
JDK原始碼學習(jdk1.8.0_20)
阿新 • • 發佈:2019-02-15
集合框架
ArrayList
基於jdk1.8.0_20
| 關注點 | 結論 |
|---|---|
| ArrayList是否允許空 | 允許 |
| ArrayList是否允許重複資料 | 允許 |
| ArrayList是否有序 | 有序 |
| ArrayList是否執行緒安全 | 非執行緒安全 |
繼承關係圖
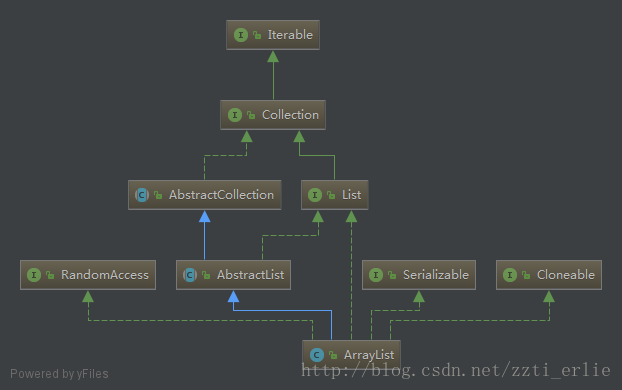
ArrayList的定義
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java ArrayList的底層使用Object陣列來儲存的
transient Object[] elementData;以前聽說ArrayList的初始大小為10,應該是以前的版本,我這個版本中ArrayList如果不指定大小時預設為空
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}在這裡主要關注一下自動擴容的實現
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
//確保陣列大小超過size + numNew
ensureCapacityInternal(size + numNew);
//實現陣列複製,a是源陣列,0是源陣列要複製的起始位置,elementData是目的陣列
//size是目的陣列放置的起始位置,numNew複製的長度
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
//如果c為空則返回false,不為空則返回true public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}增加一個元素或者增加好幾個元素都會在呼叫ensureCapacityInternal方法來確保陣列大小足夠大,可以確定在ensureCapacityInternal方法裡面實現了自動擴容
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private static final int DEFAULT_CAPACITY = 10;private void ensureCapacityInternal(int minCapacity) {
//目前陣列為空
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//要求的容量大小和10取最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//這個是出於2種考慮
//如果需要的容量大於目前的容量,就需要擴容
//如果minCapacity溢位,即minCapacity為負數,就不擴容
//minCapacity為負數的一種情況是addAll(Collection<? extends E> c)傳入的引數已經溢位了
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}//之所以定義為Integer.MAX_VALUE - 8,是因為VM會保留一些頭結點在陣列開頭
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//>>是右移運算子,相當於除以2,因此新容量是舊容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
//這裡需要分為2種情況
//1.擴容還不滿足,直接將新容量設為需要的容量
//2.newCapacity溢位,變為負數,擴充容量擴的太大了
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}private static int hugeCapacity(int minCapacity) {
//溢位了,minCapacity的值大於int能儲存的最大值,用int儲存會變為負數
//這裡minCapacity之所以為負數,可能是因為vm進行了一些操作
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}這個類實現陣列複製用的是System.arraycopy方法,這個方法複製比較快,因為是對記憶體直接進行復制,減少了for迴圈中的定址時間
//實現陣列複製,a是源陣列,0是源陣列要複製的起始位置,elementData是目的陣列
//size是目的陣列放置的起始位置,numNew複製的長度
System.arraycopy(a, 0, elementData, size, numNew);LinkedList
基於jdk1.8.0_20
| 關注點 | 結論 |
|---|---|
| LinkedList是否允許空 | 允許 |
| LinkedList是否允許重複資料 | 允許 |
| LinkedList是否有序 | 有序 |
| LinkedList是否執行緒安全 | 非執行緒安全 |
繼承關係圖
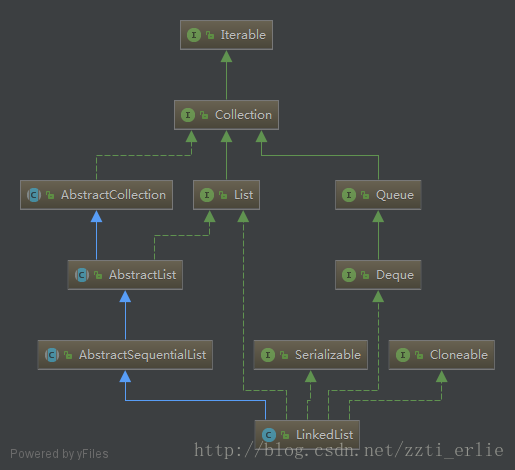
LinkedList的定義
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.SerializableLinkedList採用的雙向連結串列結構,因此在LinkedList中定義了一個靜態內部類
private static class Node<E> {
//存放元素
E item;
//相當於後向指標,指向連結串列中當前元素的後一個元素
Node<E> next;
//相當於前向指標,指向連結串列中當前元素的前一個元素
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}定義的變數為
//連結串列的長度
transient int size = 0;
//連結串列的頭結點
transient Node<E> first;
//連結串列的尾結點
transient Node<E> last;增加元素的方法,addFirst,addLast,add都很類似,分析一個
