
- 經過一串運算後,我們知道下面公式可以分為兩項,我們來分析這兩項的物理意義,第一項來說,當(s,t)pair在正確的(x^n,y head ^n)中出現的次數越多表示w越大,求解出來的Gradient Ascent也就越大;第二項來說,減掉任意一個(x,y)pair中(s,t)出現的次數,所以今天當(s,t)pair在任意一個(x,y) pair中出現的次數越多,表示,這時我們需要減小w。:
所以針對所有的Gradient,這個Gradient就是正確的y head形成的feature vector減掉任意的一個y形成的vector在乘上那個y的機率:

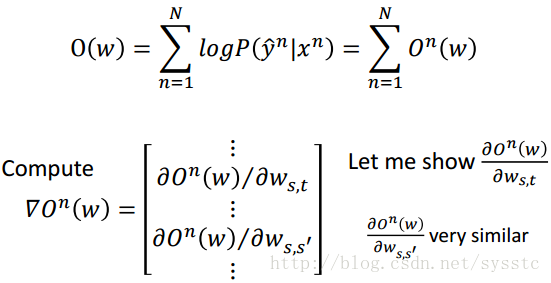


CRF-Inference
- 我們要做的事情就是給定一個x,我們要找一個y,讓P(y|x)最大。

CRF vs HMM
CRF更有可能得到正確的結果。

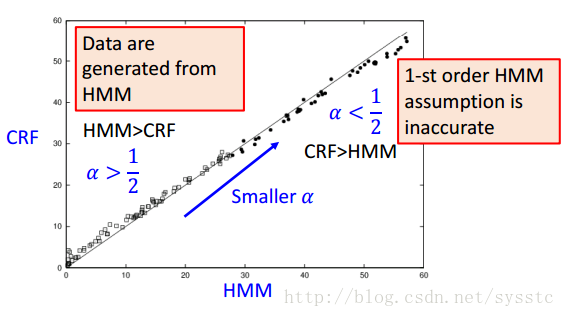
Synthetic Data
當α=1時是一般的HMM,α越小表現越差。

比較不同α上HMM和CRF的表現,每個圈圈是不同α得到的結果,橫軸和縱軸表示HMM 和CRF的犯錯的百分比,因為這個task的data是由HMM產生的,所以當α大於1/2表示,模型比較接近HMM或CRF的model,
CRF-Summary
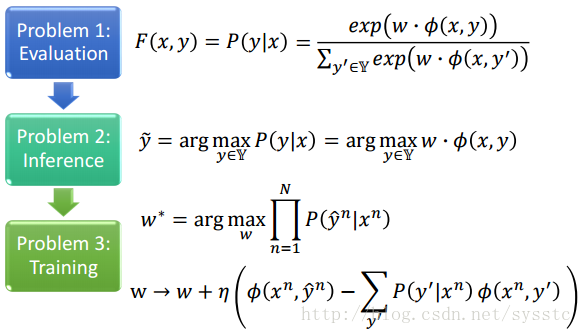
Structured Perceptron/SVM
Structured Perceptron

Structured Perceptron vs CRF
Structured Perceptron和CRF的Gradient Ascent非常相似,Structured Perceptron只減掉某一個y,但它所減掉的是可以讓w·Φ(x,y)最大的y;CRF其實就是用所有的y做Gradient Ascent。
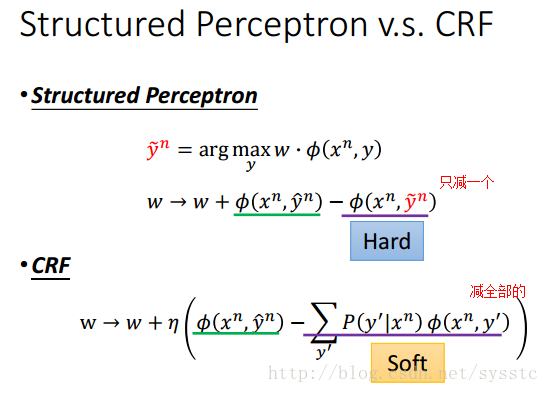
CRF:所有y可能形成的feature做Gradient Ascent。
如果今天y’中只有一項機率為1,其他都是0,那麼CRF和Structured Perceptron就是一樣的。
Structured SVM
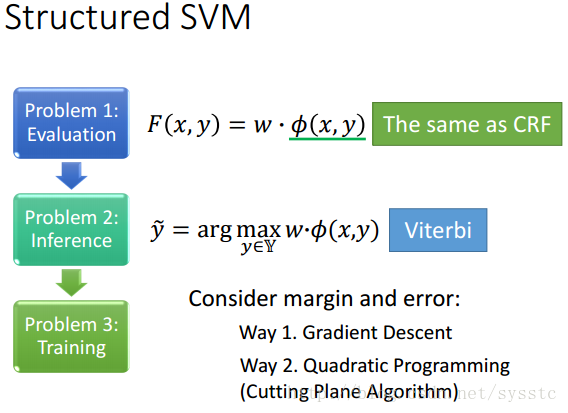
- Structured SVM中很不一樣的是要考慮:Error function:Δ(y head^n, y),這項是用來考慮y和y head^n的區別的。
- 我們之前說過Structured SVM的cost function其實就是Error 的upper bound,所以如果去minimize cost function就是在計算Error的upper bound。
- Error function可以是任何適當的衡量兩個y之間差異的function
- 但是,無論是使用Gradient Descent還是Quadratic Programming,我們都要知道如何解決下面的Problem2.1,下面提供一個計算Δ的例子(計算兩個sequence的錯誤率)。

