
分庫分表中介軟體的高可用實踐
阿新 • • 發佈:2020-09-16
# 分庫分表中介軟體的高可用實踐
## 前言
分庫分表中介軟體在我們一年多的錘鍊下,基本解決了可用性和高效能的問題(只能說基本,肯定還有隱藏的坑要填),問題自然而然的就聚焦於高可用。本文就闡述了我們在這方面做出的一些工作。
## 哪些高可用的問題
作為一個無狀態的中介軟體,高可用問題並沒有那麼困難。但是儘量減少不可用期間的流量損失,還是需要一定的工作的。這些流量損失主要分佈在:
```
(1)某臺中間件所在的物理機突然宕機。
(2)中介軟體的升級和釋出。
```
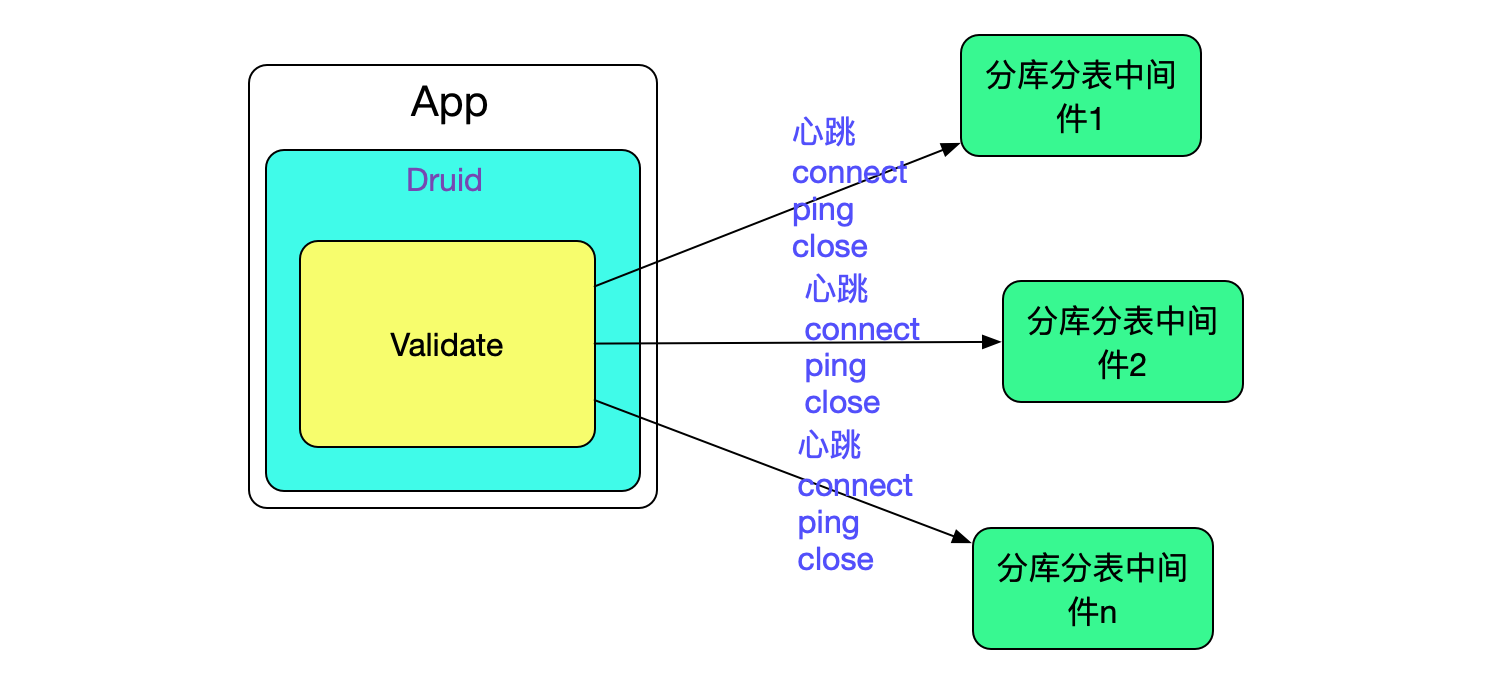
由於我們的中介軟體是作為資料庫的代理提供給應用的,即應用把我們的中介軟體當做資料庫,如下圖所示:

所以出現上述問題後,業務上很難通過重試等操作去遮蔽這些影響。這就勢必需要我們在底層做一些操作,能夠自動的感知中介軟體的狀態從而有效避免流量的損失。
## 中介軟體所在物理機宕機的情況
物理機宕機其實是一種常見現象,這時候應用一瞬間就沒了響應。那麼跑在上面的sql肯定也是失敗了的(準確來說是未知狀態,除非重新查詢後端資料庫,應用無法得知準確的狀態)。這部分流量我們肯定是無法挽救。我們所做的是在client端(Druid資料來源)能夠快速的發現並剔除宕機的中介軟體節點。
