
Map Join和Reduce Join的區別以及程式碼實現
MapReduce Join
對兩份資料data1和data2進行關鍵詞連線是一個很通用的問題,如果資料量比較小,可以在記憶體中完成連線。
如果資料量比較大,在記憶體進行連線操會發生OOM。mapreduce join可以用來解決大資料的連線。
1 思路
1.1 reduce join
在map階段, 把關鍵字作為key輸出,並在value中標記出資料是來自data1還是data2。因為在shuffle階段已經自然按key分組,reduce階段,判斷每一個value是來自data1還是data2,在內部分成2組,做集合的乘積。
這種方法有2個問題:
1, map階段沒有對資料瘦身,shuffle的網路傳輸和排序效能很低。
2, reduce端對2個集合做乘積計算,很耗記憶體,容易導致OOM。
實現程式碼如下:
主程式入口程式碼:
package com.ibeifeng.mapreduce.join; import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.task.reduce.Shuffle; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class MapReduceJoin extends Configured implements Tool{ //定義map處理類模板 public static class map extends Mapper<LongWritable, Text, IntWritable, DataJoin>{ private IntWritable outputkey = new IntWritable(); private DataJoin datajoin = new DataJoin(); protected void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException { //1.獲取字串 String str = values.toString(); //2.對字串進行分割 String[] value = str.split(","); //3.對非法資料進行過濾 int len = value.length; if(len!=3&&len!=4) { return; } //4.取出cid String cid = value[0]; //5.判斷是是customer表還是order表 if(len == 3) { //表示是customer表 String cname = value[1]; String cphone = value[2]; datajoin.set("Customer", cid+","+cname+","+cphone); } if(len == 4) { //表示是order表 String oname = value[1]; String oprice = value[2]; String otime = value[3]; datajoin.set("Order", cid+","+oname+","+oprice+","+otime); } outputkey.set(Integer.valueOf(cid)); context.write(outputkey, datajoin); } } //定義reduce處理類模板 public static class reduce extends Reducer<IntWritable, DataJoin, NullWritable, Text>{ private Text outputvalue = new Text(); @Override protected void reduce(IntWritable key, Iterable<DataJoin> values, Context context) throws IOException, InterruptedException { //定義一個字串用於儲存客戶資訊 String customerInfo = null; //定義一個List集合用於儲存訂單資訊 List<String> list = new ArrayList<String>(); for(DataJoin datajoin : values) { if(datajoin.getTag().equals("Customer")) { System.out.println(datajoin.getData()); customerInfo = datajoin.getData(); } if(datajoin.getTag().equals("Order")) { list.add(datajoin.getData()); } } //進行輸出 for(String s :list) { outputvalue.set(customerInfo+","+s); context.write(NullWritable.get(), outputvalue); } } } //配置Driver模組 public int run(String[] args) { //1.獲取配置配置檔案物件 Configuration configuration = new Configuration(); //2.建立給mapreduce處理的任務 Job job = null; try { job = Job.getInstance(configuration,this.getClass().getSimpleName()); } catch (IOException e) { e.printStackTrace(); } try { //3.