
解讀分庫分表中介軟體Sharding-JDBC
3月18日-19日,由CSDN重磅打造的網際網路應用架構實戰峰會、資料庫核心技術與實戰應用峰會將在上海舉行。作為SDCC 2016(中國軟體開發者大會)系列技術峰會的一部分,秉承乾貨實料(案例)的內容原則,這兩場峰會將邀請業內頂尖的架構師和技術專家,共同探討高可用/高併發系統架構設計、新技術應用、移動應用架構、微服務、智慧硬體架構、雲資料庫實戰、新一代資料庫平臺、產品選型、效能調優、大資料應用實戰等領域的話題與技術。
優惠購票,限期低至6折:http://bss.csdn.net/m/topic/sdcc_invite
【編者按】資料庫分庫分表從網際網路時代開啟至今,一直是熱門話題。在NoSQL橫行的今天,關係型資料庫憑藉其穩定、查詢靈活、相容等特性,仍被大多數公司作為首選資料庫。因此,合理採用分庫分表技術應對海量資料和高併發對資料庫的衝擊,是各大網際網路公司不可避免的問題。
雖然很多公司都致力於開發自己的分庫分表中介軟體,但截止目前,仍無完美的開源解決方案覆蓋此領域。
分庫分表適用場景
分庫分表用於應對當前網際網路常見的兩個場景——大資料量和高併發。通常分為垂直拆分和水平拆分兩種。
垂直拆分是根據業務將一個庫(表)拆分為多個庫(表)。如:將經常和不常訪問的欄位拆分至不同的庫或表中。由於與業務關係密切,目前的分庫分表產品均使用水平拆分方式。
水平拆分則是根據分片演算法將一個庫(表)拆分為多個庫(表)。如:按照ID的最後一位以3取餘,尾數是1的放入第1個庫(表),尾數是2的放入第2個庫(表)等。
關係型資料庫在大於一定資料量的情況下檢索效能會急劇下降。在面對網際網路海量資料情況時,所有資料都存於一張表,顯然會輕易超過資料庫表可承受的資料量閥值。這個單表可承受的資料量閥值,需根據資料庫和併發量的差異,通過實際測試獲得。
單純的分表雖然可以解決資料量過大導致檢索變慢的問題,但無法解決過多併發請求訪問同一個庫,導致資料庫響應變慢的問題。所以通常水平拆分都至少要採用分庫的方式,用於一併解決大資料量和高併發的問題。這也是部分開源的分片資料庫中介軟體只支援分庫的原因。
但分表也有不可替代的適用場景。最常見的分表需求是事務問題。同在一個庫則不需考慮分散式事務,善於使用同庫不同表可有效避免分散式事務帶來的麻煩。目前強一致性的分散式事務由於效能問題,導致使用起來並不一定比不分庫分錶快。目前採用最終一致性的柔性事務居多。分表的另一個存在的理由是,過多的資料庫例項不利於運維管理。綜上所述,最佳實踐是合理地配合使用分庫+分表。
Sharding-JDBC簡介
Sharding-JDBC是噹噹應用框架ddframe中,從關係型資料庫模組dd-rdb中分離出來的資料庫水平分片框架,實現透明化資料庫分庫分表訪問。Sharding-JDBC是繼dubbox和elastic-job之後,ddframe系列開源的第3個專案。
Sharding-JDBC直接封裝JDBC API,可以理解為增強版的JDBC驅動,舊程式碼遷移成本幾乎為零:
- 可適用於任何基於Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
- 可基於任何第三方的資料庫連線池,如DBCP、C3P0、 BoneCP、Druid等。
- 理論上可支援任意實現JDBC規範的資料庫。雖然目前僅支援MySQL,但已有支援Oracle、SQLServer等資料庫的計劃。
Sharding-JDBC定位為輕量Java框架,使用客戶端直連資料庫,以jar包形式提供服務,無proxy代理層,無需額外部署,無其他依賴,DBA也無需改變原有的運維方式。
Sharding-JDBC分片策略靈活,可支援等號、between、in等多維度分片,也可支援多分片鍵。
SQL解析功能完善,支援聚合、分組、排序、limit、or等查詢,並支援Binding Table以及笛卡爾積表查詢。
與常見開源產品對比
為了對其他開源專案表示尊重,我們無意評論目前仍在更新中的專案。這裡僅列出目前停止更新,但仍然在資料庫分片領域非常有影響力的幾個專案,請參見表1。
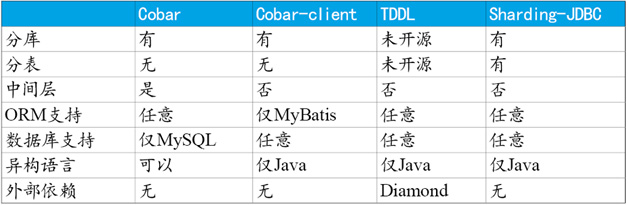
通過以上表格可以看出,Cobar屬於中間層方案,在應用程式和MySQL之間搭建一層Proxy。中間層介於應用程式與資料庫間,需要做一次轉發,而基於JDBC協議並無額外轉發,直接由應用程式連線資料庫,效能上有些許優勢。這裡並非說明中間層一定不如客戶端直連,除了效能,需要考慮的因素還有很多,中間層更便於實現監控、資料遷移、連線管理等功能。
Cobar-Client、TDDL和Sharding-JDBC均屬於客戶端直連方案。此方案的優勢在於輕便、相容性、效能以及對DBA影響小。其中Cobar-Client的實現方式基於ORM(Mybatis)框架,其相容性與擴充套件性不如基於JDBC協議的後兩者。
實現原理
前文已介紹了Sharding-JDBC是實現了JDBC協議的jar檔案。基於JDBC協議的實現與基於MySQL等資料庫協議實現的中間層略有差別。
無論使用哪種架構,核心邏輯均極為相似,除了協議實現層不同(JDBC或資料庫協議),都會分為分片規則配置、SQL解析、SQL改寫、SQL路由、SQL執行以及結果歸併等模組。
Sharding-JDBC的整體架構圖參見圖1。
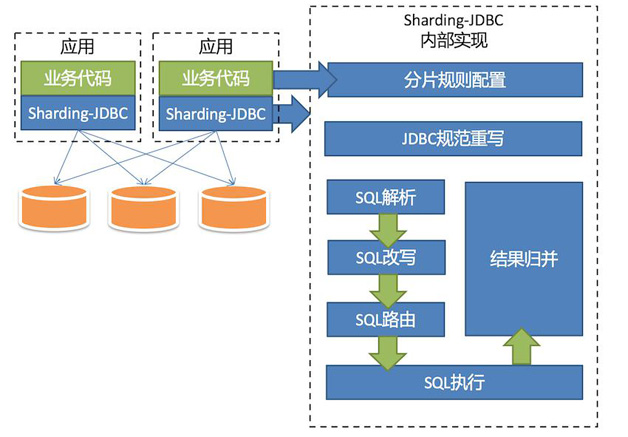
分片規則配置
Sharding-JDBC的分片邏輯非常靈活,支援分片策略自定義、複數分片鍵、多運算子分片等功能。
如:根據使用者ID分庫,根據訂單ID分表這種分庫分表結合的分片策略;或根據年分庫,月份+使用者區域ID分表這樣的多片鍵分片。
Sharding-JDBC除了支援等號運算子進行分片,還支援in/between運算子分片,提供了更加強大的分片功能。
Sharding-JDBC提供了spring名稱空間用於簡化配置,以及規則引擎用於簡化策略編寫。由於目前剛開源分片核心邏輯,這兩個模組暫未開源,待核心穩定後將會開源其他模組。
JDBC規範重寫
Sharding-JDBC對JDBC規範的重寫思路是針對DataSource、Connection、Statement、PreparedStatement和ResultSet五個核心介面封裝,將多個真實JDBC實現類集合(如:MySQL JDBC實現/DBCP JDBC實現等)納入Sharding-JDBC實現類管理。
Sharding-JDBC儘量最大化實現JDBC協議,包括addBatch這種在JPA中會使用的批量更新功能。但分片JDBC畢竟與原生JDBC不同,所以目前仍有未實現的介面,包括Connection遊標,儲存過程和savePoint相關、ResultSet向前遍歷和修改等不太常用的功能。此外,為了保證相容性,並未實現JDBC 4.1及其後釋出的介面(如:DBCP 1.x版本不支援JDBC 4.1)。
SQL解析
SQL解析作為分庫分表類產品的核心,效能和相容性是最重要的衡量指標。目前常見的SQL解析器主要有fdb/jsqlparser和Druid。Sharding-JDBC使用Druid作為SQL解析器,經實際測試,Druid解析速度是另外兩個解析器的幾十倍。
目前Sharding-JDBC支援join、aggregation(包括avg)、order by、 group by、limit、甚至or查詢等複雜SQL的解析。目前不支援union、部分子查詢、函式內分片等不太應在分片場景中出現的SQL解析。
SQL改寫
SQL改寫分為兩部分,一部分是將分表的邏輯表名稱替換為真實表名稱。另一部分是根據SQL解析結果替換一些在分片環境中不正確的功能。這裡具兩個例子:
第1個例子是avg計算。在分片的環境中,以avg1 +avg2+avg3/3計算平均值並不正確,需要改寫為(sum1+sum2+sum3)/(count1+count2+ count3)。這就需要將包含avg的SQL改寫為sum和count,然後再結果歸併時重新計算平均值。
第2個例子是分頁。假設每10條資料為一頁,取第2頁資料。在分片環境下獲取limit 10, 10,歸併之後再根據排序條件取出前10條資料是不正確的結果。正確的做法是將分條件改寫為limit 0, 20,取出所有前2頁資料,再結合排序條件算出正確的資料。可以看到越是靠後的Limit分頁效率就會越低,也越浪費記憶體。有很多方法可避免使用limit進行分頁,比如構建記錄行記錄數和行偏移量的二級索引,或使用上次分頁資料結尾ID作為下次查詢條件的分頁方式。
SQL路由
SQL路由是根據分片規則配置,將SQL定位至真正的資料來源。主要分為單表路由、Binding表路由和笛卡爾積路由。
單表路由最為簡單,但路由結果不一定落入唯一庫(表),因為支援根據between和in這樣的操作符進行分片,所以最終結果仍然可能落入多個庫(表)。
Binding表可理解為分庫分表規則完全一致的主從表。舉例說明:訂單表和訂單詳情表都根據訂單ID作為分片鍵,任意時刻分片邏輯均相同。這樣的關聯查詢和單表查詢難度和效能相當。
笛卡爾積查詢最為複雜,因為無法根據Binding關係定位分片規則的一致性,所以非Binding表的關聯查詢需要拆解為笛卡爾積組合執行。查詢效能較低,而且資料庫連線數較高,需謹慎使用。
SQL執行
路由至真實資料來源後,Sharding-JDBC將採用多執行緒併發執行SQL,並完成對addBatch等批量方法的處理。
結果歸併
結果歸併包括4類:普通遍歷類、排序類、聚合類和分組類。每種型別都會先根據分頁結果跳過不需要的資料。
普通遍歷類最為簡單,只需按順序遍歷ResultSet的集合即可。
排序類結果將結果先排序再輸出,因為各分片結果均按照各自條件完成排序,所以採用歸併排序演算法整合最終結果。
聚合類分為3種類型,比較型、累加型和平均值型。比較型包括max和min,只返回最大(小)結果。累加型包括sum和count,需要將結果累加後返回。平均值則是通過SQL改寫的sum和count計算,相關內容已在SQL改寫涵蓋,不再贅述。
分組類最為複雜,需要將所有的ResultSet結果放入記憶體,使用map-reduce演算法分組,最後根據排序和聚合條件做相關處理。最消耗記憶體,最損失效能的部分即是此,可以考慮使用limit合理的限制分組資料大小。
結果歸併部分目前並未採用管道解析的方式,之後會針對這裡做更多改進。
效能
路由結果在單庫單表的效能測試報告:
查詢操作:Sharding-JDBC的TPS為JDBC的TPS的99.8%;
插入操作:Sharding-JDBC的TPS為JDBC的TPS的90.2%;
更新操作:Sharding-JDBC的TPS為JDBC的TPS的93.1%;
可以看到,Sharding-JDBC效能損失非常低。
路由結果在多庫多表的效能測試報告:
查詢操作:TPS雙庫比單庫可以增加大約94%的效能;
插入操作:TPS雙庫比單庫可以增加大約60%的效能;
更新操作:TPS雙庫比單庫可以增加大約89%的效能;
結果表明,Sharding-JDBC可有效利用多執行緒與分散式資源大幅度提升效能;
更多詳細情況可檢視Sharding-JDBC的效能測試報告。
Roadmap
目前Sharding-JDBC集中於分庫分表核心邏輯開發,在功能穩定之後將會按照如下線路持續更新:
- 讀寫分離;
- 柔性分散式事務;
- 分散式主鍵生成策略;
- SQL重寫優化,進一步提升效能;
- SQL Hint,可指定某SQL在某具體庫表執行,基於業務規則而非SQL解析路由;
小表廣播; - HA相關;
- 流量控制;
- 資料庫建表工具;
- 資料遷移;
- 複雜SQL解析支援,如子查詢、儲存過程等;
- Oracle, SQLServer支援;
- 配置中心;
開源理念
目前國內很多開源產品都在公司內部經受過時間的考驗,然後剝離業務邏輯和敏感程式碼,再開源貢獻給社群。這樣做的優點是開源的產品相對成熟。但缺點也不可避免,主要有:
- 後續支援匱乏。產品已經滿足了該公司的業務場景需求,缺乏後續提升的動力。文件、支援也會相對較少,甚至出現文件和程式碼不同步的狀況。
- 與該公司業務場景耦合較為嚴重。大部分框架產品都是為了解決特定的問題。比如:有的公司可能並不需要分表;有的公司只需支援幾種分片策略就好。
- 開源不完整。和公司業務耦合緊密的部分不會開源。
- 缺乏粘度。較為成型的專案由於功能繁多、程式碼結構複雜,社群志願者難於擴充套件或修改核心邏輯。如果測試覆蓋率不夠,難以保證修改後的程式碼質量。以上一系列問題會導致專案對社群的粘度不高,難於找尋可合作開發的志願者。
- 分支眾多難於維護。由於開源之後公司缺乏持續提升的動力,和本公司關係不大的需求功能得不到重視,導致各公司都開發自己的分支。開源專案雖然一開始給社群注入了新鮮思想,但最終並沒有吸取社群精華。如:Dubbo一出現即引起了相當多的關注,而各公司都有自己的版本,如噹噹的DubboX,但最終Dubbo並未能持續發展。
我們考慮全新的開源策略,在Sharding-JDBC剛完成初版的時候,即向社群和噹噹內部同時推廣。這樣做的好處有:
- 後續支援完善。Sharding-JDBC與噹噹內部落地繫結,將會在噹噹內部和社群同時提供支援。雖然無法提供社群需求的優先順序高於噹噹內部的承諾,但我們會綜合考慮社群與內部的需求,以更高的視角,儘量整合與優化升級路線。
- 完整開源。程式碼的snapshot版本都會首先出現在GitHub上。
- 共同發展。Sharding-JDBC目前程式碼較為簡單。使社群開源愛好者能更加輕鬆地理解程式碼核心,為以後的持續發展奠定基礎。並且Sharding-JDBC也會吸納社群精華,讓更多地愛好者參與程式碼貢獻。
最後需要澄清,未經時間考證的Sharding-JDBC並非Bug成堆,完全不可用的專案。目前測試覆蓋率超過90%,詳細功能以及不支援項都明確地羅列在GitHub的文件中,希望讓使用者心中有數。

本文作者:張亮
作者簡介:噹噹網架構師,噹噹技術委員會成員。目前主導噹噹應用框架ddframe研發和推廣以及技術白皮書撰寫。其中ddframe的分散式作業elastic-job和資料庫分片Sharding-JDBC已經正式開源。
責任編輯:錢曙光([email protected])
文章來源:《程式設計師》2月期
本文為《程式設計師》原創文章,未經允許不得轉載,訂閱2016年《程式設計師》請點選 http://dingyue.programmer.com.cn
相關推薦
解讀分庫分表中介軟體Sharding-JDBC
3月18日-19日,由CSDN重磅打造的網際網路應用架構實戰峰會、資料庫核心技術與實戰應用峰會將在上海舉行。作為SDCC 2016(中國軟體開發者大會)系列技術峰會的一部分,秉承乾貨實料(案例)的內容原則,這兩場峰會將邀請業內頂尖的架構師和技術專家,共同探討高可用/高併發
噹噹分庫分表中介軟體-sharding-jdbc
使用指南 閱讀本指南前,請先閱讀快速起步。本文件使用更復雜的場景進一步介紹Sharding-JDBC的分庫分表能力。 資料庫模式 本文件中提供了兩個資料來源db0和db1,每個資料來源之中包含了兩組表t_order_0和t_order_1,t_order_item_
資料庫分庫分表中介軟體 Sharding-JDBC 原始碼分析 —— 分散式主鍵
������關注微信公眾號:【芋道原始碼】有福利: 1. RocketMQ / MyCAT / Sharding-JDBC 所有原始碼分析文章列表 2. RocketMQ / MyCAT / Sharding-JDBC 中文註釋原始碼 Gi
一文快速入門分庫分表中介軟體 Sharding-JDBC (必修課)
書接上文 [《一文快速入門分庫分表(必修課)》](https://mp.weixin.qq.com/s/rYG58KS9kHDDOMajKT9y5Q),這篇拖了好長的時間,本來計劃在一週前就該寫完的,結果家庭內部突然人事調整,領導層進行權利交接,隨之宣佈我正式當爹,緊接著家庭地位滑落至第三名,還給我分配了一個
數據庫分庫分表中間件 Sharding-JDBC 源碼分析 —— SQL 解析(六)之刪除SQL
java 後端 架構 數據庫 中間件關註微信公眾號:【芋道源碼】有福利:RocketMQ / MyCAT / Sharding-JDBC 所有源碼分析文章列表RocketMQ / MyCAT / Sharding-JDBC 中文註釋源碼 GitHub 地址您對於源碼的疑問每條留言都將得到認真回復。甚至不知道如
數據庫分庫分表中間件 Sharding-JDBC 源碼分析 —— 分布式主鍵
java 後端 架構 數據庫 中間件關註**微信公眾號:【芋道源碼】**有福利:RocketMQ / MyCAT / Sharding-JDBC 所有源碼分析文章列表RocketMQ / MyCAT / Sharding-JDBC 中文註釋源碼 GitHub 地址您對於源碼的疑問每條留言都將得到認真回復。甚至
資料庫分庫分表中介軟體對比(很全)
分割槽:對業務透明,分割槽只不過把存放資料的檔案分成了許多小塊,例如mysql中的一張表對應三個檔案.MYD,MYI,frm。根據一定的規則把資料檔案(MYD)和索引檔案(MYI)進行了分割,分割槽後的表呢,還是一張表。分割槽可以把表分到不同的硬碟上,但不能分配到不同伺服器上。優點:資料不存在多個副本,不必進
MYCAT分庫分表中介軟體的簡單配置與使用
前一段時間讀了一本分散式相關的書籍,講到了一種mysql的分庫分表的中介軟體——shark,對它進行了一點研究,想用在實驗室要做的分散式交換系統之中。但是後來發現了一個問題,shark不支援強一致性的系統,而實驗室的分散式交換系統對於強一致性要求又比較高,不得已放棄
資料庫分庫分表中介軟體:Mycat;分散式資料庫;mysql的分散式事務
官網:http://mycat.io/,裡面有電子書籍可以下載:http://www.mycat.io/document/mycat-definitive-guide.pdf 舊版本下載地址:https://github.com/MyCATApache/Mycat-download,最新軟體下載地址:htt
學習dangdang的分庫分表擴充套件框架sharding-jdbc(一)
噹噹開源的sharding-jdbc,官方網址:https://github.com/dangdangdotcom/sharding-jdbc 一、簡介 好了,看了這麼多的介紹,感覺還是很高大上的,注意點有: ①對JDBC API進行了原生態的分裝,這是與cobar-c
在專案中使用分庫分表中介軟體Zdal
轉載:https://www.tuicool.com/articles/ENVFNjJ 在博主前面的一篇文章 《構建分庫分表中介軟體Zdal》 中已經基本介紹瞭如何構建Zdal,這篇文章主要介紹如何在傳統的Java Web專案中引入Zdal,來達到分庫或者分表的目的
資料庫 分庫分表中介軟體 Cobar 介紹
最近好不容易抽空研究了下Cobar,感覺這個產品確實很不錯(在文件方面比Amoeba強多了),特此推薦給大家。Cobar是阿里巴巴研發的關係型資料的分散式處理系統,該產品成功替代了原先基於Oracle的資料儲存方案,目前已經接管了3000+個MySQL資料庫的schema,平均每天處理近50億次的SQL執
Mycat 資料庫分庫分表中介軟體學習指南
對於分庫分表的資料庫設計很多情況下還是需要的,我們就此作為學習的起點,一起來看下前世來自阿里的Cobar而今的Mycat。 Mycat是什麼 一個徹底開源的,面向企業應用開發的大資料庫叢集 支援事務、ACID、可以替代MySQL的加強版資料庫 一個可以視為MySQL叢
Mycat 資料庫分庫分表中介軟體
Mycat關鍵特性 關鍵特性 支援SQL92標準遵守Mysql原生協議,跨語言,跨平臺,跨資料庫的通用中介軟體代理。基於心跳的自動故障切換,支援讀寫分離,支援MySQL主從,以及galera cluster叢集。支援Galera for MySQL叢集,Percona Cluster或者MariaDB cl
分庫分表中間件sharding-jdbc的使用
關系 java高級 減少 壓力 連接 提前 ofo 水平拆分 指定 數據分片產生的背景,可以查看https://shardingsphere.apache.org/document/current/cn/features/sharding/,包括了垂直拆分和水平拆分的概念.
分庫分表中介軟體的高可用實踐
# 分庫分表中介軟體的高可用實踐 ## 前言 分庫分表中介軟體在我們一年多的錘鍊下,基本解決了可用性和高效能的問題(只能說基本,肯定還有隱藏的坑要填),問題自然而然的就聚焦於高可用。本文就闡述了我們在這方面做出的一些工作。 ## 哪些高可用的問題 作為一個無狀態的中介軟體,高可用問題並沒有那麼困難。但是儘量減
資料庫中介軟體 Sharding-JDBC 原始碼分析 —— SQL 解析(三)之查詢SQL
������關注微信公眾號:【芋艿的後端小屋】有福利: 1. RocketMQ / MyCAT / Sharding-JDBC 所有原始碼分析文章列表 2. RocketMQ / MyCAT / Sharding-JDBC 中文註釋原始碼
資料庫中介軟體 Sharding-JDBC 原始碼分析 —— SQL 解析(一)之詞法解析
本文主要基於 Sharding-JDBC 1.5.0 正式版 ������關注微信公眾號:【芋道原始碼】有福利: 1. RocketMQ / MyCAT / Sharding-JDBC 所有原始碼分析文章列表 2. Roc
資料庫中介軟體 Sharding-JDBC 原始碼分析 —— SQL 解析(六)之刪除SQL
本文主要基於 Sharding-JDBC 1.5.0 正式版 ������關注微信公眾號:【芋道原始碼】有福利: 1. RocketMQ / MyCAT / Sharding-JDBC 所有原始碼分析文章列表 2. Roc
SpringBoot 2.0 整合sharding-jdbc中介軟體,實現資料分庫分表
一、水平分割 1、水平分庫 1)、概念: 以欄位為依據,按照一定策略,將一個庫中的資料拆分到多個庫中。 2)、結果 每個庫的結構都