### 發現並剔除不可用節點
#### 通過心跳去發現不可用節點
自然而然的我們通過心跳來探查後端中介軟體的存活狀態。我們通過定時建立一個新連線ping(mysql的ping)一下然後立馬關閉來做心跳(這種做法便於我們區分正常流量和心跳流量,如果通過保持一個連線然後一直髮送類似select '1'的sql這種方式的話區分流量會稍微麻煩點)。
為了防止網路抖動造成的偶發性connect失敗,我們在三次connect都失敗後才判定某臺中間件處於不可用狀態。而這三次的探活卻延長了錯誤感知時間,所以我們三次connect的時間間隔是指數級衰減的,如下圖所示:
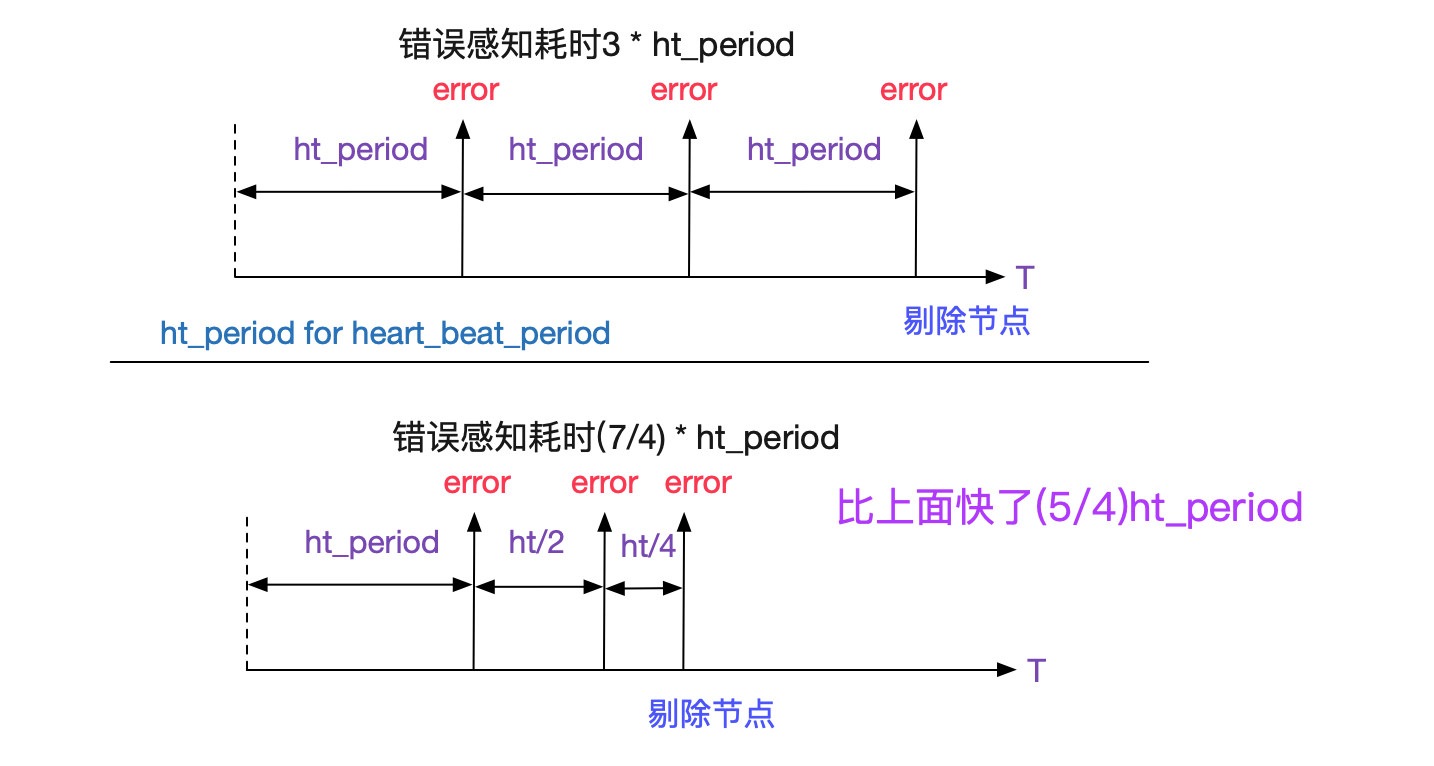
為何不在第一次connect失敗後,連續傳送兩次connect呢?可能考慮到網路的抖動可能會有一個時間視窗,如果在時間視窗內連續發了3次,出了這個時間視窗網路又okay了,那麼會錯誤的發現後端某節點不可用了,所以我們就做了指數級衰減的折衷。
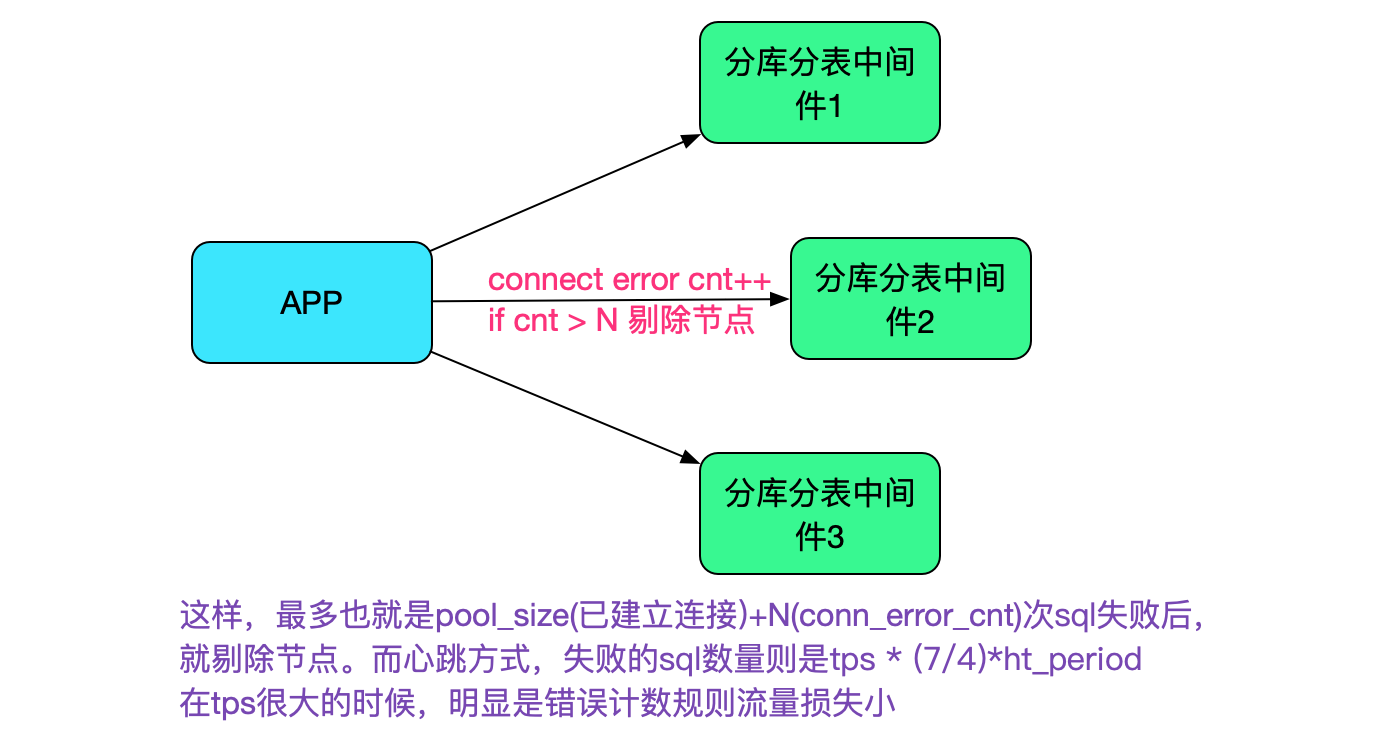
#### 通過錯誤計數去發現不可用節點
上述的心跳感知始終有一個時間視窗,當流量很大的時候,在這個時間視窗內使用這個不可用節點的都會失敗,所以我們可以使用錯誤計數去輔助不可用節點的感知(當然這個手段的實現還在計劃中)。
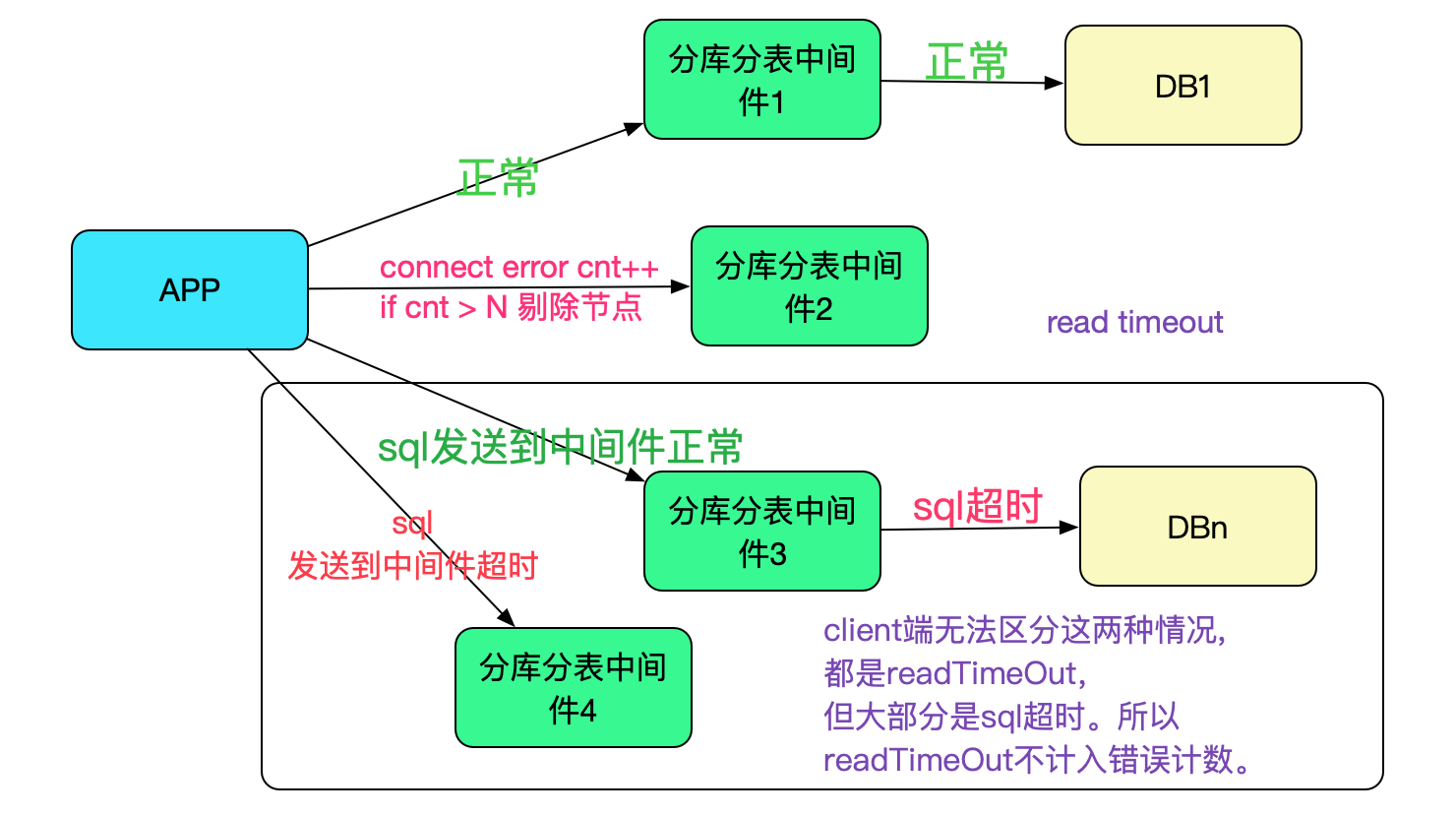
這邊有一個注意的點是,只能通過建立連線異常來計數,並不能通過read timeout之類的來計算。原因是,read timeout異常可能是慢sql或者後端資料庫的問題導致,只有建立連線異常才能確定是中介軟體的問題(connection closed也可能是後端關閉了這個連線,並不代表整體不可用),如下圖所示:
### 一個請求使用若干個連線導致的問題
由於我們需要保證事務儘可能小,所以在一個請求裡面多條sql並不使用同一個連線。在非事務(auto-commit)情況下,執行多少條sql就從連線池裡面取出多少連線,並放回。保證事務小是非常重要的,但是這在中介軟體宕機的時候會導致一些問題,如下圖所示:
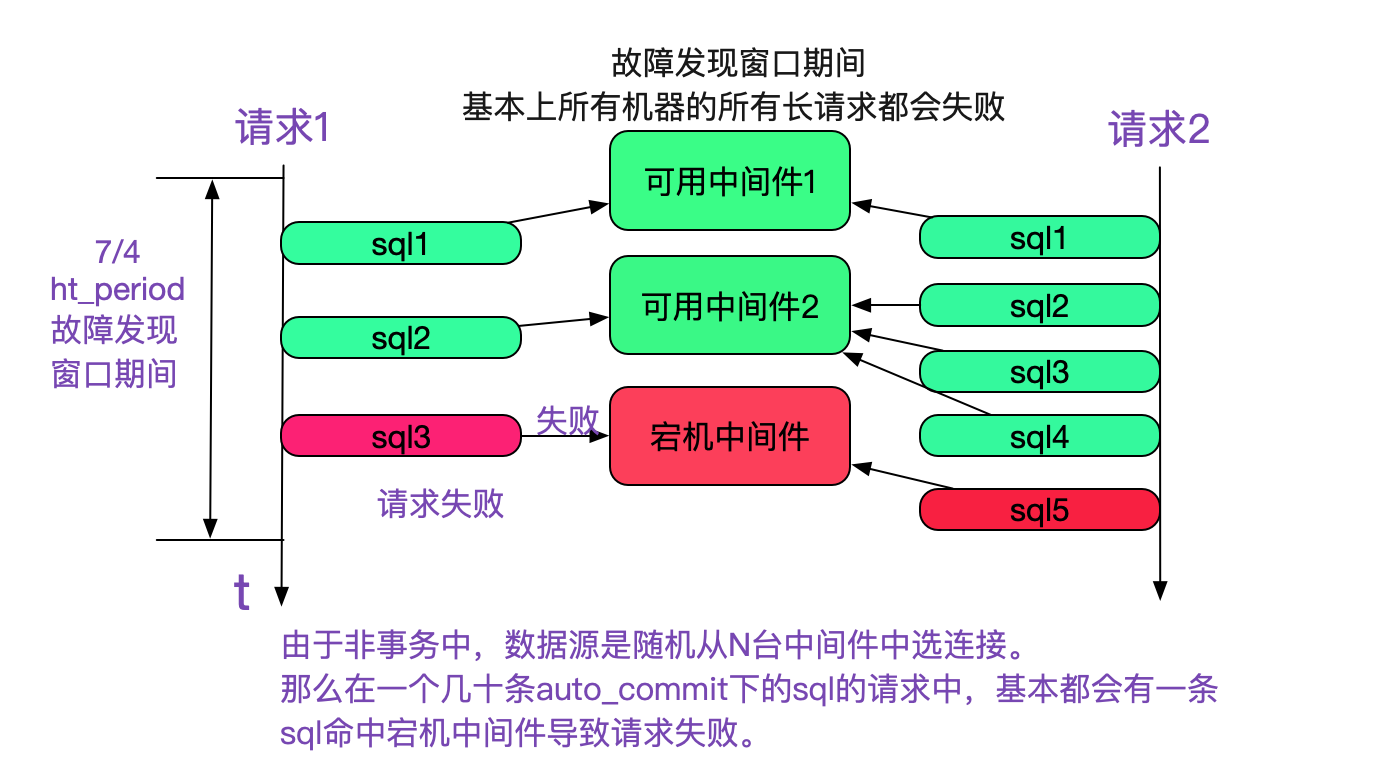
如上圖所示,在故障發現視窗期中(即還沒有確定某臺中間件不可用時),資料來源是隨機選擇連線的。而這個連線就有一定1/N(N為中介軟體個數)的概率命中不可用中介軟體導致一條sql失敗進而導致整個請求失敗。我們做一個計算:
```
假設N為8,一個請求有20條sql,
那麼在這個期間每個請求失敗的概率就為(1-(7/8)的20次方)=0.93,
即有93%的概率會失敗!
```
更為甚者,整個應用叢集都會經歷這個階段,即每臺應用都有93%的概率失敗。
一臺中介軟體宕機導致整個服務在十幾秒內基本所有請求基本都失敗,這是不可忍受的。
#### 採用sticky資料來源解決問題
由於我們不能瞬間發現並確認中介軟體不可用,所以這個故障發現視窗肯定存在(當然,錯誤計數法會在很大程度上縮短髮現時間)。但理想狀況下,宕機一臺,只損失1/N的流量就好了。我們採用了sticky資料來源解決了這個問題,使得在概率上大致只損失1/N的流量,如下圖所示:
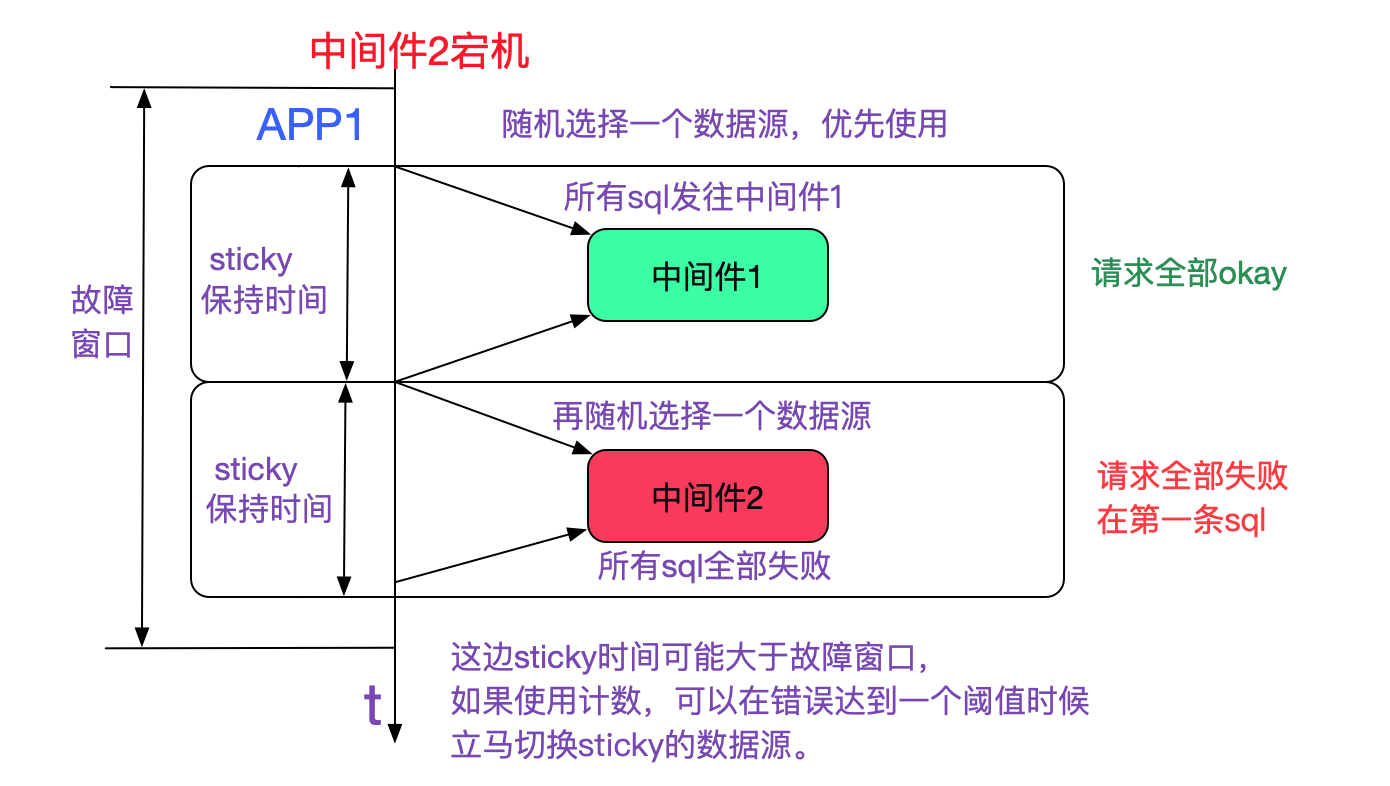
而配合錯誤計數的話,總流量的損失會更小(因為故障視窗短)
如上圖所示,只有在故障時間內隨機選擇到中介軟體2(不可用)的請求才會失敗,再讓我們看下整個應用叢集的情況。
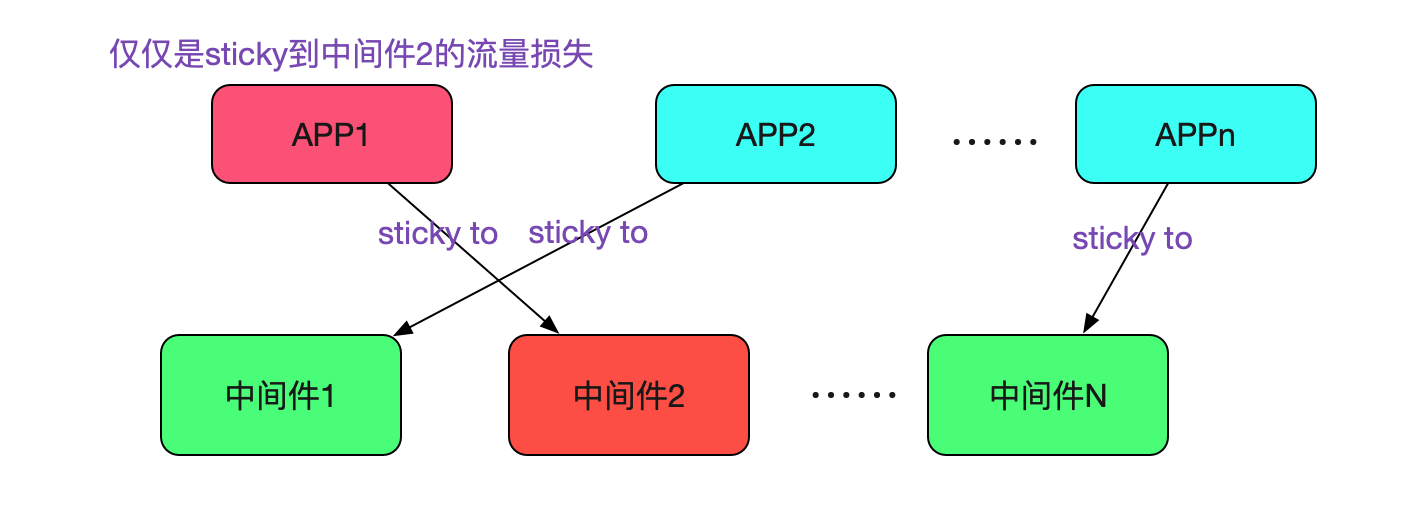
