
HDFS——HDFS整體設計架構和原理
在我們學習HDFS之前,首先要了解分散式檔案系統的概念,分散式檔案系統有很多,HDFS只是其中的一種而已。那麼分散式檔案系統是什麼呢,又有哪些優點?
隨著現在資料量越來越多,在一個作業系統管轄的範圍存不下了,那麼就需要分配到更多的作業系統管理的磁碟中,但是這樣又不方便管理和維護,因此迫切需要一種系統來管理多臺機器上的檔案,這就產生了分散式檔案管理系統。
分散式檔案系統是一種允許檔案通過網路在多臺主機上分享的檔案系統,可讓多機器上的多使用者分享檔案和儲存空間。分散式檔案系統主要有下面兩個特點:
1)通透性。讓實際上是通過網路來訪問檔案的動作,由程式與使用者看來,就像是訪問本地磁碟一般。
2)容錯性。即使系統中有某些結點離線,整體來說系統仍然可以持續運作而不會有資料丟失。(這一點後面會詳細解釋)
分散式檔案系統有很多,hafs只是其中一種。適用於一次寫入多次查詢的情況,不支援併發寫操作,小檔案不適合。(下面也會解釋)
HDFS設計架構
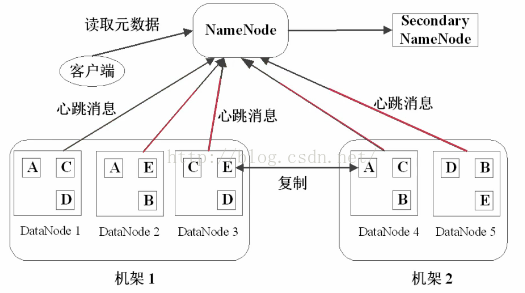
我們先看一下系統體系圖

想要看懂這張圖,我們先得了解這幾個基本概念:
塊(block):我們可以看到圖中有 “讀取資料塊” 的字樣,那麼資料塊是什麼呢?塊在檔案系統裡面通常是指固定大小的邏輯單元,HDFS的檔案就是被分成塊進行儲存,每個HDFS塊的預設大小是64MB
NameNode:管理節點,存放元資料,元資料又包括兩個部分:1.檔案與資料塊的對映表,2.資料塊與資料節點的對映表。這裡也就可以解釋為什麼HDFS不適合儲存小檔案了,因為不管是存大檔案或是小檔案都是需要在NameNode裡寫入元資料,顯然存小檔案是不划算的。
DataNode:HDFS的工作節點,存放資料塊。
HDFS為了保證對硬體上的容錯,對任何一個數據塊都是預設存三份,因為任何一個節點都可能發生故障,為了保證資料不被丟失,資料塊就有多分冗餘。
在上圖中,A,B,C,D都是64MB的資料塊,而且預設都有三份,其中兩份在同一機架上,在另一個機架上也有一份。這樣即使一個節點掛了,還可以在同一機架的另一個節點上找到相同資料塊。即使整個機架掛了,也可以在另一個機架上找到。
我們可以舉個例子來理解整個過程:NameNode 相當於一個倉庫管理員,他需要維護自己的一個賬本,而 DataNode 相當於一個倉庫,在倉庫裡面存放資料,客戶端相當於送貨人或者提貨人。當我們要存資料(貨物)的時候,送貨人想將貨物放到倉庫裡,首先要跟倉庫管理員打交道,即傳送一個請求,倉庫管理員先檢視賬本(包含各個倉庫的資訊),看看哪些倉庫可以用之類的,然後告訴送貨員你把貨物送到某個倉庫裡面去。
心跳檢測
每個DataNode定期向NameNode傳送心跳訊息,來彙報自己的狀況:是否還處於Active狀態,網路是否斷開之類的。
Secondary NameNode
二級 NameNode ,定期同步元資料映像檔案和修改日誌,當 NameNode 發生故障時,Secondary NameNode可用來恢復檔案系統。為了防止 NameNode 發生故障時,元資料丟失。大部分情況下,當NameNode 正常工作時,Secondary NameNode 只做備份工作,而不接受請求。
切記:Secondary NameNode 不是 NameNode 的熱備程序,也就是說它是無法直接替代 NameNode 進行工作的。