
並行程式設計OpenMP基礎及簡單示例
OpenMP基本概念
OpenMP是一種用於共享記憶體並行系統的多執行緒程式設計方案,支援的程式語言包括C、C++和Fortran。OpenMP提供了對並行演算法的高層抽象描述,特別適合在多核CPU機器上的並行程式設計。編譯器根據程式中新增的pragma指令,自動將程式並行處理,使用OpenMP降低了並行程式設計的難度和複雜度。當編譯器不支援OpenMP時,程式會退化成普通(序列)程式。程式中已有的OpenMP指令不會影響程式的正常編譯執行。
在VS中啟用OpenMP很簡單,很多主流的編譯環境都內建了OpenMP。在專案上右鍵->屬性->配置屬性->C/C++->語言->OpenMP支援,選擇“是”即可。
OpenMP執行模式
OpenMP採用fork-join的執行模式。開始的時候只存在一個主執行緒,當需要進行平行計算的時候,派生出若干個分支執行緒來執行並行任務。當並行程式碼執行完成之後,分支執行緒會合,並把控制流程交給單獨的主執行緒。
一個典型的fork-join執行模型的示意圖如下:
OpenMP程式設計模型以執行緒為基礎,通過編譯製導指令制導並行化,有三種程式設計要素可以實現並行化控制,他們分別是編譯製導、API函式集和環境變數。
編譯製導
編譯製導指令以#pragma omp 開始,後邊跟具體的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。常用的功能指令如下:
- parallel:用在一個結構塊之前,表示這段程式碼將被多個執行緒並行執行;
for:用於for迴圈語句之前,表示將迴圈計算任務分配到多個執行緒中並行執行,以實現任務分擔,必須由程式設計人員自己保證每次迴圈之間無資料相關性;
parallel for:parallel和for指令的結合,也是用在for迴圈語句之前,表示for迴圈體的程式碼將被多個執行緒並行執行,它同時具有並行域的產生和任務分擔兩個功能;
sections:用在可被並行執行的程式碼段之前,用於實現多個結構塊語句的任務分擔,可並行執行的程式碼段各自用section指令標出(注意區分sections和section);
parallel sections:parallel和sections兩個語句的結合,類似於parallel for;
single:用在並行域內,表示一段只被單個執行緒執行的程式碼;
critical:用在一段程式碼臨界區之前,保證每次只有一個OpenMP執行緒進入;
flush:保證各個OpenMP執行緒的資料影像的一致性;
barrier:用於並行域內程式碼的執行緒同步,執行緒執行到barrier時要停下等待,直到所有執行緒都執行到barrier時才繼續往下執行;
atomic:用於指定一個數據操作需要原子性地完成;
master:用於指定一段程式碼由主執行緒執行;
threadprivate:用於指定一個或多個變數是執行緒專用,後面會解釋執行緒專有和私有的區別。
private:指定一個或多個變數在每個執行緒中都有它自己的私有副本;
firstprivate:指定一個或多個變數在每個執行緒都有它自己的私有副本,並且私有變數要在進入並行域或任務分擔域時,繼承主執行緒中的同名變數的值作為初值;
lastprivate:是用來指定將執行緒中的一個或多個私有變數的值在並行處理結束後複製到主執行緒中的同名變數中,負責拷貝的執行緒是for或sections任務分擔中的最後一個執行緒;
reduction:用來指定一個或多個變數是私有的,並且在並行處理結束後這些變數要執行指定的歸約運算,並將結果返回給主執行緒同名變數;
nowait:指出併發執行緒可以忽略其他制導指令暗含的路障同步;
num_threads:指定並行域內的執行緒的數目;
schedule:指定for任務分擔中的任務分配排程型別;
shared:指定一個或多個變數為多個執行緒間的共享變數;
ordered:用來指定for任務分擔域內指定程式碼段需要按照序列迴圈次序執行;
copyprivate:配合single指令,將指定執行緒的專有變數廣播到並行域內其他執行緒的同名變數中;
copyin:用來指定一個threadprivate型別的變數需要用主執行緒同名變數進行初始化;
default:用來指定並行域內的變數的使用方式,預設是shared。
API函式
除上述編譯製導指令之外,OpenMP還提供了一組API函式用於控制併發執行緒的某些行為,下面是一些常用的OpenMP API函式以及說明:
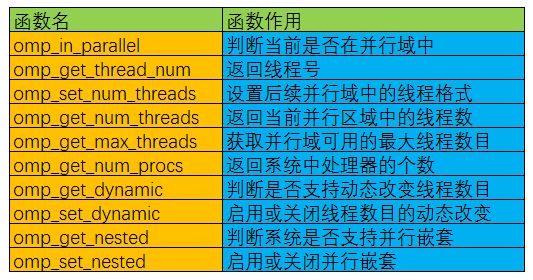
環境變數
OpenMP中定義一些環境變數,可以通過這些環境變數控制OpenMP程式的行為,常用的環境變數:
- OMP_SCHEDULE:用於for迴圈並行化後的排程,它的值就是迴圈排程的型別;
OMP_NUM_THREADS:用於設定並行域中的執行緒數;
OMP_DYNAMIC:通過設定變數值,來確定是否允許動態設定並行域內的執行緒數;
OMP_NESTED:指出是否可以並行巢狀。