只有sticky到中介軟體2的請求流量才有損失,由於是隨機選擇,所以這個流量的損失應用在1/N。
## 中介軟體升級釋出過程中的高可用
分庫分表中介軟體的升級釋出不可避免。例如bug fix以及新功能新增等都需要重啟中介軟體。而重啟的時間也會導致不可用,與物理機宕機的情況相比是其不可用的時間點是可知的,重啟的動作也是可控的,那麼我們就可以利用這些資訊去做到流量的平滑無損。
### 讓client端感知即將下線
在筆者所知的很多做法中,讓client端感知下線是引入一個第三方協調者(例如zookeeper/etcd)。而我們並不想引入第三方的元件去做這個操作,因為這又會引入zookeeper的高可用問題,而且會讓client端的配置更加複雜。平滑無損的大致思路(狀態機)如下圖所示:
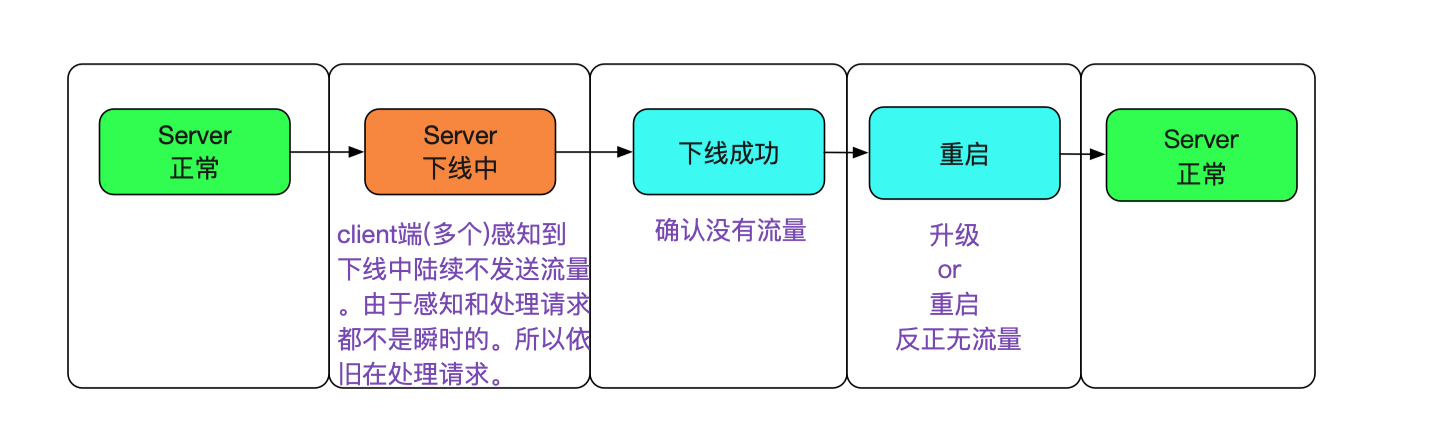
#### 讓心跳流量感知下線而正常流量保持
我們可以複用之前client端檢測不可用的邏輯,即讓心跳的新建連線失敗,而正常請求的新建連線成功。這樣,client端就會認為Server不可用,而在內部剔除調這個server。由於我們只是模擬不可用,所以已經建立的連線和正常新建的連線(非心跳)都是正常可用的,如下圖所示:
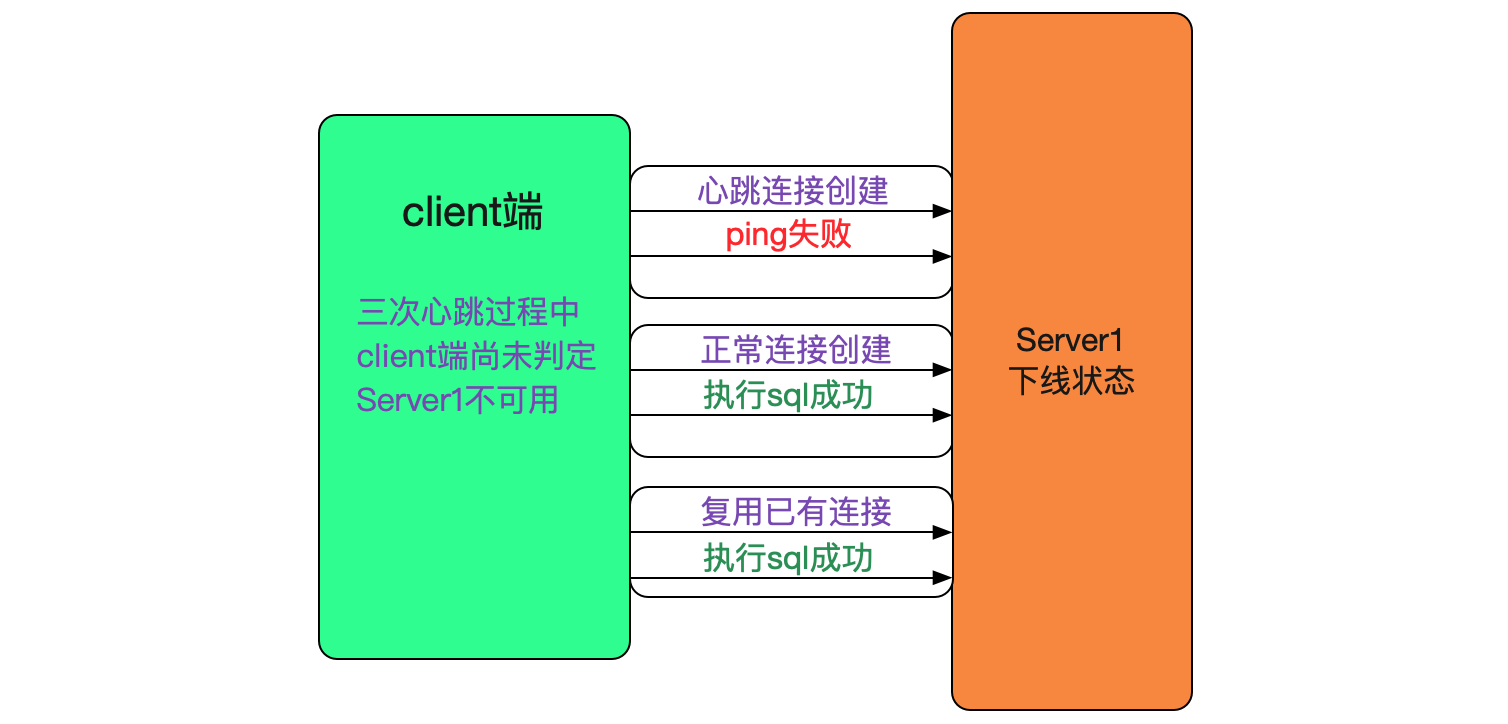
