
簡要介紹弱監督學習
by 南大周志華
摘要
監督學習技術通過學習大量訓練資料來構建預測模型,其中每個訓練樣本都有其對應的真值輸出。儘管現有的技術已經取得了巨大的成功,但值得注意的是,由於資料標註過程的高成本,很多工很難獲得如全部真值標籤這樣的強監督資訊。因此,能夠使用弱監督的機器學習技術是可取的。本文綜述了弱監督學習的一些研究進展,主要關注三種弱監督型別:不完全監督,即只有一部分樣本有標籤;不確切監督,即訓練樣本只有粗粒度的標籤;以及不準確監督,即給定的標籤不一定總是真值。
關鍵詞:機器學習,弱監督學習,監督學習
1 概述
機器學習在多種任務中取得了巨大成功,尤其是在分類和迴歸等監督學習任務中。預測模型是從一個包含大量訓練樣本的訓練資料集中學習,其中每個樣本都對應一個事件或物件。一個訓練樣本由兩部分組成:一個描述事件/物件的特徵向量(或例項),以及一個表示真值輸出的標籤。在分類任務中,標籤代表訓練樣本所屬的類別;在迴歸任務中,標籤是樣本所對應的實數值。大部分成功的技術,例如深度學習【1】,都需要含有真值標籤的大規模訓練資料集;然而在很多工中,由於資料標註過程的高昂代價,很難獲得強監督資訊。因此,研究者十分希望機器學習技術能夠在弱監督前提下工作。
弱監督通常分為三種類型。第一種是不完全監督,即只有訓練資料集的一個(通常很小的)子集有標籤,其它資料則沒有標籤。在很多工中都存在這種情況。例如,在影象分類中,真值標籤是人工標註的;從網際網路上獲得大量的圖片很容易,然而由於人工標註的費用,只能標註其中一個小子集的影象。第二種是不確切監督,即只有粗粒度的標籤。又以影象分類任務為例。我們希望圖片中的每個物體都被標註;然而我們只有圖片級的標籤而沒有物體級的標籤。第三種是不準確監督,即給定的標籤並不總是真值。出現這種情況的原因有,標註者粗心或疲倦,或者一些影象本身就難以分類。
弱監督學習是一個總括性的術語,它涵蓋了試圖通過較弱的監督來構建預測模型的各種研究。在本文中,我們將會討論這一領域的一些進展,重點放在不完全、不確切和不準確的監督條件下進行的學習。我們會分別討論這三種情形,但是值得指出的是,在實際操作中,它們常常同時出現。為了簡便起見,在本文中我們考慮有兩個可交換的類別Y、N的二分類問題。形式化表達為,在強監督條件下,監督學習任務就是從訓練資料集D = {(x_1, y_1), …, (x_m, y_m)}中學習 f: X -> Y , 其中X是特徵空間,Y = {Y, N}, x_i 屬於X, y_i 屬於Y。
我們假設 (x_i, y_i) 是根據未知的獨立同分布D生成的。換言之,是 i.i.d. 樣本。
圖1示例了我們將在本文中討論的三種弱監督學習。
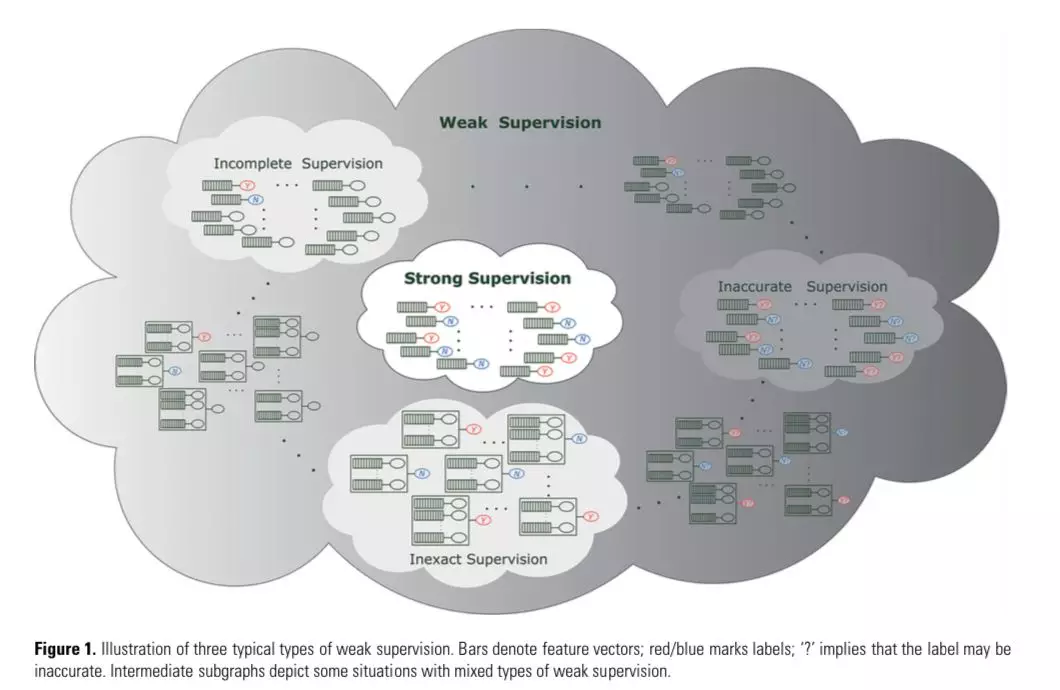
圖1:三種弱監督學習的示意圖。長方形表示特徵向量;紅色或藍色表示標籤;“?”表示標註可能是不準確的。中間的子圖表示了幾種弱監督的混合情形。
2 不完全監督
不完全監督是指訓練資料中只有一小部分資料有標籤,而大部分資料沒有標籤,且這一小部分有標籤的資料不足以訓練一個好的模型。形式化表達為,模型的任務是學習:f: X -> Y,訓練資料為:D = {(x_1, y_1), …, (x_l, y_l), x_{l+1}, …, x_m}, 即有l個數據有標籤(如y_i所示),u = m-l 個數據沒有標籤,其他條件與強監督學習(如摘要最後的定義)相同。為便於討論,我們將l個已經標註的資料記為「標註資料」,u個沒有標籤的資料稱為「未標註資料」。
有兩種主要的技術能夠實現此目的,即主動學習(active learning)【2】和半監督學習(semi-supervised learning)【3-5】。
主動學習假設有一個「神諭」(oracle),比如人類專家,可以向它查詢所選未標註資料的真值標籤。相比之下,半監督學習試圖在沒有人為干預的前提下,自動利用已標註資料、以及未標註資料來提升學習效能。有一種特殊的半監督學習,稱為直推式學習(transductive learning),它與(純)半監督學習之間的差別在於,對測試資料(訓練模型要預測的資料)的假設不同。直推式學習持有“封閉世界”的假設,即測試資料是事先給定的,且目標就是優化模型在測試資料上的效能;換句話說,未標註資料就是測試資料。純半監督學習持有“開放世界”的假設,即測試資料是未知的,且未標註資料不一定是測試資料。圖2直觀的表示了主動學習、(純)半監督學習、直推學習之間的區別。

圖2: 主動學習、(純)半監督學習以及直推學習。
2.1 有人為干預
主動學習【2】假設未標註資料的真值標籤可以向先知”查詢。簡單起見,假設標註成本只與查詢次數有關。那麼主動學習的目標就是最小化查詢次數,以使訓練一個好模型的成本最小。
