
數人云|12條軍規說Dev,3大重點講Ops——噹噹網的雲原生之路
8月19日數人云Meetup上來自當當網的高洪濤老師做了《噹噹雲原生DevOps實踐》的主題分享,從應用改造入手,重點講述了運維核心—監控的相關內容。
數人云提醒:8000字長文值得分享與收藏!
今天跟大家分享下,目前比較流行的雲原生概念個人關注要點:
- 首先:在於整個應用的改造,包括Infrastructure,有12個要素
- 其次:運維的核心——監控,主要講一下核心指標如何確定
- 第三:噹噹運維網路採用的Service Mesh架構相關內容
- 第四:日誌的蒐集等
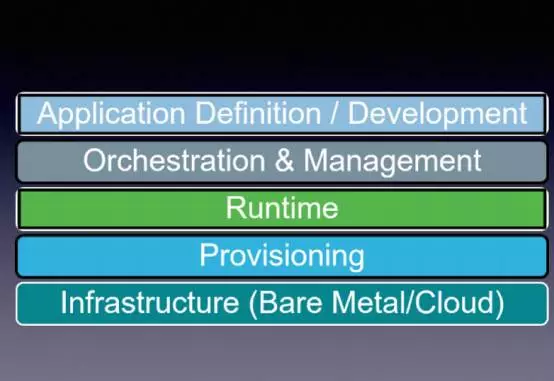
雲原生即Cloud Native,最早來源於如Landscape此類做微服務的公司,線路圖包括幾層:
第一層:應用的定義與開發,開發要符合雲原生的標準,如何讓應用在開發階段達到此標準,是本次分享首先要探討的內容。
第二層:編排和管理,大家對這個概念瞭解較多,如DCOS、Kuberentes、Mesos以及Docker Swarm,包括像Docker Conpose的一些配置化管理可能也會在編排裡。
第三層:執行態,環境從外部獲得相關的一些概念。
第四層:迷你環境的配置與安裝,一部分人可能原來用過,最早如Puppet、Self以及最近的Ansible,此類元件都會作為這一層使用。
最底層:普通的IaaS層、包括邏輯、運營商。
若應用符合多層的規範,即可輕鬆的橫向擴充套件、在不同雲間做遷移,能在公有或私有云上跑,但這比較難,因為很多應用上雲之前要經過改造,所以個人認為雲原生本身是對架構的挑戰,其讓應用可以在雲中間來回穿梭,而不會不適應。

上圖是網上的開源圖:Cloud Native Computing Foundation即常說的CNSAD,一個雲原生基金會組織,其實就是一些雲原生品牌大聯盟,若從上到下都使用此體系,那麼你也是雲原生的了。
例如,最左邊是語言,最頂級為GO語言,號稱最適合做微服務的語言,然後是一些編排工具:持續整合工具,以及比較流行基於服務的中介軟體,第二層編排工具,首先是Nginx,如常用的Mesos、Nomad,中間是配置工具:Etcd、ZK,後面是一些網路服務管理,噹噹使用比較多的是GRPC,以及本次分享會涉及到的Linkerd,它旁邊是Buoynt,也是Linkerd的開發者。
對於執行態來說,基礎的執行S3較為常見,如Docker、Rkt就是執行環境的容器,雲原生目前提供幾個方便的如CALICQ(噹噹目前正在研究),OVS,再底層是構建工具:如ANSIBLE。最底層如微軟的相關產品,AWS進入中國後發展也比較迅速。另外還有阿里雲、京東雲等類似的公有基礎服務平臺對外提供一些服務,供商家執行呼叫,以及一些邊緣服務,如Splunk、如噹噹的Elastic流水線。