心跳連線的建立在server端可以通過其第一條執行的是mysql的ping而正常流量第一條執行的是一條sql來區分(當然我們採用的Druid連線池在新建連線成功以後也會ping一下,所以採用了另一種方式區分,這個細節在這裡就不闡述了)。
三次心跳失敗後,client端判定Server1失敗,需要將連線到server1的連線銷燬。其思路是,業務層用完連線返回連線池的時候,直接給close掉(當然這個是簡單的描述,實際操作到Druid資料來源也是有細微的差別的)。
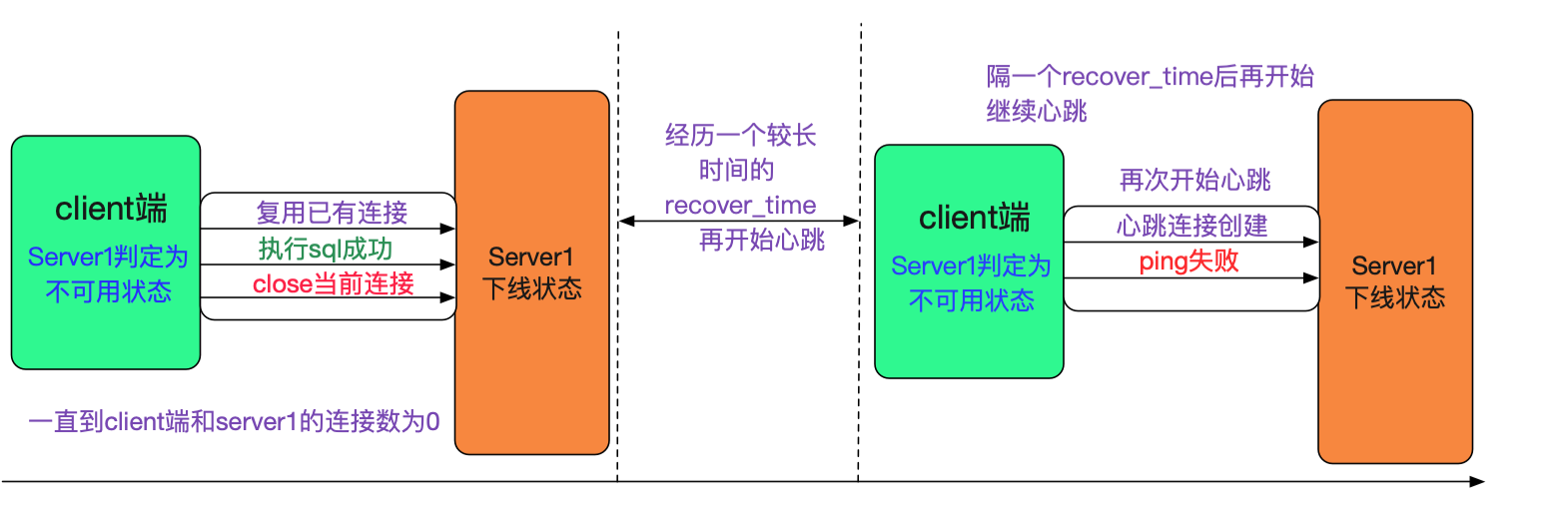
由於配置了一個connection最長保持時間,所以在這個時間之後肯定會對Server1的連線數為0
由於線上流量也不低,這個收斂時間是比較快的(進一步的做法,其實是主動去銷燬,不過我們尚未做這個操作)。
#### 如何判定下線Server再也沒有流量
在上述小心翼翼的操作之後,在Server1下線的過程中,是不會有流量損失的。但是我們在Server端還需要判定何時不會再有新的流量,這個判定標準即是Server1沒有任何一個client端的連線。
這也是上面我們在執行完sql後銷燬連線從而可以讓連線數變為0的原因,如下圖所示:
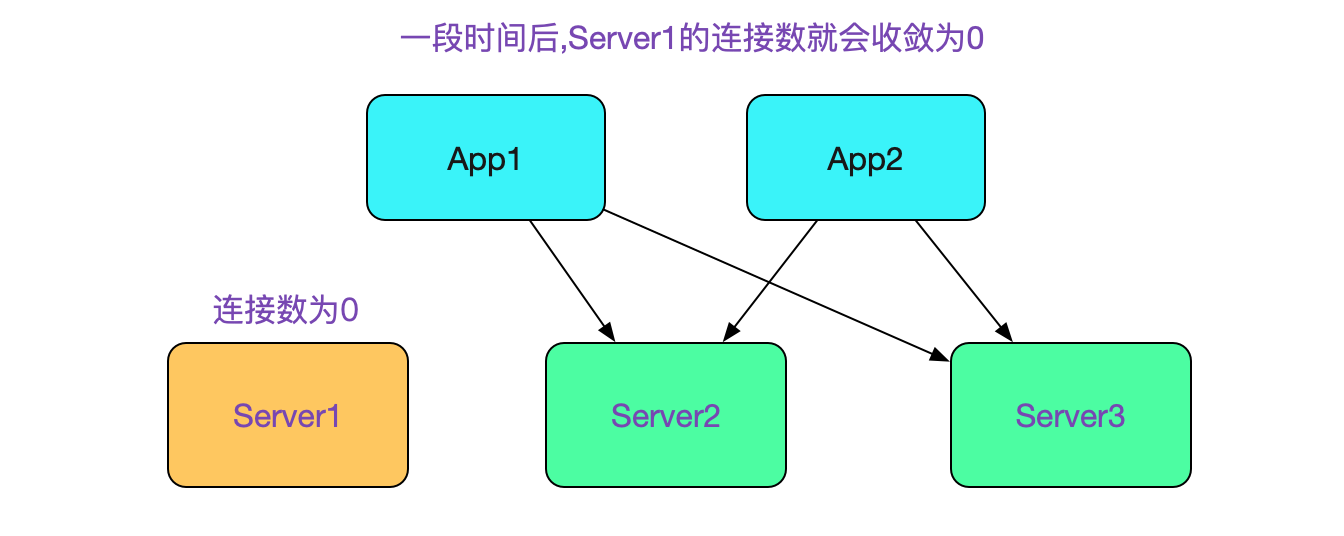
當連線數為0後,我們就可以重新發布Server1(分庫分表中介軟體)了。對於這一點,我們寫了個指令碼,其虛擬碼如下所示:
```
while(true){
count =`netstat -anp | grep port | grep ESTABLISHED | wc -l`
if(0 == count){
// 流量已經為0,關掉伺服器
kill Server
// 釋出升級伺服器
public Server
break
}else{
Sleep(30s)
}
}
```
將這個指令碼接入釋出平臺,即可進行滾動式上下線了。
現在可以解釋下recover\_time為何要較長了,因為新建連線也會導致指令碼計算出來的 connection count數量增加,所以需要一個時間視窗不去建立心跳,從而能讓這個指令碼順利執行。
#### recover_time其實是非必要的
如果我們將心跳建立的埠號和正常流量的埠號分開,是不需要recover\_time的,如下圖所示:
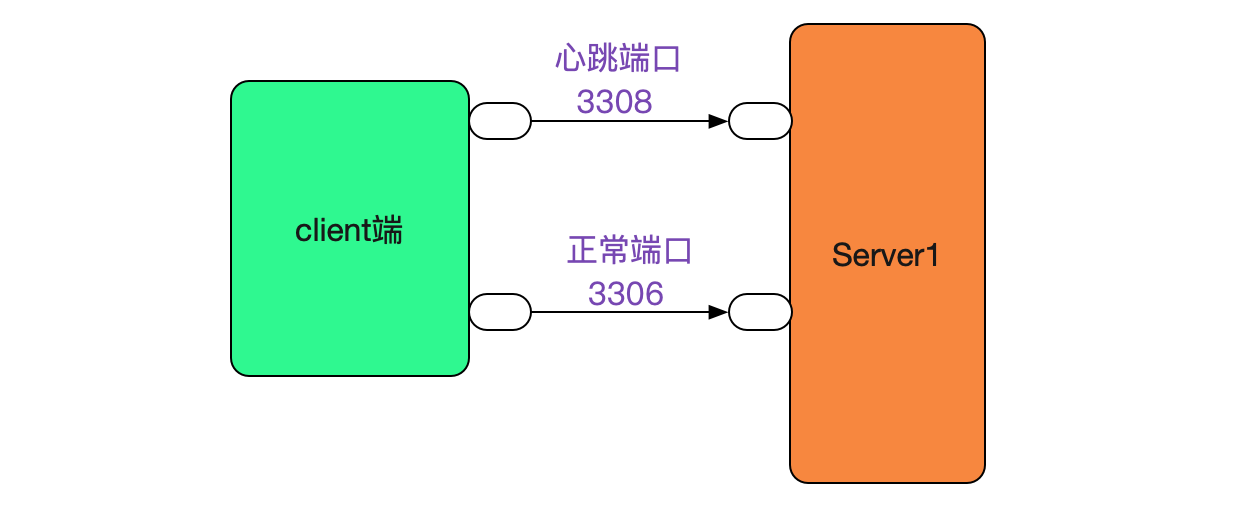
