
presto架構及其原理
阿新 • • 發佈:2019-02-15
resto 是 Facebook 推出的一個基於Java開發的大資料分散式 SQL 查詢引擎,可對從數 G 到數 P 的大資料進行互動式的查詢,查詢的速度達到商業資料倉庫的級別,據稱該引擎的效能是 Hive 的 10 倍以上。Presto 可以查詢包括 Hive、Cassandra 甚至是一些商業的資料儲存產品,單個 Presto 查詢可合併來自多個數據源的資料進行統一分析。Presto 的目標是在可期望的響應時間內返回查詢結果,Facebook 在內部多個數據儲存中使用
Presto 互動式查詢,包括 300PB 的資料倉庫,超過 1000 個 Facebook 員工每天在使用 Presto 執行超過 3 萬個查詢,每天掃描超過 1PB 的資料。
目錄:
- presto架構
- presto低延遲原理
- presto儲存外掛
- presto執行過程
- presto引擎對比
Presto架構

- Presto查詢引擎是一個Master-Slave的架構,由下面三部分組成:
- 一個Coordinator節點
- 一個Discovery Server節點
- 多個Worker節點
- Coordinator: 負責解析SQL語句,生成執行計劃,分發執行任務給Worker節點執行
- Discovery Server: 通常內嵌於Coordinator節點中
- Worker節點: 負責實際執行查詢任務,負責與HDFS互動讀取資料
- Worker節點啟動後向Discovery Server服務註冊,Coordinator從Discovery Server獲得可以正常工作的Worker節點。如果配置了Hive Connector,需要配置一個Hive MetaStore服務為Presto提供Hive元資訊
- 更形象架構圖如下:

Presto低延遲原理
- 完全基於記憶體的平行計算
- 流水線式計算作業
- 本地化計算
- 動態編譯執行計劃
- GC控制
Presto儲存外掛
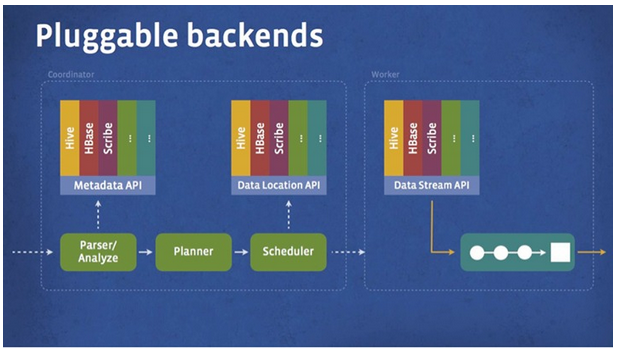
- Presto設計了一個簡單的資料儲存的抽象層, 來滿足在不同資料儲存系統之上都可以使用SQL進行查詢。
- 儲存外掛(聯結器,connector)只需要提供實現以下操作的介面, 包括對元資料(metadata)的提取,獲得資料儲存的位置,獲取資料本身的操作等。
- 除了我們主要使用的Hive/HDFS後臺系統之外, 我們也開發了一些連線其他系統的Presto 聯結器,包括HBase,Scribe和定製開發的系統
- 外掛結構圖如下:
presto執行過程
- 執行過程示意圖:
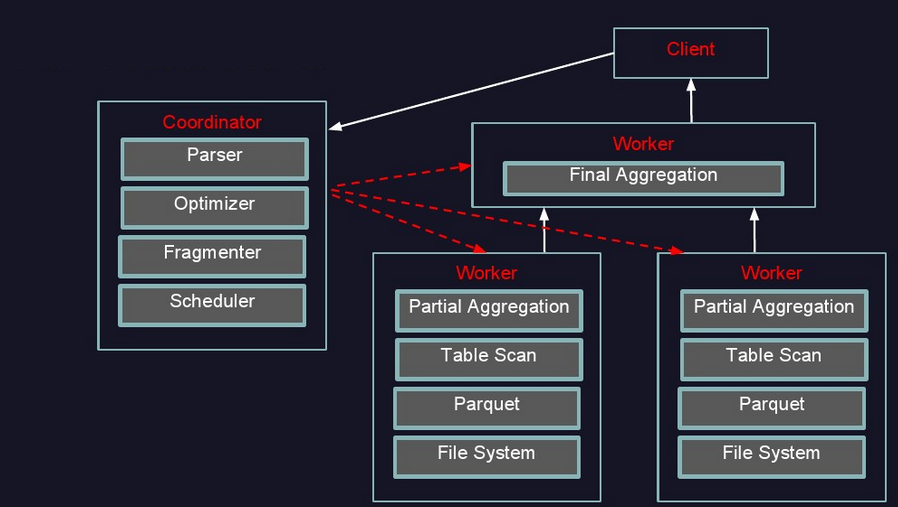
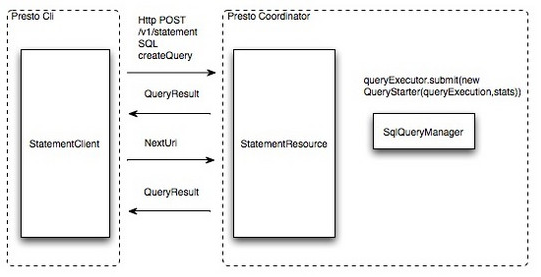
- 提交查詢:使用者使用Presto Cli提交一個查詢語句後,Cli使用HTTP協議與Coordinator通訊,Coordinator收到查詢請求後呼叫SqlParser解析SQL語句得到Statement物件,並將Statement封裝成一個QueryStarter物件放入執行緒池中等待執行,如下圖:示例SQL如下
-
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10; - 邏輯執行過程示意圖如下:
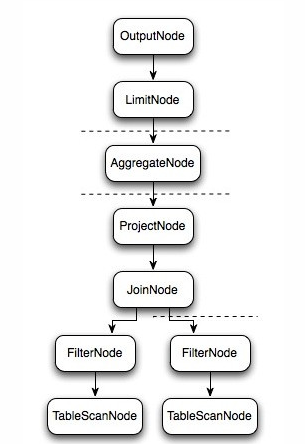
- 上圖邏輯執行計劃圖中的虛線就是Presto對邏輯執行計劃的切分點,邏輯計劃Plan生成的SubPlan分為四個部分,每一個SubPlan都會提交到一個或者多個Worker節點上執行
- SubPlan有幾個重要的屬性planDistribution、outputPartitioning、partitionBy屬性整個執行過程的流程圖如下:
- PlanDistribution:表示一個查詢階段的分發方式,上圖中的4個SubPlan共有3種不同的PlanDistribution方式
- Source:表示這個SubPlan是資料來源,Source型別的任務會按照資料來源大小確定分配多少個節點進行執行
- Fixed: 表示這個SubPlan會分配固定的節點數進行執行(Config配置中的query.initial-hash-partitions引數配置,預設是8)
- None: 表示這個SubPlan只分配到一個節點進行執行
- OutputPartitioning:表示這個SubPlan的輸出是否按照partitionBy的key值對資料進行Shuffle(洗牌), 只有兩個值HASH和NONE
- PlanDistribution:表示一個查詢階段的分發方式,上圖中的4個SubPlan共有3種不同的PlanDistribution方式
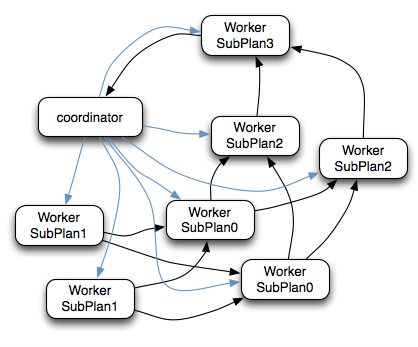
- 在上圖的執行計劃中,SubPlan1和SubPlan0 PlanDistribution=Source,這兩個SubPlan都是提供資料來源的節點,SubPlan1所有節點的讀取資料都會發向SubPlan0的每一個節點;SubPlan2分配8個節點執行最終的聚合操作;SubPlan3只負責輸出最後計算完成的資料,如下圖:
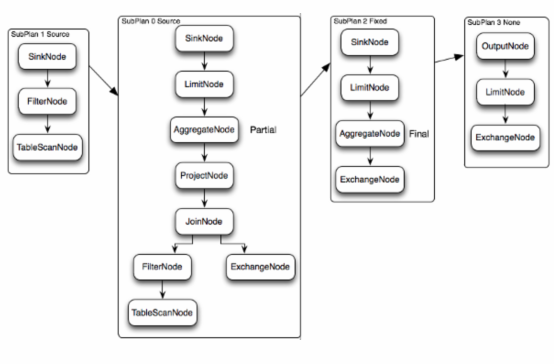
- SubPlan1和SubPlan0 作為Source節點,它們讀取HDFS檔案資料的方式就是呼叫的HDFS InputSplit API,然後每個InputSplit分配一個Worker節點去執行,每個Worker節點分配的InputSplit數目上限是引數可配置的,Config中的query.max-pending-splits-per-node引數配置,預設是100
- SubPlan1的每個節點讀取一個Split的資料並過濾後將資料分發給每個SubPlan0節點進行Join操作和Partial Aggr操作
- SubPlan0的每個節點計算完成後按GroupBy Key的Hash值將資料分發到不同的SubPlan2節點
- 所有SubPlan2節點計算完成後將資料分發到SubPlan3節點
- SubPlan3節點計算完成後通知Coordinator結束查詢,並將資料傳送給Coordinator
presto引擎對比
- 與hive、SparkSQL對比結果圖