給定少量標註資料以及大量未標註資料,主動學習傾向於選擇最有價值的未標註資料來查詢先知。衡量選擇的價值,有兩個廣泛使用的標準,即資訊量(informativeness)和代表性(representativeness)【6】。資訊量衡量一個未標註資料能夠在多大程度上降低統計模型的不確定性,而代表性衡量一個樣本在多大程度上能代表模型的輸入分佈。
不確定抽樣(uncertainty sampling)和投票詢問(query-by-committee)是基於資訊量的典型方法。前者訓練單個學習器,選擇學習器最不確信的樣本向先知詢問標籤資訊【7】。後者生成多個學習器,選擇各個學習器爭議最大的樣本向先知詢問標籤資訊【8,9】。基於代表性的模型通常的目標是用聚類方法來挖掘未標註資料的叢集結構【10,11】。
基於資訊量的方法,主要缺點是為了建立選擇查詢樣本所需的初始模型,而嚴重依賴於標註資料,並且當標註樣本較少時,其效能通常不穩定。基於代表性的方法,主要缺點在於其效能嚴重依賴於由未標註資料控制的的聚類結果,當標註資料較少時尤其如此。因此,幾種最近的主動學習方法嘗試同時利用資訊量和代表性度量【6,12】。
關於主動學習有很多理論性的研究。例如,已經證明對於可實現(realizable)情況(假設資料在假設的空間中完全可分),隨著樣本複雜性的增加,主動學習的效能可以獲得指數提升【13,14】。對於不可實現(non-realizable)的情況(即由於噪聲的存在,以致資料在任何假設下都不完全可分),在沒有對噪聲模型的先驗假設時,主動學習的下确界相當於被動學習的上確界,換句話說,主動學習並不是非常有用。當假設噪聲為Tsybakov噪聲模型時,我們可以證明,在噪聲有界的條件下,主動學習的效能可呈指數級提升【16,17】;如果能夠挖掘資料的一些特定性質,像多視角結構(multi-view structure),那麼即使在不對噪聲進行限制的情況下,其效能也能呈指數級提升【18】。換句話說,只要設計得巧妙,主動學習在解決困難問題時仍然有用。
2.2 無人為干預
半監督學習【3-5】是指在不詢問人類專家的條件下挖掘未標註資料。為什麼未標註資料對於構建預測模型也會有用?做一個簡單的解釋【19】,假設資料來自一個由n個高斯分佈混合的高斯混合模型,也就是說:f(x | \theta) = \sum_{j=1}^n \alpha_j f(x | \theta_j) (1)其中\alpha_j為混合係數,\sum_{j=1}^n \alpha_j = 1 並且 \theta = {\theta_j} 是模型引數。在這種情況下,標籤y_i可以看作一個隨機變數,其分佈 P(y_i | x_i, g_i)由混合成分g_i和特徵向量x_i決定。最大化後驗概率有:h(x) = argmax_c \sum_{j=1}^n P(y_i = c | g_i = j, x_i) \times P(g_i = j | x_i) (2)。其中:P(g_i = j | x_i) = \frac{\alpha_j f(x_i | \theta_j)} {\sum_{k=1}^n \alpha_k f(x_i | \theta_k)} (3)
h(x)可以通過用訓練資料估計 P(y_i = c | g_i = j, x_i) 和 P(g_i = j | x_i) 來求得。很明顯只有第一項需要標籤資訊。因此,未標註資料可以用來估計提升對第二項的估計,從而提升學習模型的效能。
圖3: 未標註資料的作用。
圖3給出了一個直觀的解釋。如果我們只能根據唯一的正負樣本點來預測,那我們就只能隨機猜測,因為測試樣本恰好落在了兩個標註樣本的中間位置;如果我們能夠觀測到一些未標註資料,例如圖中的灰色樣本點,我們就能以較高的置信度判定測試樣本為正樣本。在此處,儘管未標註樣本沒有明確的標籤資訊,它們卻隱晦地包含了一些資料分佈的資訊,而這對於預測模型是有用的。
實際上,在半監督學習中有兩個基本假設,即聚類假設(cluster assumption)和流形假設(manifold assumption);兩個假設都是關於資料分佈的。前者假設資料具有內在的聚類結構,因此,落入同一個聚類的樣本類別相同。後者假設資料分佈在一個流形上,因此,相近的樣本具有相似的預測。兩個假設的本質都是相似的資料輸入應該有相似的輸出,而未標註資料有助於揭示出樣本點之間的相似性。
半監督學習有四種主要方法,即生成式方法(generative methods),基於圖的方法(graph-based methods),低密度分割法(low-density separation methods)以及基於分歧的方法(disagreement methods)。
生成式方法【19,20】假設標註資料和未標註資料都由一個固有的模型生成。因此,未標註資料的標籤可以看作是模型引數的缺失,並可以通過EM演算法(期望-最大化演算法)等方法進行估計【21】。這類方法隨著為擬合數據而選用的不同生成模型而有所差別。為了達到好的效能,通常需要相關領域的知識來選擇合適的生成模型。也有一些將生成模型和判別模型的優點結合起來的嘗試【22】。