採用這種方案的話,會在很大程度上降低我們client端程式碼的複雜度。
但是這樣無疑又給client端增加了一個新的配置,對使用人員就又多了一個負擔,還得在網路上多一次開牆的操作,所以我們採取了recover\_time的方案。
### 中介軟體的啟動順序問題
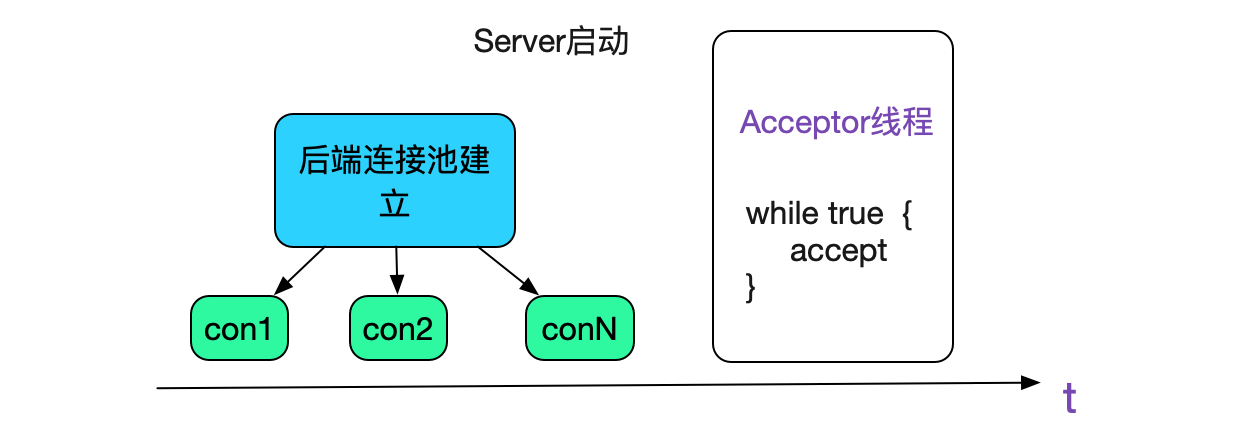
前面的過程是一個優雅下線的過程,但我們發現我們的中介軟體才上線的時候在某些情況下也不會優雅。即在中介軟體啟動時候,如果對後端資料庫剛建立的連線建立上去後由於某些原因斷開了,會導致中介軟體的reactor執行緒卡住一分鐘左右,這段時間無法服務,造成流量損失。所以我們在後端資料庫連線全部建立成功後,再啟動reactor的accept執行緒從而接收新的流量,從而解決這一問題,如下圖所示:
## 總結
筆者個人感覺高可用比高效能還要複雜。因為高效能可以線上下反覆的去壓測,通過壓測的資料去分析瓶頸,提高效能。而高可用需要應付線上各種千奇百怪的現象,本篇部落格講述的高可用方案只是我們工作的一小部分,還有很大一部分精力是處理中介軟體本身的問題上。但只要不放過任何一個點,將問題都能夠分析清楚並解決,就會讓系統越來越好。
## 公眾號
關注筆者公眾號,獲取更多幹貨文章:
