
深度學習之基礎(一)
#baidu => buy vedio => dl basic
機器學習是一門不需要外部程式指示而讓計算機有能力自我學習的學科;而學習是指對於經驗(E)、任務(T)和效能(P),如果隨著E的增加,在定義好的T下,提高P的表現能力,就說明計算機有學習的能力。
一.深度學習
DL是基於ML延伸出來的一個新領域,由以人大腦結構為啟發的神經網路演算法為起源加之模型結構深度的增加而發展,並伴隨大資料和計算能力的提高而產生的一系列新演算法。
1.神經網路:最著名的演算法是backpropagation(bp反向傳播)
2.多層向前神經網路(Multilayer Feed-Forward Neutral Network):
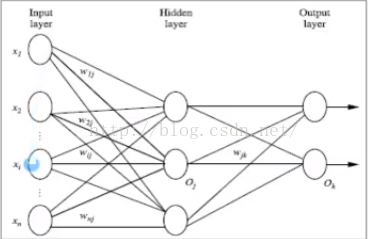
組成部分:輸入層(input layer)、隱藏層(hidden layers)、輸出層(output layers)。
每層由Unit單元組成(也可以叫做神經節點)。
輸入層是有訓練集的例項特徵向量傳入的。
經過連線節點的權重(weight)傳入下一層,一層的輸出是下一層的輸入。
一層中進行加權求和,然後根據非線性方程轉換輸出。
理論上講:作為多層向前神經網路,如果有足夠多的隱藏層和足夠大的訓練集,可以模擬出任何方程。
3.設計神經網路結構:Q1:確定神經網路的層數.Q2:確定神經網路每層的次數
使用神經網路訓練資料之前,必須確定神經網路的層數,以及單元個數;特徵向量在被傳入輸入層時,通常被先標準化(normalize)到0和1之間(為了加速學習的過程);離散型變數可以被編碼成每一個輸入單元對應一個特徵可能賦的值;
神經網路可以用來做分類和迴歸問題:
對於分類問題,如果是2類,可以用一個輸入單元表示(0和1分別代表2類);如果多於兩類,每一個類別用一個輸出單元表示。所以輸入層的單元數量通常等於類別的數量 。