基於圖的方法構建一個圖,其節點對應訓練樣本,其邊對應樣本之間的關係(通常是某種相似度或距離),而後依據某些準則將標註資訊在圖上進行擴散;例如標籤可以在最小分割圖演算法得到的不同子圖內傳播【23】。很明顯,模型的效能取決於圖是如何構建的【26-28】。值得注意的是,對於m個樣本點,這種方法通常需要O(m^2)儲存空間和O(m^3)計算時間複雜度。因此,這種方法嚴重受制於問題的規模;而且由於難以在不重建圖的情況下增加新的節點,所以這種方法天生難以遷移。
圖4: SVM和S3VM的不同分類介面,SVM只考慮標註資料(“+/-”點),S3VM既考慮標註資料也考慮未標註資料(灰色點)。
低密度分割法強制分類邊界穿過輸入空間的低密度區域。最著名的代表就是S3VMs(半監督支援向量機)【29-31】。圖4示意了一般的監督SVM和S3VM的區別。很明顯,S3VM試圖在保持所有標註樣本分類正確的情況下,建立一個穿過低密度區域的分類介面。這一目標可以通過用不同方法給未標註資料分配標籤來達成,而這往往會造成優化問題很複雜。因此,在這個方向很多的研究都致力於開發高效的優化方法。
基於分歧的方法【5,32,33】生成多個學習器,並讓它們合作來挖掘未標註資料,其中不同學習器之間的分歧是讓學習過程持續進行的關鍵。最為著名的典型方法——聯合訓練(co-traing),通過從兩個不同的特徵集合(或視角)訓練得到的兩個學習器來運作。在每個迴圈中,每個學習器選擇其預測置信度最高的未標註樣本,並將其預測作為樣本的偽標籤來訓練另一個學習器。這種方法可以通過學習器整合來得到很大提升【34,35】。值得注意的是,基於分歧的方法提供了一種將半監督學習和主動學習自然地結合在一起的方式:它不僅可以讓學習器相互學習,對於兩個模型都不太確定或者都很確定但相互矛盾的未標註樣本,還可以被選定詢問“先知”。
值得指出的是,儘管我們期望通過利用未標註資料來提升學習效能,但是在一些情況下,在經過半監督學習之後效能反而會下降。這個問題已經被提出並且研究了很多年【36】,然而直到最近才有一些實質性的進展被報道出來【37】。我們現在知道,對未標註資料的利用自然會要在多個模型中進行選擇,而不恰當的選擇可能會導致較差的效能。讓半監督學習“更安全”的基本策略是優化最差情況下的效能,也許可以通過模型整合機制來實現。
關於半監督學習有大量的理論研究【4】,有些甚至要早於“半監督學習”這個詞語的出現【38】。實際上最近有一篇研究,透徹研究了基於分歧的方法【39】。
3 不確切監督
不確切監督是指在某種情況下,我們有一些監督資訊,但是並不像我們所期望的那樣精確。一個典型的情況是我們只有粗粒度的標註資訊。例如,在藥物活性預測中【40】,目標是建立一個模型學習已知分子的知識,來預測一種新的分子是否能夠用於某種特殊藥物的製造。一種分子可能有很多低能量的形態,這種分子能否用於製作該藥物取決於這種分子是否有一些特殊形態。然而,即使對於已知的分子,人類專家也只知道其是否合格,而並不知道哪種特定形態是決定性的。
形式化表達為,這一任務是學習 f: X -> Y ,其訓練集為 D = {(X_1, y_1), …, (X_m, y_m)},其中 X_i = {x_{I, 1}, …, x_{I, m_i}}, X_i屬於X,且被稱為一個包(bag),x_{i, j}屬於X,是一個樣本(j屬於{1, …, m_i})。m_i是X_i中的樣本個數,y_i屬於Y = {Y, N}。當存在x_{i, p}是正樣本時,X_i就是一個正包(positive bag),其中p是未知的且p屬於{1, …, m_i}。模型的目標就是預測未知包的標籤。這被稱為多示例學習(multi-instance learning)【40,41】。
對於多示例學習,有很多有效的演算法。實際上,幾乎所有的監督學習演算法都有其對應的多示例版本。大多數演算法都試圖調整單例項監督學習演算法,使其適配多示例表示,其主要方法是將對示例區分轉變到對包的區分上來【42】;其他一些演算法試圖通過表示轉換,調整多例項表示使其適配單例項演算法【43,44】。還有一種分類方式,將演算法分為:示例空間模型,即將示例級的反饋進行融合;包空間模型,即將包做為一個整體;以及嵌入空間模型,即學習是在一個嵌入特徵空間中進行的。值得注意的是,示例通常被視為獨立同分布的樣本;然而【46】表明,儘管包可假設為獨立同分布的,但是多示例學習中的樣本不應被假設為相互獨立的。基於這一觀點,一些有效的演算法被提了出來【47】。
多示例學習已經成功應用於多種任務,例如影象分類、檢索、註釋【48-50】,文字分類【51,52】,垃圾郵件檢測【53】,醫療診斷【54】,人臉、目標檢測【55,56】,目標類別發現【57】,目標跟蹤【58】等等。在這些任務中,我們可以很自然地將一個真實的目標(例如一張圖片或一個文字文件)看作一個包;然而,不同於藥物活性預測中包裡有天然的示例(即分子的不同形態),這裡的示例需要生成。一個包生成器明確如何生成示例來組成一個包。通常情況下,從一幅影象中提取的很多小影象塊就作為可以這個影象的示例,而章節、段落甚至是句子可以作為一個文字文件的示例。儘管包生成器對於學習效果有重要的影響,但直到最近才出現關於影象包生成器的全面研究【59】;研究表明一些簡單的密集取樣包生成器要比複雜的生成器效能更好。圖5顯示了兩個簡單而有效的影象包生成器。
圖5: 影象包生成器。假設每張圖片的尺寸為8*8個畫素,每個小塊的尺寸為2*2個畫素。單塊(Single Blob, SB)以無重疊地滑動的方式,會給一個圖片生成16個例項,即每個例項包含4個畫素。領域單塊(SBN)以有重疊地滑動的方式,則會給每一個圖片生成9個例項,即每個例項包含20個畫素。
多示例學習的原始目標是預測未知包的標籤;但有研究試圖識別使得正包為正的關鍵示例(key instance)【31,60】。這對於有些任務是很有用的,例如在沒有精細標註的影象資料中尋找感興趣的區域。值得注意的是,標準的多示例學習【40】假設每個正包都必須包含一個關鍵示例,而有的研究則假設沒有關鍵示例,每個示例都對包的標籤有貢獻【61,62】,或甚至假設有多個概念,僅當包中示例同時滿足所有概念時才是正包【63】。在【41】中可以找到更多變體。
早期的理論研究結果【64-66】表明多示例學習很難應對異質(heterogeneous)案例,即包中的示例由不同的分類規則進行分類,而在同質(homogeneous)案例是可學習的,即包所有示例按照同一規則進行分類。幸運的是,幾乎所有實際的多示例任務都屬於同質案例。他們假設包中示例相互獨立。包中示例沒有相互獨立假設的分析更具挑戰性,也出現得晚得多,這些分析表明在同質性類中時,至少在一些情況下包之間的任意分佈都是可學習的【67】。然而,與演算法和應用研究的繁榮相比,多示例學習的理論成果非常少,因為這種分析實在是太困難了。
4 不準確監督
不準確監督關注監督資訊不總是真值的情形;換句話說,有些標籤資訊可能是錯誤的。其形式化表示與概述結尾部分幾乎完全相同,除了訓練資料集中的y_i可能是錯誤的。
一個典型的情況是在標籤有噪聲的條件下學習【68】。已有很多相關理論研究【69-71】,這些研究大多都假設存在隨機型別的噪聲,即標籤受制於隨機噪聲。在實際中,一個基本的想法是識別潛在的誤分類樣本【72】,而後進行修正。例如,資料編輯(data-editing)方法【73】構建了一個相對鄰域圖,其中的每個節點對應一個訓練樣本,連線標籤不同的兩個節點的邊稱為一個切邊(cut edge)。而後衡量切邊權重的統計資料,直覺上,示例連線的切邊越多則越可疑。可以刪除或者重新標註可疑示例,如圖6所示。值得指出的是,這種方法通常依賴近鄰資訊,因此,這類方法在高維特徵空間並不十分可靠,因為當資料稀疏的時候,領域識別常常並不可靠。
圖6: 識別並刪除或重新標註可疑點。
一個最近出現的不準確監督的情景發生在眾包模式中(crowdsourcing)【74】,即一個將工作外包給個人的流行模式。對機器學習而言,用眾包模式為訓練資料收集標籤是一種經濟的方式。具體而言,未標註資料被外包給大量的工人去標註。在著名的眾包系統 Amazon Mechanical Turk( AMT)上使用者可以提交一個任務,例如標註影象有樹還是沒有樹,並向標註工人支付少量的報酬。這些工人通常來自大社會,他們每個人都會執行多種多樣的任務。他們通常是相互獨立的,報酬不高,並根據自己的判斷提供標籤。在工人之中,一些可能比另一些更可靠;然而使用者通常不會事先知道,因為工人的身份是保密的。還有可能存在“垃圾製造者”,他們幾乎是隨機地提供標籤(例如一個機器人冒充人類來獲取報酬),或者“反抗者”,他們故意提供錯誤答案。除此之外,有些任務對於很多工人來說可能太困難了。因此,用從眾包返回的不準確的監督資訊進行學習,並保持學習到的效能,是有意義的。
很多研究試圖從眾包標籤中推理出真值標籤。有整合方法【35】的理論支援的多票數策略在實際中得到了廣泛應用,並有不錯的效能【75,76】,因此常常作為基線標準。如果工人的質量和任務的難度可以建模,那麼我們就可期望實現更好的效能,其典型的方法是在不同的任務中給工人不同的權重。為此,一些方法試圖建立概率模型,而後使用EM演算法來進行估計【77,78】。最小最大化熵準則也在一些方法中得到使用【35】。垃圾提供者可以在概率模型中被剔除【79】。最近有研究給出了剔除低品質工人的一般理論條件【80】。
對機器學習而言,眾包通常用來收集標籤,而從這些資料中學習得到的模型的效能要比標籤的質量更為重要。有很多關於在weak teachers或眾包標籤學習的研究【81,82】,這與用噪聲標籤學習很相近(在本節開頭部分有介紹);其中的區別在於,對於眾包系統而言,我們很容易重複提取某個示例的眾包標籤。因此,在眾包學習中考慮節約成本的效果是很重要的,【83】給出了一個最小化的眾包標籤數量的上界,也就是說有效眾包學習的最小化成本。很多研究工作致力於任務分配和預算分配,試圖在精度和標註花費之間取得平衡。為此,離線的不能自適應的任務分配機制【84,85】,以及線上的自適應的任務分配機制【86,87】都有理論支撐。值得注意的是,大多數研究都採用了Dawid-Skene模型,它假設不同任務的潛在成本都是相同的,而很少研究更復雜的成本設定。
設計一個有效的眾包協議也十分重要。在【89】中,提供了不確定選項,這樣工人在不確定的時候不會被強制要求給出標籤;這個選項在理論上能夠提升標籤的可靠性【90】。在【91】中,引入了一個“雙倍或沒有”的刺激相容機制,以確保工人在自已確信的基礎上進行誠實的回答;假設所有的工人都想最大化他們的期望報酬,該機制可以剔除垃圾提供者。
5 結論
在帶有真值標籤的大量訓練樣本的強監督條件下,監督學習技術已經取得了巨大的成功。然而,在真實的任務中,收集監督資訊往往代價高昂,因此探索弱監督學習通常是更好的方式。
本文聚焦於三種典型的弱監督學習:不完全、不確切和不準確監督。儘管三者可以分開討論,但在實際中它們常常同時出現,如圖1所示。當然也有針對“混合”情況的相關研究【52,92,93】。此外,還有一些其他型別的弱監督。例如,延時監督也可以視為弱監督,它主要出現在增強學習環境中【94】。由於篇幅限制,本文與其說是一個全面的總結回顧,不如說只是一個文獻的索引。對於一些細節感興趣的讀者可以閱讀參考文獻中的相關文章。值得注意的是,越來越多的研究者開始關注弱監督學習,例如部分監督學習(partially supervised learning),主要關注不完全監督的學習【95】,【96,97】,同時還有一些其他關於弱監督的討論。
為了便於討論,本文只關注了二分類問題,而大多數討論經稍事修改後就可推廣至多類問題或迴歸問題。在多類分類任務中可能出現更復雜的情況【98】。在考慮多標籤學習(multi-label learning)【99】時情況可能更為複雜,此時每個樣本可能被同時賦予多個標籤。用不完全監督舉個例子:除了標註示例和未標註示例,多標籤任務還會遇到部分標註示例,也就是說一個訓練示例只給出了一部分標籤【100】。即使只考慮標註資料和未標註資料,這種情況也要比單標籤有更多選項,例如在主動學習中,對於選定的未標註示例,既可以詢問示例的所有標籤【101】,也可以詢問某一個特定標籤【102】,還可以給一對標籤的相關排序【103】。儘管如此,不論是何種資料、何種任務,弱監督學習正在變得越來越重要。
參考文獻:
Goodfellow I, Bengio Y and Courville A. Deep Learning. Cambridge: MIT Press, 2016.
Settles B. Active learning literature survey. Technical Re- port 1648. Department of Computer Sciences, University of Wisconsin at Madison, Wisconsin, WI, 2010 [ http://pages. cs.wisc.edu/∼bsettles/pub/settles.activelearning.pdf].
Chapelle O, Scho ̈lkopf B and Zien A (eds). Semi-Supervised Learning. Cambridge: MIT Press, 2006.
Zhu X. Semi-supervised learning literature survey. Technical Report 1530. Department of Computer Sciences, University of Wisconsin at Madison, Madison, WI, 2008 [ http://www.cs. wisc.edu/∼jerryzhu/pub/ssl ̇survey.pdf].
Zhou Z-H and Li M. Semi-supervised learning by disagreement. Knowl Inform Syst 2010; 24: 415–39.
Huang SJ, Jin R and Zhou ZH. Active learning by querying informative and representative examples. IEEE Trans Pattern Anal Mach Intell 2014; 36: 1936–49.
Lewis D and Gale W. A sequential algorithm for training text classi ers. In 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 1994; 3–12.
Seung H, Opper M and Sompolinsky H. Query by committee. In 5th ACM Workshop on Computational Learning Theory, Pitts- burgh, PA, 1992; 287–94.
Abe N and Mamitsuka H. Query learning strategies using boosting and bagging. In 15th International Conference on Ma- chine Learning, Madison, WI, 1998; 1–9.
Nguyen HT and Smeulders AWM. Active learning using pre- clustering. In 21st International Conference on Machine Learn- ing, Banff, Canada, 2004; 623–30.
Dasgupta S and Hsu D. Hierarchical sampling for active learn- ing. In 25th International Conference on Machine Learning, Helsinki, Finland, 2008; 208–15.
Wang Z and Ye J. Querying discriminative and representative samples for batch mode active learning. In 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, 2013; 158–66.
Dasgupta S, Kalai AT and Monteleoni C. Analysis of perceptron-based active learning. In 28th Conference on Learn- ing Theory, Paris, France, 2005; 249–63.
Dasgupta S. Analysis of a greedy active learning strategy. In Advances in Neural Information Processing Systems 17, Cambridge, MA: MIT Press, 2005; 337–44.
Ka ̈a ̈ria ̈inen M. Active learning in the non-realizable case. In 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 2006; 63–77.
Balcan MF, Broder AZ and Zhang T. Margin based active learn- ing. In 20th Annual Conference on Learning Theory, San Diego, CA, 2007; 35–50.
Hanneke S. Adaptive rates of convergence in active learning. In 22nd Conference on Learning Theory, Montreal, Canada, 2009.
Wang W and Zhou ZH. Multi-view active learning in the non-realizable case. In Advances in Neural Information Processing Systems 23, Cambridge, MA: MIT Press, 2010; 2388–96.
Miller DJ and Uyar HS. A mixture of experts classi er with learning based on both labelled and unlabelled data. In Advances in Neural Information Processing Systems 9, Cam- bridge, MA: MIT Press, 1997; 571–7.
Nigam K, McCallum AK and Thrun S et al. Text classi cation from labeled and unlabeled documents using EM. Mach Learn 2000; 39: 103–34.
Dempster AP, Laird NM and Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J Roy Stat Soc B Stat Meth 1977; 39: 1–38.
Fujino A, Ueda N and Saito K. A hybrid genera- tive/discriminative approach to semi-supervised classier design. In 20th National Conference on Articial Intelligence, Pittsburgh, PA, 2005; 764–9.
Blum A and Chawla S. Learning from labeled and unlabeled data using graph mincuts. In ICML, 2001; 19–26.
Zhu X, Ghahramani Z and Lafferty J. Semi-supervised learn- ing using Gaussian elds and harmonic functions. In 20th International Conference on Machine Learning, Washington, DC, 2003; 912–9.
Zhou D, Bousquet O and Lal TN et al. Learning with local and global consistency. In Advances in Neural Information Processing Systems 16, Cambridge, MA: MIT Press, 2004; 321–8.
Carreira-Perpinan MA and Zemel RS. Proximity graphs for clustering and manifold learning. In Advances in Neural Information Processing Systems 17, Cambridge, MA: MIT Press, 2005; 225–32.
Wang F and Zhang C. Label propagation through linear neighborhoods. In 23rd International Conference on Machine Learning, Pittsburgh, PA, 2006; 985–92.
Hein M and Maier M. Manifold denoising. In Advances in Neural Information Processing Systems 19, Cambridge, MA: MIT Press, 2007; pp. 561–8.
Joachims T. Transductive inference for text classi cation using support vector machines. In 16th International Conference on Machine Learning, Bled, Slovenia, 1999; 200–9.
Chapelle O and Zien A. Semi-supervised learning by low density separation. In 10th International Workshop on Articial Intelligence and Statistics, Barbados, 2005; 57–64.
Li YF, Tsang IW and Kwok JT et al. Convex and scalable weakly labeled SVMs. J Mach Learn Res 2013; 14: 2151–88.
Blum A and Mitchell T. Combining labeled and unlabeled data with co- training. In 11th Conference on Computational Learning Theory, Madison, WI, 1998; 92–100.
Zhou Z-H and Li M. Tri-training: exploiting unlabeled data using three classiers. IEEE Trans Knowl Data Eng 2005; 17: 1529–41.
Zhou Z-H. When semi-supervised learning meets ensemble learning. In 8th International Workshop on Multiple Classi er Systems, Reykjavik, Iceland, 2009; 529–38.
Zhou Z-H. Ensemble Methods: Foundations and Algorithms. Boca Raton: CRC Press, 2012.
Cozman FG and Cohen I. Unlabeled data can degrade classi cation performance of generative classi ers. In 15th International Conference of the Florida Arti cial Intelligence Research Society, Pensacola, FL, 2002; 327–31.
Li YF and Zhou ZH. Towards making unlabeled data never hurt. IEEE Trans Pattern Anal Mach Intell 2015; 37: 175–88.
Castelli V and Cover TM. On the exponential value of labeled samples. Pattern Recogn Lett 1995; 16: 105–11.
Wang W and Zhou ZH. Theoretical foundation of co-training and disagreement-based algorithms. arXiv:1708.04403, 2017.
Dietterich TG, Lathrop RH and Lozano-Pe ́rez T. Solving the multiple-instance problem with axis-parallel rectangles. Artif Intell 1997; 89: 31–71.
Foulds J and Frank E. A review of multi-instance learning assumptions. Knowl Eng Rev 2010; 25: 1–25.
Zhou Z-H. Multi-instance learning from supervised view. J Comput Sci Technol 2006; 21: 800–9.
Zhou Z-H and Zhang M-L. Solving multi-instance problems with classi er ensemble based on constructive clustering. Knowl Inform Syst 2007; 11: 155–70.
Wei X-S, Wu J and Zhou Z-H Scalable algorithms for multi-instance learning. IEEE Trans Neural Network Learn Syst 2017; 28:975–87.
Amores J. Multiple instance classi cation: review, taxonomy and comparative study. Artif Intell 2013; 201: 81–105.
Zhou Z-H and Xu J-M. On the relation between multi-instance learning and semi-supervised learning. In 24th International Conference on Machine Learning, Corvallis, OR, 2007; 1167–74.
Zhou Z-H, Sun Y-Y and Li Y-F. Multi-instance learning by treating instances as non-i.i.d. samples. In 26th International Conference on Machine Learning, Montreal, Canada, 2009; 1249–56.
Chen Y and Wang JZ. Image categorization by learning and reasoning with regions. J Mach Learn Res 2004; 5: 913–39.
Zhang Q, Yu W and Goldman SA et al. Content-based image retrieval using multiple-instance learning. In 19th International Conference on Machine Learning, Sydney, Australia, 2002; 682–9.
Tang JH, Li HJ and Qi GJ et al. Image annotation by graph-based inference with integrated multiple/single instance representations. IEEE Trans Multimed 2010; 12: 131–41.
Andrews S, Tsochantaridis I and Hofmann T. Support vector machines for multiple-instance learning. In Advances in Neural Information Processing Systems 15, Cambridge, MA: MIT Press, 2003; 561–8.
Settles B, Craven M and Ray S. Multiple-instance active learning. In Advances in Neural Information Processing Systems 20, Cambridge, MA: MIT Press, 2008; 1289–96.
Jorgensen Z, Zhou Y and Inge M. A multiple instance learning strategy for combating good word attacks on spam lters. J Mach Learn Res 2008; 8: 993– 1019.
Fung G, Dundar M and Krishnappuram B et al. Multiple instance learning for computer aided diagnosis. In Advances in Neural Information Processing Sys- tems 19, Cambridge, MA: MIT Press, 2007; 425–32.
Viola P, Platt J and Zhang C. Multiple instance boosting for object detection. In Advances in Neural Information Processing Systems 18, Cambridge, MA: MIT Press, 2006; 1419–26.
Felzenszwalb PF, Girshick RB and McAllester D et al. Object detection with discriminatively trained part-based models. IEEE Trans Pattern Anal Mach Intell 2010; 32: 1627–45.
Zhu J-Y, Wu J and Xu Y et al. Unsupervised object class discovery via saliency- guided multiple class learning. IEEE Trans Pattern Anal Mach Intell 2015; 37: 862–75.
Babenko B, Yang MH and Belongie S. Robust object tracking with online multi- ple instance learning. IEEE Trans Pattern Anal Mach Intell 2011; 33: 1619–32.
Wei X-S and Zhou Z-H. An empirical study on image bag generators for multi-instance learning. Mach Learn 2016; 105:155–98.
Liu G, Wu J and Zhou ZH. Key instance detection in multi-instance learning. In 4th Asian Conference on Machine Learning, Singapore, 2012; 253–68.
Xu X and Frank E. Logistic regression and boosting for labeled bags of instances. In 8th Paci c-Asia Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 2004; 272–81.
Chen Y, Bi J and Wang JZ. MILES: multiple-instance learning via embedded instance selection. IEEE Trans Pattern Anal Mach Intell 2006; 28: 1931–47.
Weidmann N, Frank E and Pfahringer B. A two-level learning method for gen- eralized multi-instance problem. In 14th European Conference on Machine Learning, Cavtat-Dubrovnik, Croatia, 2003; 468–79.
Long PM and Tan L. PAC learning axis-aligned rectangles with respect to product distributions from multiple-instance examples. Mach Learn 1998; 30: 7–21.
Auer P, Long PM and Srinivasan A. Approximating hyper-rectangles: learning and pseudo-random sets. J Comput Syst Sci 1998; 57: 376–88.
Blum A and Kalai A. A note on learning from multiple-instance examples. Mach Learn 1998; 30: 23–9.
Sabato S and Tishby N. Homogenous multi-instance learning with arbitrary dependence. In 22nd Conference on Learning Theory, Montreal, Canada, 2009.
Fre ́nay B and Verleysen M. Classi cation in the presence of label noise: a survey. IEEE Trans Neural Network Learn Syst 2014; 25: 845–69.
Angluin D and Laird P. Learning from noisy examples. Mach Learn 1988; 2: 343–70.
Blum A, Kalai A and Wasserman H. Noise-tolerant learning, the parity problem, and the statistical query model. J ACM 2003; 50: 506–19.
Gao W, Wang L and Li YF et al. Risk minimization in the presence of label noise. In 30th AAAI Conference on Arti cial Intelligence, Phoenix, AZ, 2016; 1575–81.
Brodley CE and Friedl MA. Identifying mislabeled training data. J Artif Intell Res 1999; 11: 131–67.
Muhlenbach F, Lallich S and Zighed DA. Identifying and handling mislabelled instances. J Intell Inform Syst 2004; 22: 89–109.
Brabham DC. Crowdsourcing as a model for problem solving: an introduction and cases. Convergence 2008; 14: 75–90.
Sheng VS, Provost FJ and Ipeirotis PG. Get another label? Improving data 8. quality and data mining using multiple, noisy labelers. In 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Ve- gas, NV, 2008; 614–22.
Snow R, O’Connor B and Jurafsky D et al. Cheap and fast - but is it good? Evaluating non-expert annotations for natural language tasks. In 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, 2008; 254–63.
Raykar VC, Yu S and Zhao LH et al. Learning from crowds. J Mach Learn Res 2010; 11: 1297–322.
Whitehill J, Ruvolo P and Wu T et al. Whose vote should count more: opti- mal integration of labels from labelers of unknown expertise. In Advances in Neural Information Processing Systems 22, Cambridge, MA: MIT Press, 2009; 2035–43.
Raykar VC and Yu S. Eliminating spammers and ranking annotators for crowd- sourced labeling tasks. J Mach Learn Res 2012; 13: 491–518.
Wang W and Zhou ZH. Crowdsourcing label quality: a theoretical analysis. Sci China Inform Sci 2015; 58: 1–12.
Dekel O and Shamir O. Good learners for evil teachers. In 26th International Conference on Machine Learning, Montreal, Canada, 2009; 233–40.
Urner R, Ben-David S and Shamir O. Learning from weak teachers. In 15th International Conference on Arti cial Intelligence and Statistics, La Palma, Canary Islands, 2012; 1252–60.
Wang L and Zhou ZH. Cost-saving effect of crowdsourcing learning. In 25th International Joint Conference on Arti cial Intelligence, New York, NY, 2016; 2111–7.
Karger DR, Sewoong O and Devavrat S. Iterative learning for reliable crowd- sourcing systems. In Advances in Neural Information Processing Systems 24, Cambridge, MA: MIT Press, 2011; 1953–61.
Tran-Thanh L, Venanzi M and Rogers A et al. Ef cient budget allocation with accuracy guarantees for crowdsourcing classi cation tasks. In 12th Interna- tional conference on Autonomous Agents and Multi-Agent Systems, Saint Paul, MN, 2013; 901–8.
Ho CJ, Jabbari S and Vaughan JW. Adaptive task assignment for crowd- sourced classi cation. In 30th International Conference on Machine Learning, Atlanta, GA, 2013; 534–42.
Chen X, Lin Q and Zhou D. Optimistic knowledge gradient policy for opti- mal budget allocation in crowdsourcing. In 30th International Conference on Machine Learning, Atlanta, GA, 2013; 64–72.
Dawid AP and Skene AM. Maximum likelihood estimation of observer error- rates using the EM algorithm. J Roy Stat Soc C Appl Stat 1979; 28: 20– 8
Zhong J, Tang K and Zhou Z-H. Active learning from crowds with unsure op- tion. In 24th International Joint Conference on Arti cial Intelligence, Buenos Aires, Argentina, 2015; 1061–7.
Ding YX and Zhou ZH. Crowdsourcing with unsure opinion. arXiv:1609.00292, 2016.
Shah NB and Zhou D. Double or nothing: multiplicative incentive mechanisms for crowdsourcing. In Advances in Neural Information Processing Systems 28, Cambridge, MA: MIT Press, 2015; 1–9.
Rahmani R and Goldman SA. MISSL: multiple-instance semi-supervised learn- ing. In 23rd International Conference on Machine Learning, Pittsburgh, PA, 2006; 705–12.
Yan Y, Rosales R and Fung G et al. Active learning from crowds. In 28th Inter- national Conference on Machine Learning, Bellevue, WA, 2011; 1161–8.
Sutton RS and Barto AG. Reinforcement Learning: An Introduction. Cambridge: MIT Press, 1998.
Schwenker F and Trentin E. Partially supervised learning for pattern recognition. Pattern Recogn Lett 2014; 37: 1–3.
Garcia-Garcia D and Williamson RC. Degrees of supervision. In Advances in Neural Information Processing Systems 17, Cambridge, MA: MIT Press Work- shops, 2011.
Herna ́ ndez-Gonza ́ lez J, Inza I and Lozano JA. Weak supervision and other non-standard classification problems: a taxonomy. Pattern Recogn Lett 2016; 69: 49–55.
KunchevaLI,Rod ́ıguezJJandJacksonAS.Restrictedsetclassi cation:who is there? Pattern Recogn 2017; 63:158–70.
Zhang M-L and Zhou Z-H. A review on multi-label learning algorithms. IEEE Trans Knowl Data Eng 2014; 26: 1819–37.
Sun YY, Zhang Y and Zhou ZH. Multi-label learning with weak label. In 24th AAAI Conference on Arti cial Intelligence, Atlanta, GA, 2010; 593–8.
Li X and Guo Y. Active learning with multi-label SVM classi cation. In 23rd International Joint Conference on Arti cial Intelligence, Beijing, China, 2013; 1479–85.
Qi GJ, Hua XS and Rui Y et al. Two-dimensional active learning for image classi cation. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Anchorage, AK, 2008.
Huang SJ, Chen S and Zhou ZH. Multi-label active learning: query type matters. In 24th International Joint Conference on Arti cial Intelligence, Buenos Aires, Argentina, 2015; 946–52.