
類C語言編譯器設計、原始碼及資料彙編(一)
我相信有不少的人對編譯器的有很大興趣,但是虎書(《編譯原理》)上的理論知識雖然很全面很詳細,但是相當的枯燥無味,讓人難以下決心鑽研。我就是被虎書嚇壞了,各種看不懂(本人非CS專業,全靠自己啃)。。。《程式語言設計》也太厚了,後來在圖書館找書的時候,發現了一本適合入門PLT的書籍,擁有基本的C語言、作業系統和資料結構的功底就能完全看懂的書籍。這本書叫《自己動手寫編譯器連結器》,建議想了解PLT的可以認真鑽研,可以對編譯原理有個初步的概念。大概花了兩個月的時間(邊實習邊學習)完成了這個玩具,編譯器的大部分核心是來自《自己動手寫編譯器連結器》這本書,自己也加入了一些其他的想法,另外本文分為幾篇完成,主要給一些摸索中的人提供一些資料,也是對自己的一個總結,如果有不正確的地方還請見諒和指點。github地址(
注意:本文是進行設計和原始碼上的大致總結,不是詳細的解讀原始碼,也不是手把手從頭寫起。如果需要深入瞭解原始碼,請閱讀書籍。另外本文將在結尾總結處,給出蒐集的編譯原理、編譯器相關的資料。
好了,介紹下這個玩具,主要採用了C語言和C#為開發語言,XML為檔案配置語言,開發工具為VS2015,設計的語言是C語言的一個子集,支援C語言的大部分,支援專案和單檔案的編譯(當然很簡陋的)。C語言是寫編譯核心的,C#主要寫UI,顯而易見是Windows平臺了,下面進行詳細介紹。
1.語言的描述和定義
Via-C是C語言子集,採用的是ASCII序列。其定義在C語言(C89)的基礎上,簡化了C89的一些細節,加入了其他的一些功能。Via-C不同於C語言必須使用分號分隔語句序列,也支援指令碼格式的風格,無需行結束符。

可以在上表中看出,同C相比多了幾個關鍵字,其餘大多數意義是類似的。其中do和end是代表程式碼塊開始和結束,可以和{}(大括號運算子)一起使用。require時用來載入標頭檔案,和include一致。
C89的規定中只是支援了程式碼塊註釋方法,Via-C添加了註釋行的功能。其他和C語言基本是一致的,如函式、表示式或者是識別符號等等,但不支援巨集定義。下表解釋了Via-C語言的運算子的優先順序。

另外Via-C編譯器的獨立檔案格式為.viac,專案檔案格式為.viacproject。
2.編譯器的定義
通常編譯器的邏輯層次可以分為前端和後端。前端可以分為詞法分析器等部分,後端包括了程式碼生成器和中間程式碼優化等部分。記住連結器並不屬於編譯器,這個小玩具也加入了連結器。本玩具(以下稱Via-C編譯器,原諒我不要臉)分為了詞法分析器、語法分析器、語義分析器、程式碼生成器和中間程式碼優化、連結器、UI周邊功能,這六大部分分別承擔不同的任務,各部分獨立又各有聯絡(見下圖,來自《自己動手寫編譯器連結器》)。下面將根據層次邏輯順序逐一進行介紹。

2.1詞法分析器
詞法分析是邏輯順序結構的第一步。任何的程式碼都是字元按照一定的順序排列而成,當掃描完程式後,需要憑藉相關規則進行分割,形成獨特的記號(類似於單詞),再將辨別的記號經過編碼形式輸出。但是詞法分析器不保證單詞之間的任何關係。詞法分析器流程如圖。

詞法分析器流程圖
以下進入相關的實現步驟。
2.2單詞編碼
源程式中可能有許多的單詞,這時就需要單詞編碼來進行管理。單詞編碼採用的是列舉型別,這樣在檢視和使用編碼資訊會更加便利。Via-C語言的單詞編碼對關鍵字和運算子都進行了編碼,詳情見程式碼中的lex.h中的enum e_TokenCode型別。
2.3建立資料結構
在進行詞法分析時需要大量的資料結構,在進行詞法分析之前需要先準備基本的操作,故定義了下列幾種資料結構。
採用雜湊表是由於在分析的時候中需要使用大量查詢操作。雜湊表需要雜湊函式去計算雜湊值得到關係,雜湊函式的作用是將關鍵字的集合經過某種運算對映至某個地址的集合上。在本設計中使用了UNIX系統中的ELF_Hash函式,具體實現見compile.h檔案。雜湊函式實現如圖所示:

雜湊函式的定義
Via-C語言是以連續的字元流表示,需要大量的字串處理,而且單詞的長短不一,自定義一個動態字串來進行字串處理是有必要的。動態字串定義如下:
typedef struct String
{
int count; //字串長度
int capacity; //字串緩衝區
char* data; //字元指標
}String;//(見string.h)並且定義了一系列的操作函式見(string.h)。

動態字串操作函式
單詞的個數是無法預知的,為了滿足後續操作的空間記憶體的需要,也建立了動態陣列的定義。動態陣列定義如下:
typedef struct Array
{
void** data; //指標陣列
int count; //元素個數
int capacity; //緩衝區
}Array;//(見array.h)動態陣列操作函式如圖。

動態陣列操作函式
下面介紹單詞表的定義,單詞表是由動態陣列和雜湊表複合構成。
typedef struct TkWord
{
int tkcode; //單詞編碼
struct TkWord* next; //雜湊衝突的同義詞
char* spelling; //單詞字串
struct Symbol* sym_struct; //單詞的結構定義
struct Symbol* sym_id; //單詞的識別符號
}TkWord;單詞表初始化時對關鍵字和運算子進行了特殊處理,使得它們提前進入單詞表。在詞法分析程式中能快速查詢到一個引用在記憶體中的位置,進行引用。
下圖是單詞表的一系列操作函式的宣告。

單詞表操作函式
2.3詞法分析器控制程式
以上完成了相關的預備工作,接下來開始控制程式的介紹。
下列是字元讀取函式:
void GetCh(){
ch = getc(fin); //fin為檔案描述符
}讀取字元後,需要在單詞表中識別是否為單詞表成員。因此接下來是單詞分割程式,主要識別運算子、變數、關鍵字,函式名為GetToken(見lex.c)。
預處理程式主要是忽略註釋和空白字元、換行符等(見lex.c)。
剩下皆是一些解析函式和詞法著色程式,基本上完成了該階段邏輯的編寫工作,見lex.c。
2.4詞法分析器的測試
進行單元測試,以下圖是詞法分析的成果。
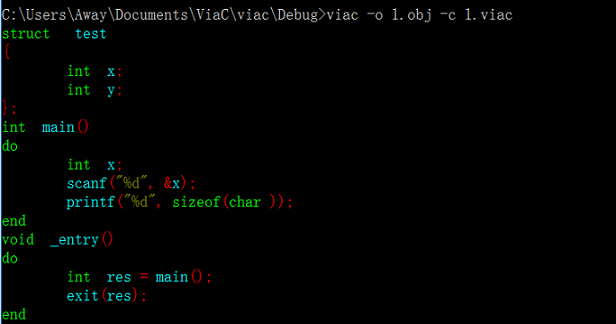
詞法分析成果
從上圖可以看出對關鍵字、識別符號、字串的分別著色,說明詞法分析器工作正常,Via-C編譯器的第一階段分析大功告成。
今天就寫到這吧,明天繼續。以上的程式碼均可在github上。