
資料處理-Spring Batch Scaling and Parallel Processing
承蒙各位擡愛,鄙人的一篇關於Spring Batch的部落格《Spring Batch之進階》有很多人瀏覽。說明有很多人工作中用到這個spring batch框架進行批量任務處理,也說明對這個框架還有不少不熟悉的地方,鄙人也是。That is to say,我們有必要加強學習,不然三天不學習,趕不上×××。這裡就來繼續說說Spring Batch Scaling and Parallel Processing那些事。這個標題的確不小,可伸縮和並行處理,的確是批量處理的很重要的特性,只有很好解決這些問題,才能成為一個完整的批量處理框架。本人GIT了一個專案:https://github.com/stylelyl/webatch.git
Spring Batch的官方說明文件:https://docs.spring.io/spring-batch/trunk/reference/html/scalability.html
Multi-threaded Step (single process)
Parallel Steps (single process)
Remote Chunking of Step (multi process)
Partitioning a Step (single or multi process)
一般來說,這四種是很重要的可伸縮和並行處理方式。我們可以:1,多執行緒(單程序) 2,並行步驟(單程序) 3,遠端步驟分塊(多程序) 4,分割槽步驟(單/多程序)。他們的優點自然不用多說,單程序處理的時候一個執行緒不能充分利用,那就啟動多個執行緒或者並行任務來處理,當然處理的任務之間是分隔的,結果直接不能有呼叫或者依賴關係(不要和我說到MR之類的處理,那是另外一回事)。還不夠,使用多程序來處理,即將任務分配到多個程序/節點上面來並行處理,或者將資料分割槽/片,綜合幾種方式來處理。下面按照這幾種方式來分別說下怎麼實踐。
1,Multi-threaded Step
這個文件上面說的很清楚,做起來也很簡單,在step定義的時候指定task-executor,預設使用的是SimpleAsyncTaskExecutor。如果每個執行緒都要讀資料庫,當然這個limit不要超過資料庫連線數。
<step id="loading">
<tasklet task-executor="taskExecutor" throttle-limit="20">...</tasklet>
</step>2,Parallel Steps
這個可以按照文件上面的配置:
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>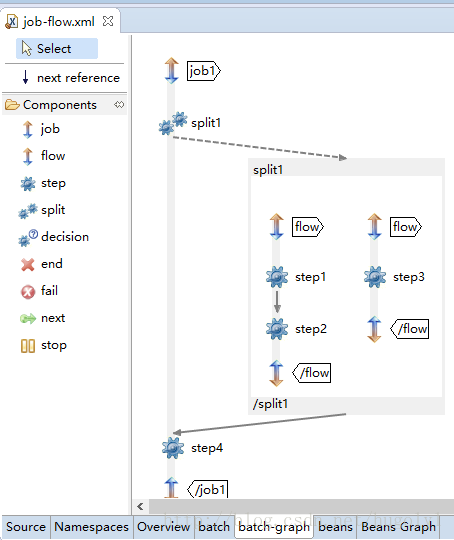
使用STS的外掛,來圖形化的看看處理的流程圖是什麼樣的。這樣看起來就是一目瞭然了。我們一般把可以同時並行跑的步驟分別通過split來並行來跑。
3,Remote Chunking
上面的文章裡面貼了Remote Chunking模式的處理流程。一般通過Master Step來獲取要處理的資料,然後把要處理的資料通過中介軟體分配給遠端的多個Slave程序,Master來跟蹤任務,根據最終處理的結果來決定步驟是不是處理完成了。如文件所說,The middleware has to be durable, with guaranteed delivery and single consumer for each message. JMS is the obvious candidate, but other options exist in the grid computing and shared memory product space (e.g. Java Spaces).
4,Partitioning
這個說白了就是通過PartitionStep來進行的,執行的時候,有兩個策略需要制定,PartitionHandler and StepExecutionSplitter,即怎麼進行分割槽處理和每個步驟裡面該怎麼跟蹤處理結果。這種處理方式和3的不同在於,分割槽的結果給slave的時候不需要持久化,在batch_step_execution和batch_step_execution_context裡面會儲存meta-data ,這樣來確保每個slave只執行一次。
具體的專案怎麼跑起來,不多說,說說裡面的幾個關鍵的類:
CardInfoPagingItemReader:這個類使用了DAO的方式來查詢,然後使用com.github.pagehelper來分頁。
KeyListReader:首先讀取所有的keys,loadKeys() 然後一條條記錄處理,loadItem(KEY key)
* 通過keyIterator來遍歷所有的keys