雲原生應用的12條軍規
前面的整套產品線用下來,即可認為應用是雲原生的,而什麼是雲原生標準的套路呢?個人認為有12個因素,即雲原生應用的12條軍規,有些概念和微服務重合,但云原生的概念要大於微服務。
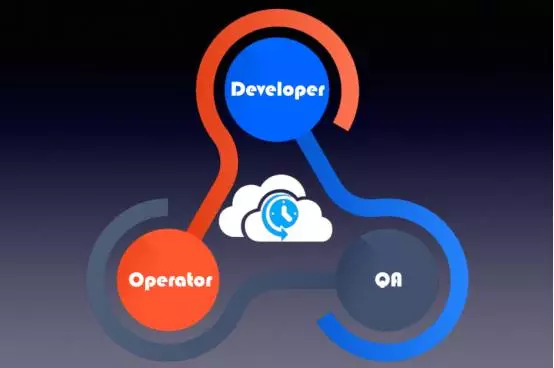
上圖是噹噹目前內部運維的作業平臺,整合了整個DevOps理念,有人講DevOps時首先強調的是Developer和Operater,但我認為其核心在於測試,噹噹內部以測試為核心帶動開發和運維,保證服務的可用性,三個團隊緊密配合將整個服務推向一個穩定的局面。
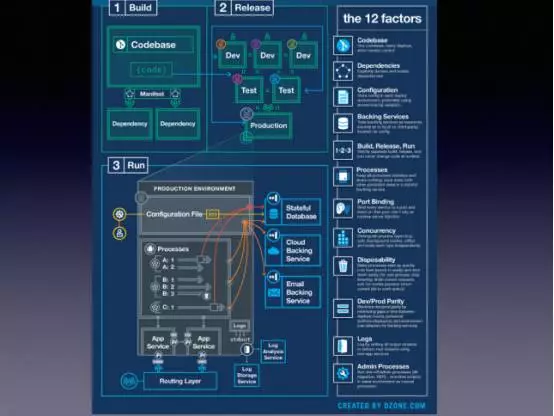
上圖是12條因素即12條軍規,這裡挑幾個重要進行講解:
Codebase:和整個測試環境有關,大家拉基線是為了整個版本的穩定性。
依賴:要解決依賴的問題,若用Java的話,意義不大,原始上會有依賴管理,但電商公司有各種語言都非常原始,直接依賴於原始碼,若其版本發生變化,有些API就編譯不過去。
Configuration:Java和其他語言非常衝突就在於此,做Java的同學都知道配置一般都會打在根應用的生產日報裡,會有大量的配置檔案,上到雲應用,讓底層人員執行作業炸包,首先就要配置檔案,一切配置要麼走配置中心,連訪問配置中心的地址可能也是外部注入進來,不用再去配置上宣告整個中心是什麼;要麼是所有的配置都由平臺幫助注入,不能自己攜帶相關的Jap去做,原來整個構建,底下會有一些構建的模式,之前構建最早版本非常有意思,比如大了一個測試環境的炸包,若沒問題,即可交給運維,因為配置VI裡面完全不一樣,會在應用和部署的公共機器時,有自動替換配置檔案的動作,要替換的配置檔案其實也是預先上傳到平臺上的,整個釋出平臺會幫助做一個配置檔案的替換,方式很原始,不是執行它去改配置,因為包本質上是變化的,配置檔案屬於包的一部分,因此它也是變動的,等於整個包的密封性被打破了,此時去上一個雲原生的平臺,首先要做的是滅配置檔案,要通過環境變數或啟動平引數的模式去啟動應用,這時平臺能自動地把整個環境——生產、預釋出、測試、以及延長等環境,將不同的配置設定好,所以這一點對開發來說改動比較大,正常上這種雲應用,最難的是將配置問題解決,因為大量的Java配置都是在檔案中進行,包括內部有框架的,特定的檔案,將這些都清除掉。
Backing Services:即不要把依賴服務完全寫死,依賴服務也是通過環境注入進來,如資料庫連線,可以通過外部配置進來。
構建、釋出和執行:要流程化。
