
Python做文字挖掘的情感極性分析
資料探勘入門與實戰 公眾號: datadw
「情感極性分析」是對帶有感情色彩的主觀性文字進行分析、處理、歸納和推理的過程。按照處理文字的類別不同,可分為基於新聞評論的情感分析和基於產品評論的情感分析。其中,前者多用於輿情監控和資訊預測,後者可幫助使用者瞭解某一產品在大眾心目中的口碑。
目前常見的情感極性分析方法主要是兩種:基於情感詞典的方法和基於機器學習的方法。
1. 基於情感詞典的文字情感極性分析
筆者是通過情感打分的方式進行文字情感極性判斷,score > 0判斷為正向,score < 0判斷為負向。
1.1 資料準備 1.1.1 情感詞典及對應分數
詞典把所有常用詞都打上了唯一分數有許多不足之處。
-
之一,不帶情感色彩的停用詞會影響文字情感打分。在
-
之二,由於中文的博大精深,詞性的多變成為了影響模型準確度的重要原因。
一種情況是同一個詞在不同的語境下可以是代表完全相反的情感意義,用筆者模型預測偏差最大的句子為例(來源於朋友圈文字):
有車一族都用了這個寶貝,後果很嚴重哦[偷笑][偷笑][偷笑]1,交警工資估計會打5折,沒有超速罰款了[呲牙][呲牙][呲牙]2,移動聯通公司大幅度裁員,電話費少了[呲牙][呲牙][呲牙]3,中石化中石油裁員2成,路痴不再迷路,省油[悠閒][悠閒][悠閒]5,保險公司裁員2成,保費折上折2成,全國通用[憨笑][憨笑][憨笑]買不買你自己看著辦吧[調皮][調皮][調皮]
裡面嚴重等詞都是表達的相反意思,甚至整句話一起表示相反意思,不知死活的筆者還沒能深入研究如何用詞典的方法解決這類問題,但也許可以用機器學習的方法讓神經網路進行學習能夠初步解決這一問題。
另外,同一個詞可作多種詞性,那麼情感分數也不應相同,例如:
這部電影真垃圾
垃圾分類
很明顯在第一句中垃圾表現強烈的貶義,而在第二句中表示中性,單一評分對於這類問題的分類難免有失偏頗。
否定詞的出現將直接將句子情感轉向相反的方向,而且通常效用是疊加的。常見的否定詞:不、沒、無、非、莫、弗、勿、毋、未、否、別、無、休、難道等。
1.1.3 程度副詞詞典
既是通過打分的方式判斷文字的情感正負,那麼分數絕對值的大小則通常表示情感強弱。既涉及到程度強弱的問題,那麼程度副詞的引入就是勢在必行的。詞典可從《知網》情感分析用詞語集(beta版)
http://www.keenage.com/download/sentiment.rar
下載。詞典內資料格式可參考如下格式,即共兩列,第一列為程度副詞,第二列是程度數值,> 1表示強化情感,< 1表示弱化情感。

程度副詞詞典
1.1.4 停用詞詞典
中科院計算所中文自然語言處理開放平臺釋出了有1208個停用詞的中文停用詞表,
http://www.datatang.com/data/43894
http://www.hicode.cc/download/view-software-13784.html
1.2 資料預處理 1.2.1 分詞
即將句子拆分為詞語集合,結果如下:
e.g. 這樣/的/酒店/配/這樣/的/價格/還算/不錯
Python常用的分詞工具:
-
結巴分詞 Jieba
-
Pymmseg-cpp
-
Loso
-
smallseg
在此筆者使用Jieba進行分詞。
1.2.2 去除停用詞
遍歷所有語料中的所有詞語,刪除其中的停用詞
e.g. 這樣/的/酒店/配/這樣/的/價格/還算/不錯
--> 酒店/配/價格/還算/不錯
1.3 構建模型 1.3.1 將詞語分類並記錄其位置
將句子中各類詞分別儲存並標註位置。
"""2. 情感定位"""defclassifyWords(wordDict):# (1) 情感詞senList = readLines( 'BosonNLP_sentiment_score.txt') senDict = defaultdict() fors insenList: senDict[s.split( ' ')[ 0]] = s.split( ' ')[ 1] # (2) 否定詞notList = readLines( 'notDict.txt') # (3) 程度副詞degreeList = readLines( 'degreeDict.txt') degreeDict = defaultdict() ford indegreeList: degreeDict[d.split( ',')[ 0]] = d.split( ',')[ 1] senWord = defaultdict() notWord = defaultdict() degreeWord = defaultdict() forword inwordDict.keys():
ifword insenDict.keys() andword notinnotList andword notindegreeDict.keys(): senWord[wordDict[word]] = senDict[word]
elifword innotList andword notindegreeDict.keys(): notWord[wordDict[word]] = -1elifword indegreeDict.keys(): degreeWord[wordDict[word]] = degreeDict[word]
returnsenWord, notWord, degreeWord 1.3.2 計算句子得分
在此,簡化的情感分數計算邏輯:所有情感詞語組的分數之和
定義一個情感詞語組:兩情感詞之間的所有否定詞和程度副詞與這兩情感詞中的後一情感詞構成一個情感片語,即notWords + degreeWords + sentiWords,例如不是很交好,其中不是為否定詞,很為程度副詞,交好為情感詞,那麼這個情感詞語組的分數為:
finalSentiScore = (-1) ^ 1 * 1.25 * 0.747127733968
其中1指的是一個否定詞,1.25是程度副詞的數值,0.747127733968為交好的情感分數。
虛擬碼如下:
finalSentiScore = (-1) ^ (num of notWords) * degreeNum * sentiScore
finalScore = sum(finalSentiScore)
"""3. 情感聚合"""defscoreSent(senWord, notWord, degreeWord, segResult):W = 1score = 0# 存所有情感詞的位置的列表senLoc = senWord.keys() notLoc = notWord.keys() degreeLoc = degreeWord.keys() senloc = -1# notloc = -1# degreeloc = -1# 遍歷句中所有單詞segResult,i為單詞絕對位置fori inrange( 0, len(segResult)): # 如果該詞為情感詞ifi insenLoc: # loc為情感詞位置列表的序號senloc += 1# 直接新增該情感詞分數score += W * float(senWord[i])
# print "score = %f" % scoreifsenloc < len(senLoc) - 1:
# 判斷該情感詞與下一情感詞之間是否有否定詞或程度副詞# j為絕對位置forj inrange(senLoc[senloc], senLoc[senloc + 1]): # 如果有否定詞ifj innotLoc: W *= -1# 如果有程度副詞elifj indegreeLoc: W *= float(degreeWord[j])
# i定位至下一個情感詞ifsenloc < len(senLoc) - 1: i = senLoc[senloc + 1] returnscore 1.4 模型評價
將600多條朋友圈文字的得分排序後做出散點圖:
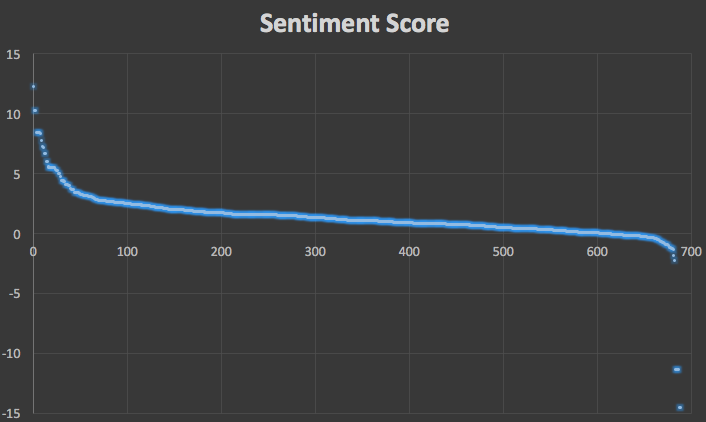
Score Distribution
其中大多數文字被判為正向文字符合實際情況,且絕大多數文字的情感得分的絕對值在10以內,這是因為筆者在計算一個文字的情感得分時,以句號作為一句話結束的標誌,在一句話內,情感詞語組的分數累加,如若一個文字中含有多句話時,則取其所有句子情感得分的平均值。
然而,這個模型的缺點與侷限性也非常明顯:
-
首先,段落的得分是其所有句子得分的平均值,這一方法並不符合實際情況。正如文章中先後段落有重要性大小之分,一個段落中前後句子也同樣有重要性的差異。
-
其次,有一類文字使用貶義詞來表示正向意義,這類情況常出現與宣傳文字中,還是那個例子:
有車一族都用了這個寶貝,後果很嚴重哦[偷笑][偷笑][偷笑]1,交警工資估計會打5折,沒有超速罰款了[呲牙][呲牙][呲牙]2,移動聯通公司大幅度裁員,電話費少了[呲牙][呲牙][呲牙]3,中石化中石油裁員2成,路痴不再迷路,省油[悠閒][悠閒][悠閒]5,保險公司裁員2成,保費折上折2成,全國通用[憨笑][憨笑][憨笑]買不買你自己看著辦吧[調皮][調皮][調皮]2980元軒轅魔鏡帶回家,推廣還有返利[得意]
Score Distribution中得分小於-10的幾個文字都是與這類情況相似,這也許需要深度學習的方法才能有效解決這類問題,普通機器學習方法也是很難的。
-
對於正負向文字的判斷,該演算法忽略了很多其他的否定詞、程度副詞和情感詞搭配的情況;用於判斷情感強弱也過於簡單。
2. 基於機器學習的文字情感極性分析 2.1 還是資料準備 2.1.1 停用詞總之,這一模型只能用做BENCHMARK...
(同1.1.4)
2.1.2 正負向語料庫
http://www.datatang.com/data/11936
其中正向7000條,負向3000條(筆者是不是可以認為這個世界還是充滿著滿滿的善意呢…),當然也可以參考情感分析資源使用其他語料作為訓練集。
2.1.3 驗證集
Amazon上對iPhone 6s的評論,來源已不可考……
2.2 資料預處理 2.2.1 還是要分詞
(同1.2.1)
importnumpy asnp importsys importre importcodecs importos importjiebafrom gensim.models importword2vecfrom sklearn.cross_validation importtrain_test_splitfrom sklearn.externals importjoblibfrom sklearn.preprocessing importscalefrom sklearn.svm importSVCfrom sklearn.decomposition importPCAfrom scipy importstatsfrom keras.models importSequentialfrom keras.layers importDense, Dropout, Activationfrom keras.optimizers importSGDfrom sklearn.metrics importf1_scorefrom bayes_opt importBayesianOptimization asBOfrom sklearn.metrics importroc_curve, auc importmatplotlib.pyplot aspltdef parseSent(sentence): seg_list = jieba.cut(sentence) output = ''.join(list(seg_list)) # use space to join them return output 2.2.2 也要去除停用詞
(同1.2.2)
2.2.3 訓練詞向量
(重點來了!)模型的輸入需是資料元組,那麼就需要將每條資料的詞語組合轉化為一個數值向量
常見的轉化演算法有但不僅限於如下幾種:
(請原諒不知死活的胖子直接用展示的ppt截圖作說明,沒錯,我就是懶,你打我呀)
-
Bag of Words

Bag of Words
-
TF-IDF

TF-IDF
-
Word2Vec

Word2Vec
在此筆者選用Word2Vec將語料轉化成向量
def getWordVecs(wordList): vecs = [] forwordinwordList:
word= word. replace( 'n', '') try: vecs.append(model[ word]) except KeyError: continue # vecs = np.concatenate(vecs)returnnp.array(vecs, dtype = 'float')def buildVecs(filename): posInput = [] withopen(filename, "rb") astxtfile:
# print txtfileforlinesintxtfile: lines= lines. split( 'n ')
forlineinlines: line= jieba.cut( line) resultList = getWordVecs( line)
# for each sentence, the mean vector of all its vectors is used to represent this sentenceiflen(resultList) != 0: resultArray = sum(np.array(resultList))/ len(resultList) posInput.append(resultArray) returnposInput # load word2vec modelmodel = word2vec.Word2Vec.load_word2vec_format( "corpus.model.bin", binary = True) # txtfile = [u'標準間太差房間還不如3星的而且設施非常陳舊.建議酒店把老的標準間從新改善.', u'在這個西部小城市能住上這樣的酒店讓我很欣喜,提供的免費接機服務方便了我的出行,地處市中心,購物很方便。早餐比較豐富,服務人員很熱情。推薦大家也來試試,我想下次來這裡我仍然會住這裡']posInput = buildVecs( 'pos.txt')negInput = buildVecs( 'pos.txt') # use 1 for positive sentiment, 0 for negativey = np.concatenate((np.ones( len(posInput)), np.zeros( len(negInput))))X = posInput[:] forneg innegInput: X.append(neg)X = np.array(X) 2.2.4 標準化
雖然筆者覺得在這一問題中,標準化對模型的準確率影響不大,當然也可以嘗試其他的標準化的方法。
# standardizationX= scale(X) 2.2.5 降維
根據PCA結果,發現前100維能夠cover 95%以上的variance。
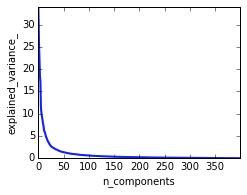
PCA
# PCA# Plot the PCA spectrumpca.fit(X)plt.figure( 1, figsize=( 4, 3))plt.clf()plt.axes([ .2, .2, .7, .7])plt.plot(pca.explained_variance_, linewidth= 2)plt.axis('tight')plt.xlabel('n_components')plt.ylabel('explained_variance_')X_reduced = PCA(n_components = 100).fit_transform(X) 2.3 構建模型 2.3.1 SVM (RBF) + PCA
SVM (RBF)分類表現更為寬鬆,且使用PCA降維後的模型表現有明顯提升,misclassified多為負向文字被分類為正向文字,其中AUC = 0.92,KSValue = 0.7。
"""2.1 SVM (RBF) using training data with 100 dimensions"""clf = SVC(C = 2, probability = True)clf.fit(X_reduced_train, y_reduced_train) print'Test Accuracy: %.2f'% clf.score(X_reduced_test, y_reduced_test)pred_probas = clf.predict_proba(X_reduced_test)[:, 1] print"KS value: %f"% KSmetric(y_reduced_test, pred_probas)[ 0] # plot ROC curve# AUC = 0.92# KS = 0.7fpr,tpr,_ = roc_curve(y_reduced_test, pred_probas)roc_auc = auc(fpr,tpr)plt.plot(fpr, tpr, label = 'area = %.2f'% roc_auc)plt.plot([ 0, 1], [ 0, 1], 'k--')plt.xlim([ 0.0, 1.0])plt.ylim([ 0.0, 1.05])plt.legend(loc = 'lower right')plt.show()joblib.dump(clf, "SVC.pkl") 2.3.2 MLP
MLP相比於SVM (RBF),分類更為嚴格,PCA降維後對模型準確率影響不大,misclassified多為正向文字被分類為負向,其實是更容易overfitting,原因是語料過少,其實用神經網路未免有些小題大做,AUC = 0.91。
"""2.2MLP using original training data with 400dimensions """model = Sequential()model. add(Dense( 512, input_dim = 400, init = 'uniform', activation = 'tanh'))model. add(Dropout( 0.5))model. add(Dense( 256, activation = 'relu'))model. add(Dropout( 0.5))model. add(Dense( 128, activation = 'relu'))model. add(Dropout( 0.5))model. add(Dense( 64, activation = 'relu'))model. add(Dropout( 0.5))model. add(Dense( 32, activation = 'relu'))model. add(Dropout( 0.5))model. add(Dense( 1, activation = 'sigmoid'))model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = [ 'accuracy'])model.fit(X_train, y_train, nb_epoch = 20, batch_size = 16)score = model.evaluate(X_test, y_test, batch_size = 16) print( 'Test accuracy: ',
score[ 1])pred_probas = model.predict(X_test)# print"KS value: %f"% KSmetric(y_reduced_test, pred_probas)[ 0]# plot ROC curve# AUC = 0.91fpr,tpr,_ = roc_curve(y_test, pred_probas)roc_auc = auc(fpr,tpr)plt.plot(fpr, tpr, label = 'area = %.2f'% roc_auc)plt.plot([ 0, 1], [ 0, 1], 'k--')plt.xlim([ 0.0, 1.0])plt.ylim([ 0.0, 1.05])plt.legend( loc= 'lower right')plt.show() 2.4 模型評價
-
實際上,第一種方法中的第二點缺點依然存在,但相比於基於詞典的情感分析方法,基於機器學習的方法更為客觀
-
另外由於訓練集和測試集分別來自不同領域,所以有理由認為訓練集不夠充分,未來可以考慮擴充訓練集以提升準確率。
via http://www.jianshu.com/p/4cfcf1610a