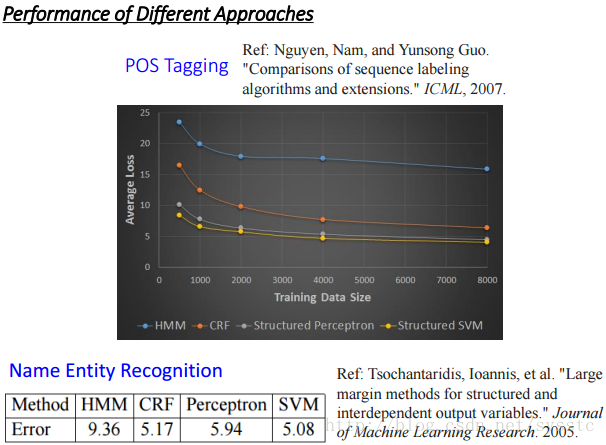
Structured SVM vs HMM vs CRF vs Structured Perceptron
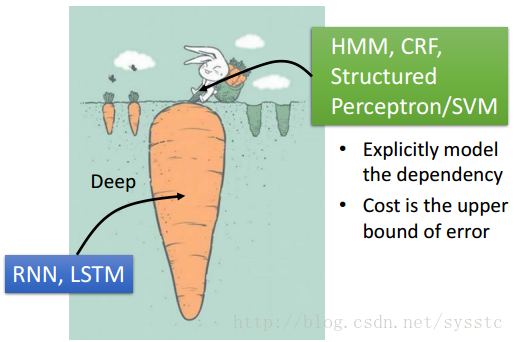
Towards Deep Learning
sequence label可以用以下幾種方法來解,那麼用什麼方法好呢?
RNN,LSTM vs HMM、CRF、Structured Perceptron/SVM
- RNN/LSTM的缺點1:如果用的是單向RNN或LSTM是隻看了sequence的一部分(看不到t+1的),而HMM等看過了全部的sequence。
- RNN/LSTM的缺點2:Cost和Error不一定有關係。
- HMM等的優點1:可以考慮output sequence的label的constraint,可以把這個constraint加到viterbi中,只窮舉符合constraint的sequence。
- HMM等的優點2:Cost is upper bound of error。
我們可以把左邊和右邊的方法加起來:
底層用RNN/LSTM,在外面用HMM/CRF/Structured Perceptron/SVM:
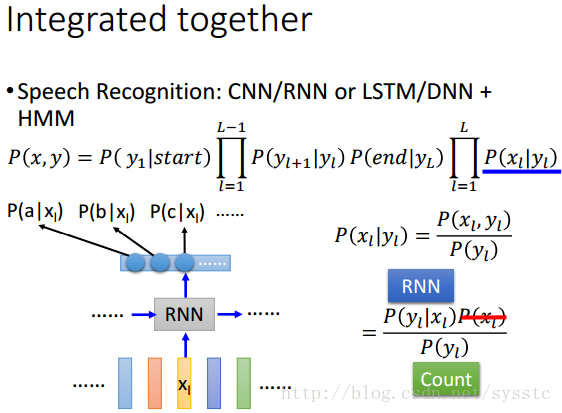
那麼如何把CNN/RNN或LSTM/DNN+HMM呢?
將emission probability用RNN取代掉,然後在做HMM。
我們要的是P(xi|yi),我們可以修改這個公式,P(yi|xi)就是RNN;P(yi)就是看training data中label出現的機率;那麼因為在HMM的Inference中我們是給定一個x,看哪一個y可以讓這個機率最大,所以x是給定的,所以P(xi)的值無論多少都不會影響到我們最終的結果。
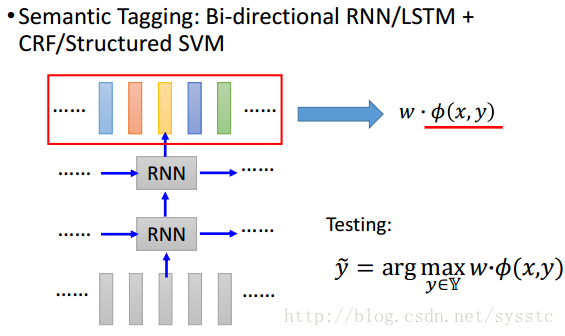
Bi-directional RNN/LSTM+CRF/Structured SVM相互結合
Concluding Remarks