簡單示例之parallel使用
parallel制導指令用來建立並行域,後邊要跟一個大括號將要並行執行的程式碼放在一起:
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel
{
cout << "Test" << endl;
}
system("pause");
}執行以上程式有如下輸出:
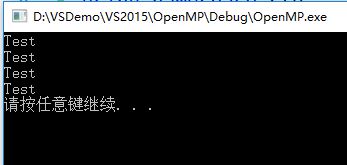
程式打印出了4個“Test”,說明parallel後的語句被4個執行緒分別執行了一次,4個是程式預設的執行緒數,還可以通過子句num_threads顯式控制建立的執行緒數:
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel num_threads(6)
{
cout << "Test" << endl;
}
system("pause");
}編譯執行有如下輸出:
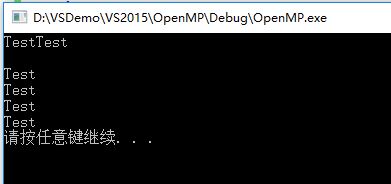
程式中顯式定義了6個執行緒,所以parallel後的語句塊分別被執行了6次。第二行的空行是由於每個執行緒都是獨立執行的,在其中一個執行緒輸出字元“Test”之後還沒有來得及換行時,另一個執行緒直接輸出了字元“Test”。
簡單示例之parallel for使用
使用parallel制導指令只是產生了並行域,讓多個執行緒分別執行相同的任務,並沒有實際的使用價值。parallel for用於生成一個並行域,並將計算任務在多個執行緒之間分配,從而加快計算執行的速度。可以讓系統預設分配執行緒個數,也可以使用num_threads子句指定執行緒個數。
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel for num_threads(6)
for (int i = 0; i < 12; i++)
{
printf("OpenMP Test, 執行緒編號為: %d\n", omp_get_thread_num());
}
system("pause");
}執行輸出:
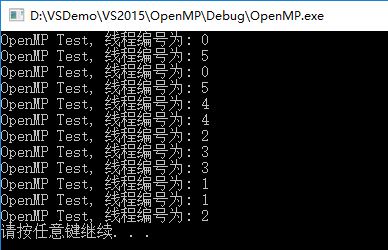
上邊程式指定了6個執行緒,迭代量為12,從輸出可以看到每個執行緒都分到了12/6=2次的迭代量。
OpenMP效率提升以及不同執行緒數效率對比
#include<iostream>
#include"omp.h"
using namespace std;
void test()
{
for (int i = 0; i < 80000; i++)
{
}
}
void main()
{
float startTime = omp_get_wtime();
//指定2個執行緒
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 80000; i++)
{
test();
}
float endTime = omp_get_wtime();
printf("指定 2 個執行緒,執行時間: %f\n", endTime - startTime);
startTime = endTime;
//指定4個執行緒
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 4 個執行緒,執行時間: %f\n", endTime - startTime);
startTime = endTime;
//指定8個執行緒
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 8 個執行緒,執行時間: %f\n", endTime - startTime);
startTime = endTime;
//指定12個執行緒
#pragma omp parallel for num_threads(12)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 12 個執行緒,執行時間: %f\n", endTime - startTime);
startTime = endTime;
//不使用OpenMP
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("不使用OpenMP多執行緒,執行時間: %f\n", endTime - startTime);
startTime = endTime;
system("pause");
}以上程式分別指定了2、4、8、12個執行緒和不使用OpenMP優化來執行一段垃圾程式,輸出如下:
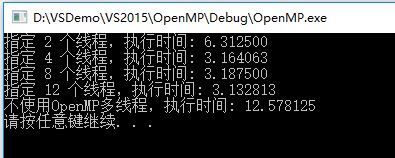
可見,使用OpenMP優化後的程式執行時間是原來的1/4左右,並且並不是執行緒數使用越多效率越高,一般執行緒數達到4~8個的時候,不能簡單通過提高執行緒數來進一步提高效率。