
【資料倉庫】資料集市
概念
資料集市是資料倉庫的一種簡單形式,通常由組織內的業務部門自己建立。一個數據集市面向單一主題,如銷售、財務、市場等。資料集市的資料來源可以是是操作型系統(獨立資料集市),也可以是資料倉庫(從屬資料集市)。
資料集市與資料倉庫的區別
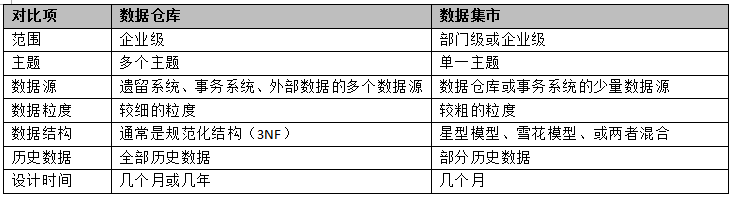
資料集市設計
資料集市主要用於部門級別的分析型應用,資料大都經過了綜合,粒度級別較高。資料集市一般採用維度模型設計方法,資料結構使用星型模型或雪花模型。
資料集市設計步驟和維度模型設計步驟相同:
(1)確定資料粒度級別、維度表、事實表;
(2)使用主外來鍵定義事實表和維度表之間的關係,主鍵最好使用數字型代理鍵;
(3)設計ETL抽取操作型源系統或資料倉庫資料,經過資料清洗、轉換,最終轉載進資料集市中的維度表和事實表。
相關推薦
【資料倉庫】資料集市
概念 資料集市是資料倉庫的一種簡單形式,通常由組織內的業務部門自己建立。一個數據集市面向單一主題,如銷售、財務、市場等。資料集市的資料來源可以是是操作型系統(獨立資料集市),也可以是資料倉庫(從屬資料
【資料倉庫】資料模型
0x00 前言 翻出來之前零零散散寫的資料倉庫的內容,重新修正整理成一個系列,此為第一篇《資料模型》。 資料倉庫包含的內容很多,比如系統架構、建模和方法論。對應到具體工作中的話,它可以包含下面的這些內容: 以Hadoop、Spark、Hive等元件為中心的資料架構體
資料倉庫和資料集市的區別【轉載】
看了很多資料倉庫方面的資料,都涉及到了“資料集市”這一說法,剛開始對資料倉庫和資料集市的區別也理解得比較膚淺,現在做個深入的歸納和總結,主要從如下幾個方面進行闡述: (1) 基本概念 (2) 為什麼提出資料集市 (3) 資料倉庫設計方法論 (4) 資料集市和資料倉庫的區別 (5) 倉庫建模與集市建模 (6)
【資料倉庫】2.維度建模
0x00 前言 前一篇已經對常用的幾種資料模型做了簡單的介紹,本篇主要對其中最常用的維度建模做一個深入的理解。 0x01 什麼是維度建模 維度模型是資料倉庫領域另一位大師 Ralph Kimball 所倡導,他的《The DataWarehouse Toolkit-The Complet
【資料倉庫】1.資料模型
0x00 前言 翻出來之前零零散散寫的資料倉庫的內容,重新修正整理成一個系列,此為第一篇《資料模型》。 資料倉庫包含的內容很多,比如系統架構、建模和方法論。對應到具體工作中的話,它可以包含下面的這些內容: 以Hadoop、Spark、Hive等元件為中心的資料架構體系
【資料倉庫】6. ETL 的設計
0x00 前言 資料倉庫體系裡面的主要內容也寫的差不多了,現在補一點之前遺漏的點。這一篇就來聊一下 ETL。 文章結構 先聊一下什麼是 ETL。 聊一下大致的概念和一般意義上的理解。 聊一聊資料流是什麼樣子。因為 ETL 的工作主要會體現在一條條的資料處理流上,因此這裡做一個
【資料倉庫】6.資料質量監控
0x00 前言 往往那些不起眼的功能,最能毀掉你的工作成果。 本篇分享一些和資料質量監控相關的內容。資料質量監控是一個在快速發展的業務中最容易被犧牲和忽略的功能,但是它確實至關重要的。 文章結構 資料質量監控的意義和價值就不再談了,本文主要討論下面三個主題:
【資料倉庫】5.如何優雅地設計資料分層
0x00 前言 一、文章主題 本文主要講解資料倉庫的一個重要環節:如何設計資料分層!其它關於資料倉庫的內容可參考之前的文章。 本文對資料分層的討論適合下面一些場景,超過該範圍場景 or 資料倉庫經驗豐富的大神就不必浪費時間看了。 資料建設剛起步,大部分的資
【資料倉庫】4. 拉鍊表
0x00 前言 過了半年時間,對資料倉庫的理解又有了一些不同的認識,翻出來之前寫的關於拉鍊表的內容,稍作修改重新發出來。本篇將會談一談在資料倉庫中拉鍊表相關的內容,包括它的原理、設計、以及在我們大資料場景下的實現方式。 內容 全文由下面幾個部分組成: 先分享一下拉鍊表的用途、
【資料倉庫】3.緩慢變化維度(SCD)
0x00 前言 本文會分享資料倉庫中和緩慢變化維度相關的內容。在看之前建議回顧一下和維度建模相關的知識點,可參考這篇:No.12 【漫談資料倉庫】維度建模。 為什麼會分享這個聽起來很奇怪的東西?因為站在的筆者的視角中,只要是做資料倉庫的小夥伴們,在工作中基本上都會接觸和維度建模相關的內容,而
【資料倉庫】3. 拉鍊表
0x00 前言 過了半年時間,對資料倉庫的理解又有了一些不同的認識,翻出來之前寫的關於拉鍊表的內容,稍作修改重新發出來。本篇將會談一談在資料倉庫中拉鍊表相關的內容,包括它的原理、設計、以及在我們大資料場景下的實現方式。 內容 全文由下面幾個部分組成: 先分享一下拉
【資料倉庫】大資料定義
2012年Gartner公司將大資料定義為3V,即:大容量(Volume)、高流速(Velocity)、多樣化(Variety),後來人們在3V基礎上增加新的V-"Veracity",即真
【線段樹】資料結構
【描述】 在看了 jiry_2 的課件《Segment Tree Beats!》後,小 O 深深沉迷於這種能單次 O(logn) 支援區間與一個數取 min/max,查詢區間和等資訊的資料結構,於是他決定做一道與區間與 一個數取 min/max 的好題。 這題是這樣的:你得到了一個長度為 n
資料倉庫和資料集市的概念、區別與聯絡
1.為什麼會出現資料倉庫和資料集市? “資料倉庫”的概念可以追溯到80 年代中期。從本質上講,最初資料倉庫是想為操作型系統到決策支援環境的資料流提供一種體系結構模型,並嘗試解決和這些資料流相關的各種問題。 在缺乏“資料倉庫”體系結構的情
【複習筆記】資料結構-檢索
效能用ASL(查詢成功時的平均查詢長度)來衡量 線性表檢索 順序檢索 逐個比較 優點:插入元素可以直接加在表尾 缺點:檢索時間太長 二分檢索法 條件:序列必須有序 實現: 1 template <class Type> int Bi
【資料結構】資料的儲存結構
資料有有線性結構、樹形結構、圖狀結構和集合四種邏輯結構,那麼它們是如何儲存的呢? 資料結構的儲存結構有兩種,分別是順序儲存和鏈式儲存。順序儲存的特點是藉助元素在儲存器中的相對位置來表示資料元素之間的邏輯關係;鏈式儲存的特點是藉助指標表示資料元素質檢單邏輯關係。 1.線
【OJ.2132】資料結構實驗之棧與佇列二:一般算術表示式轉換成字尾式
資料結構實驗之棧與佇列二:一般算術表示式轉換成字尾式 Time Limit: 1000 ms
【暖*墟】 #資料結構# 分塊入門訓練題1~9
引入foreword 數列分塊就是把數列中【每m個元素打包起來】,達到優化演算法的目的。 把每m個元素分為一塊,共有n/m塊,區間修改涉及O(n/m)個整塊,以及兩側兩個不完整的塊。 每次操作對每個整塊直接標記,而由於不完整的塊的元素比較少,暴力修改元素的值。 每次
【機器學習】資料分析王者 CatBoost vs. Light GBM vs. XGBoost
機器學習領域的一個特點就是日新月異,在資料競賽中,一件趁手的工具對比賽結果有重要影響。boosting是一種將弱分類器組合成強分類器的方法,它包含多種演算法,如GDBT、AdaBoost、XGBoost等等。如果你參加過Kaggle之類的資料競賽,你可能聽說過XGBoost在
【機器學習】資料探勘演算法——關聯規則(一),相關概念,評價指標
綜述: 資料探勘是指以某種方式分析資料來源,從中發現一些潛在的有用的資訊,所以資料探勘又稱作知識發現,而關聯規則挖掘則是資料探勘中的一個很重要的課題,顧名思義,它是從資料背後發現事物之間可能存在的關聯或者聯絡。 關聯規則的目的在於在一個數據集中找出項之間的關