程序:程序是微服務的根基,應用應以程序的級別執行,跟原來的方式不同,很多功能都是達到一個程序,通過不同的執行緒執行,但有幾個不好的地方,類似於微服務,釋出可能會影響不應影響的一些部分,追蹤也不是很好做,比如噹噹最近在做內部的Tracing,目前只能做到程序間的Tracing,如果內部的執行緒Tracing需要改造,還是有一些麻煩的。
埠:類似於一種埠的繫結解決方案,是由編排工具動態注入,要動態監聽一些要釋出的埠資訊。日誌:不應生成檔案,而是通過服務的方式將其進行傳遞,整個管理平臺應有自動收集日誌的功能,這也達到了雲原生的態度,要將所要定位的資訊不和應用綁在一起,因為應用很快會啟動或登出,那麼整個軌跡要持久化的保留,所以日誌是整個雲原生問題的核心,後面會進行詳細的講解。
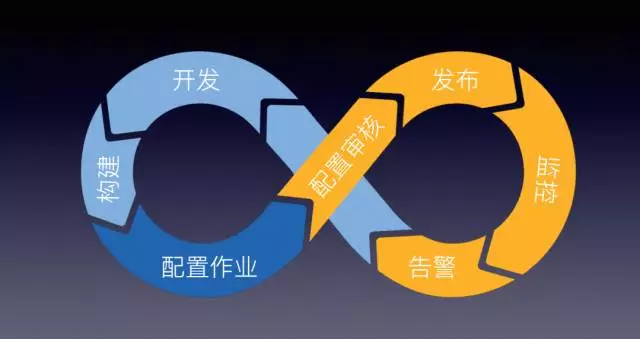
上圖是噹噹內部培訓的圖,淺藍色是線下操作,是在雲平臺之外的,因為都是第三方元件,包括開發、構建過程,接著在雲平臺上配置作業。藍色部分是開發或由測試提交,黃色部分由運維操作。團隊之間會通過這樣的配置去調整和稽核,控制整個平臺的用量,因為用Mesos跟Lite版本不一樣的地方在於宣告時要宣告CPU和記憶體,還會定義一些特性資源如:NFS,包括一些共享的儲存,這些會配置到配置裡,此時也要有一個稽核,讓其之間做個比較完美的互動。
監控——核心指標設定

上面講了Dev,剩下的幾個環節講一下Ops有關內容,首先:核心指標的設定。
上圖是我自己畫的雲圖,來源於Diggtal Dog網站,它有一篇Blog講運維監控指標,基本上是暗詞的權重,除了這個雲層,另外比較主要的是Mertics,其實應該過濾掉,如Error的數量,Success等各種指標,畫上圖最大的用意是讓大家看到——亂。
因為指標很多,Mesos所有的淨化API有20多個,它的指標可能有30—40個,但如此多的指標,每天都有大量的資訊,各個指標間有很多聯動關係,大資料可以去聯絡、判斷哪種指標在日常組合的情況下是影響系統發揮的,但目前的技術仍然難以做到,最簡單的方式是從這些紛繁的指標中找一個最適合自身的,在構建自身監控指標時,一定要找到一個上帝指標,若有人說,現在某個作業有問題,優先看這項指標,如果這個指標沒有問題,那麼狀況應該不大。
SLO=>SLA
這個指標其實就是SLA,使用比較多,SRE對SLO到SLA的推導是有過程的:SLO是服務質量的目標,在運維各個系統時,系統的服務質量需求不同,某人過來找你,某作業非常重要,如果一天不執行,會丟掉多少單,但若細聊,會發現每個人的服務指標不一樣,能忍受的指標也各不相同,跟他去歎號你的服務指標,是3個9、4個9或50%都可以,有些作業只要70%就夠,雖然偶爾失敗,或者70%的成功也不會影響服務,將SLO設定好,即可推到SLA是什麼,一旦確定,就是跟開發之間建立了一個生死契約,但跟市場不同,市場跟客戶籤,對方場上會寫個SLA,當然一般也不會去評估,開發不同,開發籤指標後,是要算績效的,所以一旦跟他說了能達到幾個9,就一定要做到,否則自己的獎金也發不出來。