public void addFirst(E e) {
linkFirst(e);
}private void linkFirst(E e) {
//把連結串列的頭結點放到f這個中途變數
final Node<E> f = first;
//構造結點,前向指標為null,元素為e,後向指標指到f
final Node<E> newNode = new Node<>(null, e, f);
//插入的結點程式設計頭結點
first = newNode;
//如果原先頭結點為空
if (f == null)
//構造的結點不僅為頭結點,也是尾結點
last = newNode;
else
//原先頭結點的前向指標指向構造的結點
f.prev = newNode;
//元素個數加1
size++;
//每次對元素進行操作時,這個都會增加1,主要為了迭代器校驗錯誤使用
modCount++;
}
刪除元素的方法
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//如果前向指標為空,則說明它是頭結點,刪除時只要把它的下一個結點賦值為頭結點即可
if (prev == null) {
first = next;
} else {
//前向結點的後向指標直接指向後向結點,從開頭遍歷不到這個結點
prev.next = next;
x.prev = null;
}
//如果後向指標為空,則說明它是尾結點,刪除時只要把它的上一個結點賦值為尾結點即可
if (next == null) {
last = prev;
} else {
//後向結點的前向指標直接指向前向結點,從結尾遍歷不到這個結點
next.prev = prev;
x.next = null;
}
//把x.prev和x.next賦值為null,LZ猜是為了加速垃圾回收,但沒有實際測試
x.item = null;
size--;
modCount++;
return element;
}獲取元素的方法
public E get(int index) {
//檢查下標是否越界
checkElementIndex(index);
return node(index).item;
}Node<E> node(int index) {
// assert isElementIndex(index);
//size >> 1和size / 2一個效果,因為將位右移一位相當於除2
//在前半段,正向遍歷
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
//在後半段,反向遍歷
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}分析原始碼可知,通過get方式遍歷LinkedList是一種很低效的方式,因為每找一個元素都是從頭或者尾開始的,最好採用foreach或迭代器方式
Hashtable
基於jdk1.7.0_80
| 關注點 | 結論 |
|---|---|
| Hashtable是否允許空 | key和value均不允許為空 |
| Hashtable是否允許重複資料 | 不允許 |
| Hashtable是否有序 | 無序 |
| Hashtable是否執行緒安全 | 執行緒安全 |
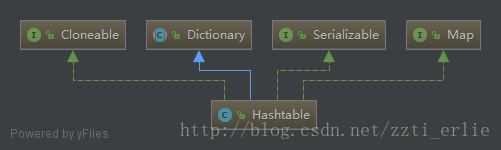
建構函式,預設初始容量為11
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
initHashSeedAsNeeded(initialCapacity);
}public Hashtable() {
this(11, 0.75f);
}put
public synchronized V put(K key, V value) {
//value為null丟擲空指標異常
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = hash(key);
//7FFFFFFF的二進位制為1111111111111111111111111111111
//hash & 0x7FFFFFFF是為了保hash值始終為正數
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
//數量已經達到閾值
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
//table的值已經變化
tab = table;
//重新進行hash
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
//取出目前連結串列第一位
Entry<K,V> e = tab[index];
//將新增加的值變為第一個值
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}和HashMap的區別
| 關注點 | Hashtable | HashMap |
|---|---|---|
| 是否執行緒安全 | 是 | 否 |
| key和vlaue | 均不允許為空 | 都可以為空 |
| 求index的方法 | (hash & 0x7FFFFFFF) % table.length; | hash & (table.length - 1) |
| 擴容的時機 | count >= threshold | (size >= threshold) && (null != table[bucketIndex]) |
| 擴容的大小 | table.length<<1+1 | 2 * table.length |
get
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}這裡put和get方法都沒有對key進行空值判斷,是因為key為null呼叫hash會丟擲空指標異常
private int hash(Object k) {
// hashSeed will be zero if alternative hashing is disabled.
return hashSeed ^ k.hashCode();
}Vector
基於jdk1.8.0_20
Stack
基於jdk1.8.0_20
ArrayDeque
基於jdk1.8.0_20