
高次同餘筆記(一):baby-step-giant-step演算法
阿新 • • 發佈:2019-02-15
我們來看這個方程:
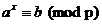
a,b,p為常數且在int內。、p是質數。
這個怎麼搞?
首先x的取值肯定在0到p-1之間。
暴搜?肯定超時啊。
優化暴搜?用meet-in-the-middle?
先來說說meet-in-the-middle怎麼做。
就是找一個點把[0,p-1]這個區間分成兩半(一般找中點),算出前一半塞到hash表裡面,再算後一半看看hash表裡面有沒有。
複雜度大概是上面的暴搜的根號。
其實這個思想是好的,它指導我們發現baby-step-giant-step。
先給出baby-step-giant-step演算法的步驟。
令m=ceil(sqrt(p)),把(a^0,0),(a^1,1),…,(a^(m-1),m-1)全部塞到hash表裡面。
然後令d=a^m,計算d^0,d^1,…,d^m,對於每一個d^i,有
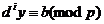
這個東西怎麼搞?
用exgcd啊!用exgcd求出來y,然後查詢hash表裡面有沒有y就行了。
如果有y,設對應的指數是k,那麼答案就是i*m+k。
如果跑完了都沒有,那就無解了。
再回顧這個演算法,為什麼叫baby-step-giant-step?
因為baby的步長為1,giant的步長為m,然後去湊答案。
這個是什麼思想?分塊!
把答案分成sqrt(p)塊,然後暴力列舉塊+解線性同餘方程驗證塊內有無滿足題意的解。
有時間再寫extend-baby-step-giant-step,這個演算法解決了p為合數的狀況。或者寫寫離散對數與原根,它可以解決另一種不同形式的高次同餘方程。
附POJ2417BSGS裸題程式碼(hash表亂寫的所以很慢)
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
ll a,b,p,hsh[70000][2];
bool ishsh[70000];
void insert(ll x,ll t)
{
ll p=x*12580%70000;
while(ishsh[p])p=(p+1)%70000;
ishsh[p]=1;
hsh[p][0]=x;
hsh[p][1]=t;
}
int