
電影評論的情感極性分析
這一節我們將使用Keras構建一個用於分析情感極性的神經網路模型,我們使用的是IMDB資料集,其中包含了50000條嚴重兩極分化的評論。我們將從資料的準備開始,一步一步地討論深度學習的實踐方法論。
資料準備
Keras內建了下載IMDB資料的介面,但由於網路許可權的原因,我們採用瀏覽器事先從網路上下載IMDB資料,把它放到我們的工程的corpus目錄下,並在呼叫介面時指定載入資料的路徑(注意一定要使用絕對路徑)。該介面直接以元組的形式返回了(訓練資料, 對應標籤)以及(測試資料, 對應標籤)。
from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(path="/ABS_PATH/imdb.npz", num_words=10000)
引數num_words=10000表示僅保留訓練資料中前10000個常出現的單詞,較低頻的詞將被捨棄掉。
print(train_data[0], train_labels[0])[1, 14, 22, 16, ..., 5345, 19, 178, 32] 1
我們分別輸出一條訓練資料與對應的標籤,可以看出每條評論被表示為單詞的索引編號的序列,而標籤對應於0/1的整數表示負面(negative)與正面(positive)。顯然,用單詞索引編號序列表示的每條評論資料是不等長的,並不能用作神經網路的輸入,我們需要將其轉換為張量。一種最簡單的張量轉換方法就是one-hot編碼,這種方法把每一條評論對應為一個詞彙表大小的向量,出現過單詞多對應的位置被置為1,其他位置為0。
import numpy as np def vectorize_sequences(sequences, dimension=10000): #維數就是詞彙表的大小 results = np.zeros((len(sequences), dimension)) #建立樣本數*詞彙表大小的零矩陣 for i,sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) #對訓練資料進行one-hot編碼 x_test = vectorize_sequences(test_data) #對測試資料進行one-hot編碼 print(x_train[0])
[0. 1. 1. ... 0. 0. 0.]
當然,對應的標籤也應該向量化作為神經網路的目標值,只需要將它們轉換為Numpy陣列就行:
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')至此,我們完成了資料的準備工作,受益於使用了Keras的內建函式,我們省去了自行對資料進行訓練集與測試集的劃分。對於輸入神經網路的資料,我們需要將它們都向量化。
構建網路
我們設計這樣一個網路,它包含兩個中間層,每一層都有16個隱藏單元;第三層輸出一個標量,預測當前評論的情感,這個值在0~1的範圍內,越接近0表示負向極性,越接近1表示正向極性。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))一個隱藏單元是對應的層所擁有的表示空間的一個維度,我們設計的中間層相當於做了這樣一個運算:
output = relu(dot(W, input) + b)
其中W是一個形狀為(input_dimension, 16)的權重矩陣,與W做點積相當於將輸入資料投影到一個16維的表示空間中,再加上一個偏置變數b,為了讓變換後的表示空間具有更多樣性,把點積與相加後的線性變化結果輸入relu啟用函式進行一定的非線性變換。
然後,我們選擇二元交叉熵損失函式與RMSprop優化器來配置模型,並且監控精度。
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])驗證方法
為了在訓練過程中監控模型在前所未見的資料上的精度,我們需要從訓練資料中撥出一部分樣本作為驗證集,我們簡單地選擇前10000條。
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]現在可以開始訓練了,我們讓512個樣本組成一個小批量,將模型訓練20個輪次。
history = model.fit(partial_x_train, partial_y_train,
epochs=20, batch_size=512, validation_data=(x_val, y_val))
Train on 15000 samples, validate on 10000 samples
Epoch 1/20
15000/15000 [==============================] - 7s 482us/step - loss: 0.4977 - acc: 0.7947 - val_loss: 0.3720 - val_acc: 0.8717
... ... ...
Epoch 20/20
15000/15000 [==============================] - 3s 225us/step - loss: 0.0068 - acc: 0.9990 - val_loss: 0.7058 - val_acc: 0.8653
20次的迭代很快就完成了,fit()函式執行後返回一個History物件,該物件有一個history成員,它是一個字典,包含了訓練過程中的相關資料。
print(history.history.keys())dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
我們使用Matplotlib在同一張圖上繪製訓練損失與驗證過程中監控的指標,從圖上直觀地觀察模型的表現。首先,繪製訓練損失與驗證損失:
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()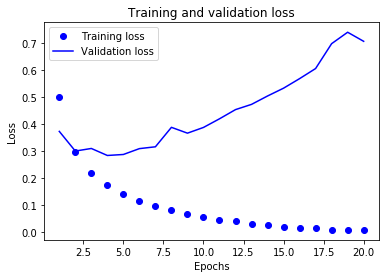
接著,我們再來繪製訓練精度與驗證精度:
plt.clf()
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()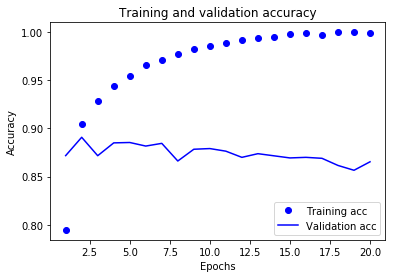
圖中反應訓練資料的折線走勢與我們的預期是一致的,訓練損失每輪都在降低,訓練精度每輪都在提升;但是,驗證資料的折線並不是這樣,驗證損失和驗證精度似乎在第四輪達到了最佳值。也就是說,我們的訓練過程從第五輪後就出現了過擬合:模型在訓練資料上的表現越來越好,但在前所未見的資料上並沒有這樣的表現。為了避免過擬合,我們把模型訓練的輪數設定為4,從頭重新訓練這個網路,並在測試集上進行評估。
完整程式碼
import numpy as np
from keras import models
from keras import layers
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(path="/ABS_PATH/imdb.npz", num_words=10000)
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i,sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(partial_x_train, partial_y_train, epochs=4, batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, y_test)
print(results)
Train on 15000 samples, validate on 10000 samples
Epoch 1/4
15000/15000 [==============================] - 7s 481us/step - loss: 0.5084 - acc: 0.7813 - val_loss: 0.3798 - val_acc: 0.8681
... ... ...
Epoch 4/4
15000/15000 [==============================] - 6s 396us/step - loss: 0.1751 - acc: 0.9438 - val_loss: 0.2840 - val_acc: 0.8831
25000/25000 [==============================] - 6s 260us/step
[0.3068919235897064, 0.87496]
很激動吧,我們僅僅用了不到三十行程式碼就到達了87%的精度,如果我們換用更復雜的模型,會有更好的結果。
總結
我們把這個例項的實踐步驟總結一下,可以作為我們進行深度學習建模的方法論,按部就班地開展相關的實驗與工程:
- 資料處理:劃分訓練集與測試集,把資料轉換為適合輸入神經網路的張量形式
- 構建網路:按照業務的具體需求,選擇合適的網路結構、損失函式與優化器,構建一個完整的網路模型
- 驗證方法:從訓練集中撥出一部分資料作為驗證集,將訓練集與驗證集同時放入fit()函式,指定相關的觀測值,用訓練記錄繪製相關指標在訓練集與驗證集上的表現圖
- 調整模型:根據表現圖調整模型的超引數(如:迭代輪數、網路複雜度)或設計一定的正則化策略
- 固化系統:把效能最好的網路結構、引數用來訓練最終的模型,固化為系統,並用測試集進行評測