好處是會約定雙方,開發不會提出過分的要求,比如偶然宕機,也不會找你,因為還未達到它的底線,如果有些嚴格指標,需要提供更好的服務給他,比如排程時會給他分配更好的伺服器,做一些預先的割裂,將其和一些作業隔離開。
SLA=ST/ET
SLA指標在做系統時要注意怎麼設定,平時方法很簡單,WEB應用很好設定,訪問10次,有9次返回404,那這個SLA才10%,但作業其實不好衡量,本來說是每5分鐘要執行一次,但如何衡量?是處理資料量的多少嗎?自己的指標需要自己去設定,這個是ST/ET,S是真正執行次數,即在10分鐘內根據表示式,成功執行多少次,是有標準的。E是期望這段時間內執行多少次,有一個口號表示式去計算即可在一個時間範圍內算出應該執行多少次,所以和一些應用不同,這個有平臺的特點,是針對定製作業設計的SRE指標。
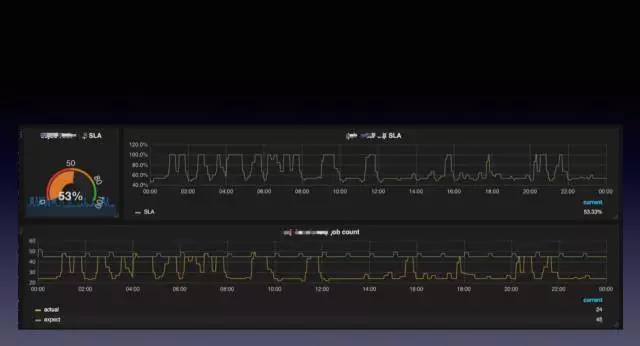
給大家分享一個例項,可以看到出了故障,目前已經降到53%了,具體的作業已經抹掉,由於自身寫錯應用有BUG,造成執行失敗,上面的曲線是Grafana的一個圖,整個SLA有時會100%有時會降到50%幾,下面是用來顯示SLA如何計算的綠線,可見除了偶爾波動外,比較均勻。底下這條線是實際執行次數,偏離度較大,因此可以得出,在哪個時間段出了問題,幫助進一步定位。
所以關鍵的監控指標,對於輕量級監控是非常重要的,為什麼只抓一個指標就夠?Mesos給的官方建議是如果叢集內的任務快速失敗,就會報警,噹噹基於此建立了報警,有時會出現報警,查一下這個指標,如果沒有問題,就可以認為是由於偶然的情況下做了一些失敗的專一,不會有太大的影響,這就是設定關鍵指標的好處。
監控——監控監控系統
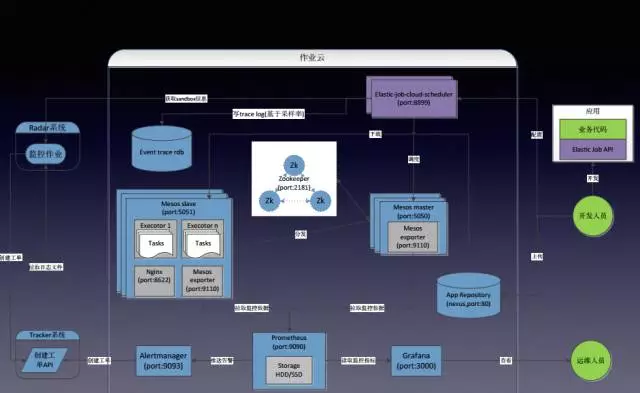
監控系統是否需要被監控?這是一個老生常談的問題,首先監控系統也是系統,是需要被監控的。這裡進行一下反推,如果監控系統萬一Down了就只能再加一層了,下面是Prometheus去採集整個Mesos叢集的白核監控資料,發給Master做告警,接到內部的Tracker的系統會根據告警級別去傳送郵件、簡訊或電話。上面有個叫雷達的系統,目前監控整套的監控系統,已經用了很多年,因為Prometheus也是整套的監控系統,再由它去監控一個監控系統,如果雷達也Down怎麼辦?不管做了HA或其他,仍然會有Down的機率,但如果兩個系統同時Down了呢?
大家可以回溯一下剛才講過這個問題,監控系統本身也是一個系統,到底要提供多大的SLA,要提供對外監控4個9的目標嗎?另外上一套系統可以保證4個9,因為每套系統每年都會算一個SLA,將這個指標用上去以後,系統的可用度會上升,所以對系統的可用要量化、要度量,系統只要能用目前的方案達到SLA設定的目標,就可以停了,如果達不到就不能停。
再回到上面這個圖,後來之所以加了一檔,因為Prometheus最早上線那版,為了塊它是個單點,無法保證執行緒目標,所以又加了一套監控系統,如果將Prometheus、Alertmanager在一開始就構建比較完整的服務,那麼可以不用第二層監控。
Service Mesh實踐
接下來是Service Mesh,APM 最近在北京召開,這是一個全國比較大型的監控告警的會議,會上當當總監講了一下這個概念,這概念是當時運營整個Mesos的後臺,引用到內部服務範根的,所以再給大家案例一下相關的技術。
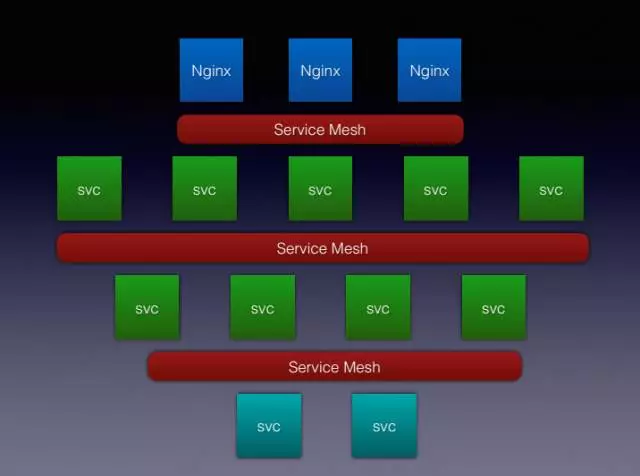
上Kubernetes或Mesos叢集的話,都會遇到一種網路問題,如果對容器的編排排程都感興趣,可以在網上搜:Kubernetes網路、容器網路、會有一大堆的概念,上去會告訴你OAS怎麼配,FLANNEL效能會損失多少,Calico怎麼用的BTP協議,其實剛才看了第一個圖,將的網路其實解決的是整個網路IP層的問題,會讓機器有多少個IP,為什麼要解決IP層的問題呢,因為因為容器。比如一臺容器一驅10,一驅12,一1驅15可能是最高的,原來有1萬的叢集節點,那麼現在要乘10,網路規模翻了10倍,IP地址同樣也翻了10倍,所以一些公有云的同志們會非常恐慌,因為最早的虛擬協議支援不了這麼多的節點,因此提出了容器網路,包括CNI、CNM的標準,賬戶要解決IP不夠用的問題,其實這個網路還有另外一套問題:容器起來後IP也會變,會有一些別的技術保證IP也會變,那服務要怎麼辦?如何去發現,如果後臺比如有10個WEB應用去訪問,此時如何去負載均衡,如果有個服務長時間有問題,如何提供整個服務叢集,如何做熔斷,這些都是微服務常見的網路概念。
Service Mesh主要就是解決者方面的問題,即使底層用最原始的完全不用它自身的網路方案,照樣可以使用,如圖,最外層如Nginx,作為一個邊緣節點,會將流量通過Service Mesh打到叢集內部的服務,它們之間也通過Service Mesh互相訪問,然後叢集外面來說,換成淡藍色不能用外部服務,就是通過Service Mesh向外去訪問。
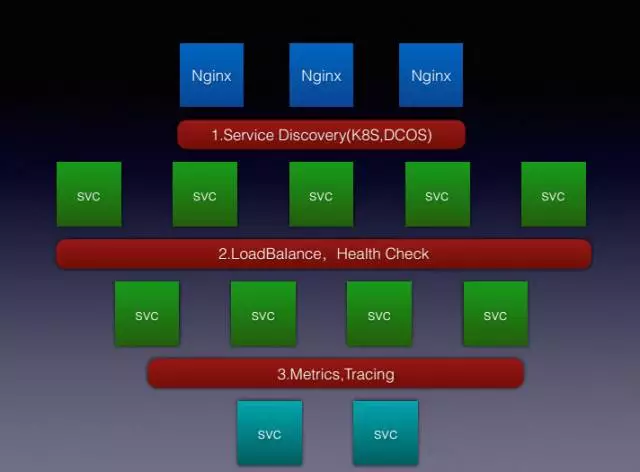
這裡總結了三點功能:
第一點是Service Discovery即服務發現,和正常的如微服務的發現不太一樣,微服務發現用Cloud基本上也會存一些中間的儲存,ETCD比較多,包括DK,Consul這些,有人用Redis也存過,怎麼也得把服務之間的呼叫關係存起來,這個Service Mesh大多是從第三方平臺獲得服務之間的IP地址和聯絡,第三方平臺包括Kubernetes,包括這裡寫的DCOS,DCOS是另外一個概念,即Mesos加Marathon再加一套新構建的元件,合起來可能就是DCOS,從這裡面把相關的服務資訊採集出來就能做服務發現,比如註冊個應用,每次啟動時,這個應用本身的IP地址,可能埠通過Mesos或Nginx分配的很明顯,因此如Linkerd、Istio就可以把IP地址獲取下來,當你訪問時元件是知道的,這是它大部分做服務發現的原理。
第二點是負載均衡和健康檢查,上面說過,一個服務可能是3個例項、10個例項去對外提供服務,那本身應用基本軒哪個服務就涉及到負載均衡,如果應用上調不通,會踢出叢集,這就是健康檢查。這部分可能分為兩大流派,第一大流派是做使用者層的,就是七層負載,比較傳統,我們用的跟NG差不多,因為我們還會有其他別的資訊;另外一種是使用本地IP Temple進行轉發,此時更像原生的另外一個部署模式,包括像DCOS本身有一個Minuteman的元件,轉發的速度會很快,但這種有一個問題,服務失敗就是失敗了,通過這個端自己增加處置機制,還有HA的功能也不能做,所以它有一些限制。
最後比較重要的是Metrics和Tracing的對外暴露,像是這種新一代服務的元件,對外暴露各種Metrics的指標,如Linkerd,包括Istio都會暴露Prometheus的這些監控,還會自帶一些Tracing的功能,是一種廣播級的追蹤,linkerd目前只能支援一種,因為它來自推特,推特的元件叫ZK,Tracing技術比較特別,需要修改服務的Hander,然後去加一些額外的資訊,因此雖然Linkerd在官方主頁上公開了Metric,比如說Tracing是外掛式的,但需要Tracing的服務去支援SPIN的協議才可以,這個比較坑。我目前正在給我們用的Tracing的截殺軟體,會截掉一部分Linkerd的Scalar程式碼,將它的整個Hunter協議改掉,這樣才能支援別的協議模式,目前正在內部試執行,後續用Linkerd較多的話,會向它提一些PR,讓它將整個Tracing開源。
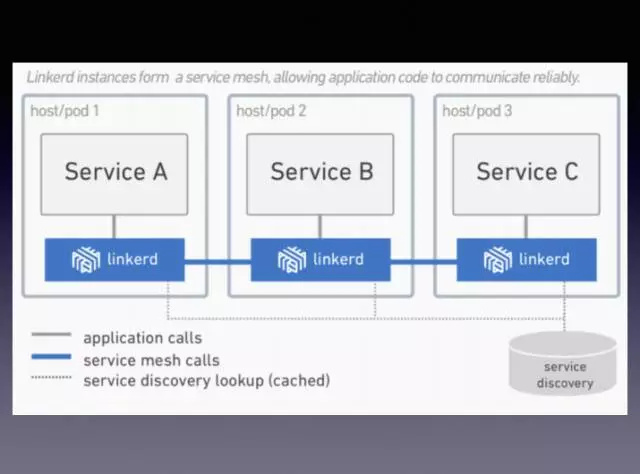
這是在官網上截的一個圖,可以讓大家更深刻地理解,用過Kuber-Proxy的同學知道,這是和它一樣的,在機器上,服務過來先找它,通過代理模式再打到另外一臺服務的Linkerd,每次的服務訪問,被訪問其實都是通過本地的其他技術去發起的。
目前在跟進Skywalking,它是另外一個開源組織。不知道大家對Tracing有多少了解,要不是用手工的方式將監控資料往外發,如果不想修改程式碼,目前只能用Java,要根據不同元件做埋點,需要看埋點外掛的豐富度了,但埋點了以後會對效能稍微有一些影響,目前做的事是將整個Tracing的外掛直接做到Linkerd上,服務之間呼叫,可能整個Tracing圖沒有了,但整個訪問統計還在,因此這個意義很大,如果完全不想動程式碼的結構,直接上我們的整個元件,自身就帶了Tracing的過程。
離線與線上日誌
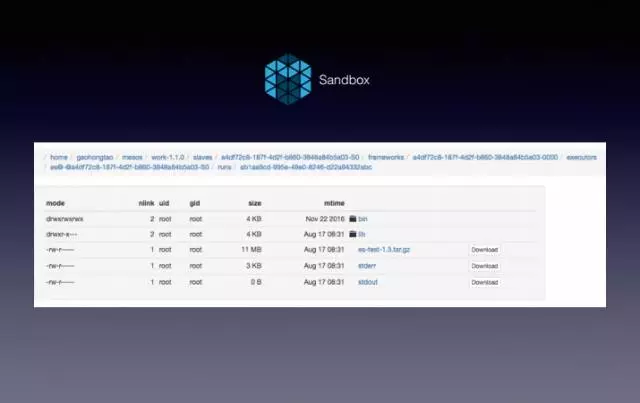
離線和線上日誌目前也是雲原生比較重要的一環,先解釋下Mesos Sandbox,Mesos會把待執行的包下載到本地,生成一個臨時目錄,目錄很長,有很多CP數,這裡面就是Sandbox,原理和Docker一樣。日誌要打到Sandbox裡,否則就沒法看到日誌,可能有些人原來不應用,會打到某些固定的路徑,這時會要求打到相對應的路徑裡,此時會提供兩個檔案:STD error、STD on,把標準輸入和標準輸出寫到這個檔案裡。噹噹目前只採集標準輸出或標準出錯,所以原來如果寫了一些特定格式的日誌,會被要求改掉,其實開發還是很高興的,因為開發環境一般都是標準輸入和標準出錯的,開發那套關於日誌配置不必修改,直接打到包裡,上面說第一步要改應用,首先把配置去檔案化,日誌的配置不用改,因為線上也只採集這兩個檔案。
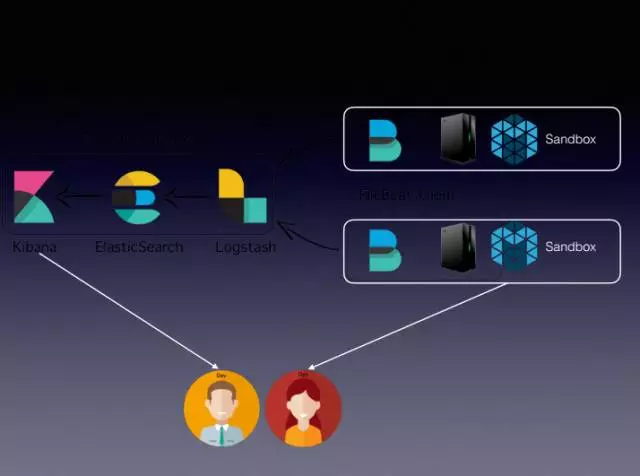
流程從右向左,Filebeat目前是整個叢集比較常用的元件,Logstsh是一個Transform,發到Elastic Search裡,最後有Kibana提供服務,中間緩衝用的是卡夫卡,此時運維和開發都可以通過兩種模式看日誌,日譯中模式是直接訪問剛才的Sandbox,訪問的頁面通過整個運維平臺,直接點到頁面裡面。
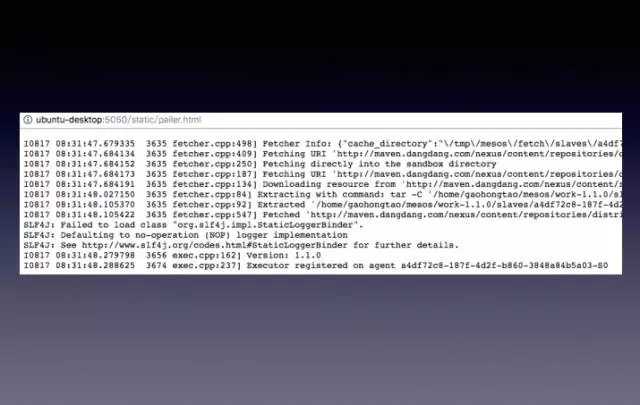
另外通過ERK平臺,線上看日誌可能類似於上圖這樣一種格式,一行行打印出來,然後web頁面能自動滾動,可以看一些即時日誌。
搜尋統計還是走Kibana,上圖是測試環境的Kibana,會統計一些相關的日誌指標。
高洪濤老師將多年的運維及開發相關想法融入到本次演講當中,如雲原生應用的12條軍規,噹噹監控指標制定規則,以及噹噹網的Service Mesh實踐進行了詳細地分享,小數希望大家在看完這篇長文後能夠有所收穫。