建立輸入路徑 Path source_path = new Path(args[0]); FileInputFormat.addInputPath(job, source_path); //4.建立輸出路徑 Path des_path = new Path(args[1]); FileOutputFormat.setOutputPath(job, des_path); } catch (IllegalArgumentException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } //設定讓任務打包jar執行 job.setJarByClass(MapReduceJoin.class); //5.設定map job.setMapperClass(map.class); job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(DataJoin.class); //================shuffle======================== //1.分割槽 // job.setPartitionerClass(MyPartitioner.class); //2.排序 // job.setSortComparatorClass(cls); //3.分組 // job.setGroupingComparatorClass(MyGroup.class); //4.可選項,設定combiner,相當於map過程的reduce處理,優化選項 // job.setCombinerClass(Combiner.class); //設定reduce個數 // job.setNumReduceTasks(2); //================shuffle======================== //6.設定reduce job.setReducerClass(reduce.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); //7.提交job到yarn元件上 boolean isSuccess = false; try { isSuccess = job.waitForCompletion(true); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } return isSuccess?0:1; } //書寫主函式 public static void main(String[] args) { Configuration configuration = new Configuration(); //1.書寫輸入和輸出路徑 String[] args1 = new String[] { "hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/wordcount/input", "hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/wordcount/output" }; //2.設定系統以什麼使用者執行job任務 System.setProperty("HADOOP_USER_NAME", "beifeng"); //3.執行job任務 int status = 0; try { status = ToolRunner.run(configuration, new MapReduceJoin(), args1); } catch (Exception e) { e.printStackTrace(); } // int status = new MyWordCountMapReduce().run(args1); //4.退出系統 System.exit(status); } }
自定義包裝類程式碼:
package com.ibeifeng.mapreduce.join; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; public class DataJoin implements Writable{ private String tag; private String data; public String getTag() { return tag; } public String getData() { return data; } public void set(String tag,String data) { this.tag = tag; this.data = data; } @Override public String toString() { return tag+","+data; } public void write(DataOutput out) throws IOException { out.writeUTF(this.tag); out.writeUTF(this.data); } public void readFields(DataInput in) throws IOException { this.tag = in.readUTF(); this.data = in.readUTF(); } }
準備測試資料如下(兩個csv檔案):
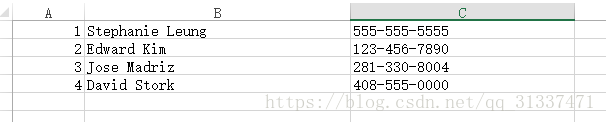

將csv檔案上傳至HDFS當中,並且將程式碼打包成jar,然後執行以下命令:
bin/yarn jar datas/mapreduce_join.jar /user/beifeng/wordcount/input/ /user/beifeng/wordcount/output
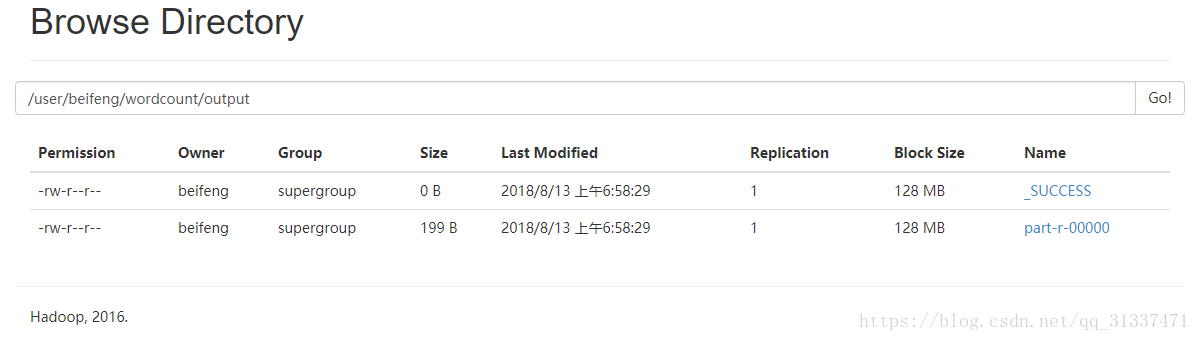
結果如下:

Map join
MapJoin 適用於有一份資料較小的連線情況。做法是直接把該小份資料直接全部載入到記憶體當中,按連結關鍵字建立索引。然後大份資料就作為 MapTask 的輸入,對 map()方法的每次輸入都去記憶體當中直接去匹配連線。然後把連線結果按 key 輸出,這種方法要使用 hadoop中的 DistributedCache 把小份資料分佈到各個計算節點,每個 maptask 執行任務的節點都需要載入該資料到記憶體,並且按連線關鍵字建立索引:
這裡假設Customer為小表,Orders為大表,這也符合實際生產環境。
關於這種分散式快取的用法,直接看下程式碼的演示:
主函式入口程式碼:
package com.ibeifeng.mapreduce.join;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import javax.jdo.annotations.Order;
public class MapJoin extends Configured implements Tool{
//定義快取檔案的讀取路徑
private static String cacheFile = "hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/wordcount/input1/customers.csv";
//定義map處理類模板
public static class map extends Mapper<LongWritable, Text, NullWritable, Text>{
private Text outputValue = new Text();
Map<Integer,Customer> map = null;
@Override
protected void setup(Context context)throws IOException, InterruptedException {
//讀取分散式快取檔案
FileSystem fs = FileSystem.get(URI.create(cacheFile),context.getConfiguration());
FSDataInputStream fdis = fs.open(new Path(cacheFile));
BufferedReader br = new BufferedReader(new InputStreamReader(fdis));
//建立一個map集合來儲存讀取檔案的資料
map = new HashMap<Integer,Customer>();
String line = null;
while((line = br.readLine())!=null) {
String[] split = line.split(",");
Customer customer = new Customer(Integer.parseInt(split[0]), split[1], split[2]);
map.put(customer.getCid(),customer);
}
//關閉IO流
br.close();
}
@Override
protected void map(LongWritable key, Text values, Context context)
throws IOException, InterruptedException {
//將Customer表和Orders表的資料進行組合
String str = values.toString();
String[] Orders = str.split(",");
int joinID = Integer.valueOf(Orders[0]);
Customer customerid = map.get(joinID);
StringBuffer sbf = new StringBuffer();
sbf.append(Orders[0]).append(",")
.append(customerid.getCname()).append(",")
.append(customerid.getCphone()).append(",")
.append(Orders[1]).append(",")
.append(Orders[2]).append(",")
.append(Orders[3]).append(",");
outputValue.set(sbf.toString());
context.write(NullWritable.get(),outputValue);
}
}
//無reduce程式
//配置Driver模組
public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//獲取配置配置檔案物件
Configuration configuration = new Configuration();
//建立給mapreduce處理的任務
Job job = Job.getInstance(configuration,this.getClass().getSimpleName());
//獲取將要讀取到記憶體的檔案的路徑,並載入進記憶體
job.addCacheFile(URI.create(cacheFile));
//建立輸入路徑
Path source_path = new Path(args[0]);
//建立輸出路徑
Path des_path = new Path(args[1]);
//建立操作hdfs的FileSystem物件
FileSystem fs = FileSystem.get(configuration);
if (fs.exists(des_path)) {
fs.delete(des_path,true);
}
FileInputFormat.addInputPath(job, source_path);
FileOutputFormat.setOutputPath(job, des_path);
//設定讓任務打包jar執行
job.setJarByClass(MapJoin.class);
//設定map
job.setMapperClass(map.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
//設定reduceTask的任務數為0,即沒有reduce階段和shuffle階段
job.setNumReduceTasks(0);
//提交job到yarn元件上
boolean isSuccess = job.waitForCompletion(true);
return isSuccess?0:1;
}
//書寫主函式
public static void main(String[] args) {
Configuration configuration = new Configuration();
//1.書寫輸入和輸出路徑
String[] args1 = new String[] {
"hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/wordcount/input",
"hdfs://hadoop-senior01.ibeifeng.com:8020/user/beifeng/wordcount/output"
};
//2.設定系統以什麼使用者執行job任務
System.setProperty("HADOOP_USER_NAME", "beifeng");
//3.執行job任務
int status = 0;
try {
status = ToolRunner.run(configuration, new MapJoin(), args1);
} catch (Exception e) {
e.printStackTrace();
}
// int status = new MyWordCountMapReduce().run(args1);
//4.退出系統
System.exit(status);
}
} 構造類程式碼:
package com.ibeifeng.mapreduce.join;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class Customer implements Writable{
private int cid;
private String cname;
private String cphone;
public int getCid() {
return cid;
}
public void setCid(int cid) {
this.cid = cid;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
public String getCphone() {
return cphone;
}
public void setCphone(String cphone) {
this.cphone = cphone;
}
public Customer(int cid, String cname, String cphone) {
super();
this.cid = cid;
this.cname = cname;
this.cphone = cphone;
}
public void write(DataOutput out) throws IOException {
out.writeInt(this.cid);
out.writeUTF(this.cname);
out.writeUTF(this.cphone);
}
public void readFields(DataInput in) throws IOException {
this.cid = in.readInt();
this.cname = in.readUTF();
this.cphone = in.readUTF();
}
@Override
public String toString() {
return "Customer [cid=" + cid + ", cname=" + cname + ", cphone=" + cphone + "]";
}
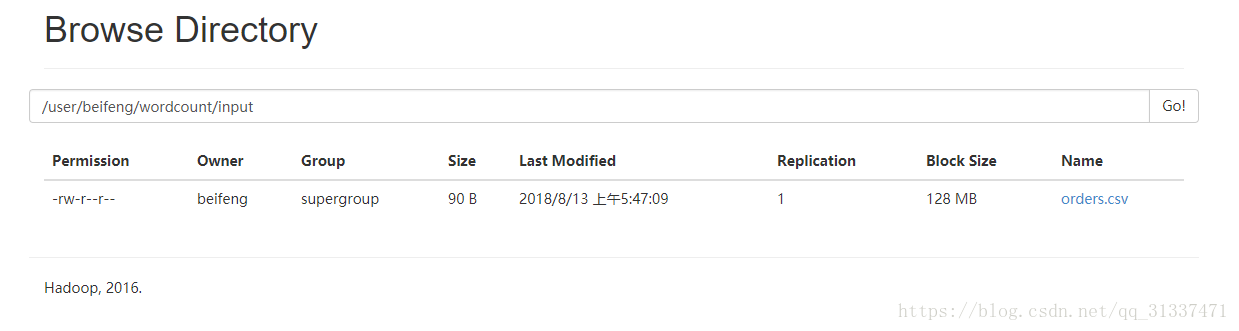
} 
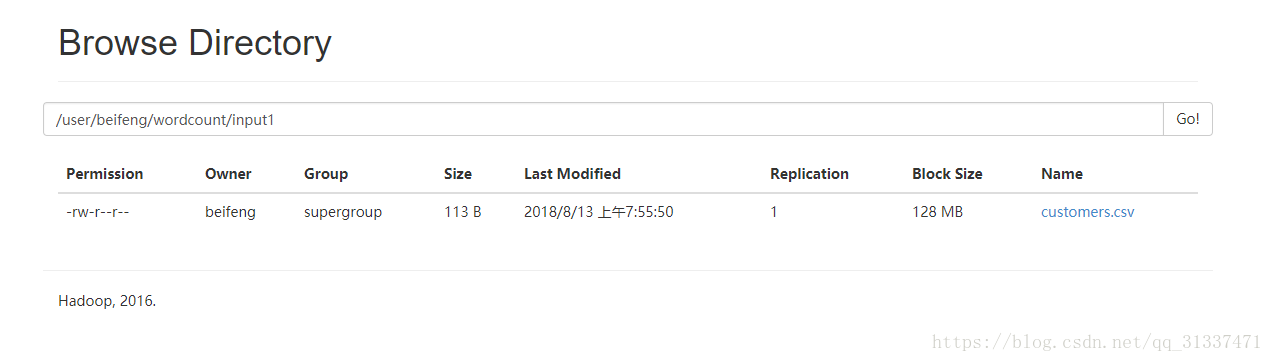
執行命令:bin/yarn jar datas/map_join.jar也是可以得到同樣的結果:
