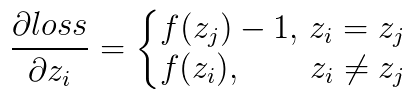深度學習筆記2:池化 全連線 啟用函式 softmax
1. 池化
池化層的輸入一般來源於上一個卷積層,主要作用是提供了很強的魯棒性(例如max-pooling是取一小塊區域中的最大值,此時若此區域中的其他值略有變化,或者影象稍有平移,pooling後的結果仍不變),並且減少了引數的數量,防止過擬合現象的發生。池化層一般沒有引數,所以反向傳播的時候,只需對輸入引數求導,不需要進行權值更新
池化層的前向計算
前向計算過程中,我們對卷積層輸出map的每個不重疊(有時也可以使用重疊的區域進行池化)的n*n區域(我這裡為2*2,其他大小的pooling過程類似)進行降取樣,選取每個區域中的最大值(max-pooling)或是平均值(mean-pooling),也有最小值的降取樣,計算過程和最大值的計算類似。
上圖中,池化層1的輸入為卷積層1的輸出,大小為24*24,對每個不重疊的2*2的區域進行降取樣。對於max-pooling,選出每個區域中的最大值作為輸出。而對於mean-pooling,需計算每個區域的平均值作為輸出。最終,該層輸出一個(24/2)*(24/2)的map。池化層2的計算過程也類似。
下面用圖示來看一下2種不同的pooling過程。
max-pooling:

mean-pooling:

池化層的反向計算
在池化層進行反向傳播時,max-pooling和mean-pooling的方式也採用不同的方式。
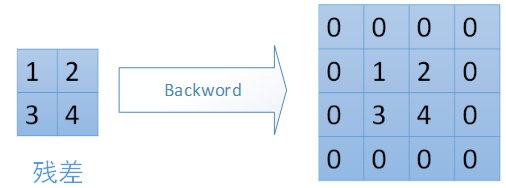
對於max-pooling,在前向計算時,是選取的每個2*2區域中的最大值,這裡需要記錄下最大值在每個小區域中的位置。在反向傳播時,只有那個最大值對下一層有貢獻,所以將殘差傳遞到該最大值的位置,區域內其他2*2-1=3個位置置零。具體過程如下圖,其中4*4矩陣中非零的位置即為前邊計算出來的每個小區域的最大值的位置。
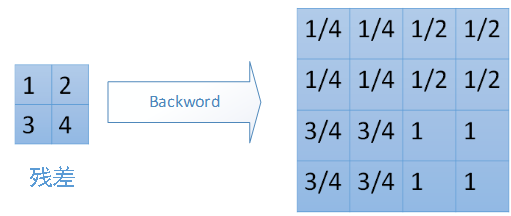
對於mean-pooling,我們需要把殘差平均分成2*2=4份,傳遞到前邊小區域的4個單元即可。具體過程如圖:
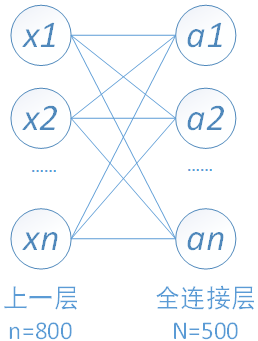
2. 全連線
全連線層的每一個結點都與上一層的所有結點相連,用來把前邊提取到的特徵綜合起來。由於其全相連的特性,一般全連線層的引數也是最多的。
全連線層的前向計算
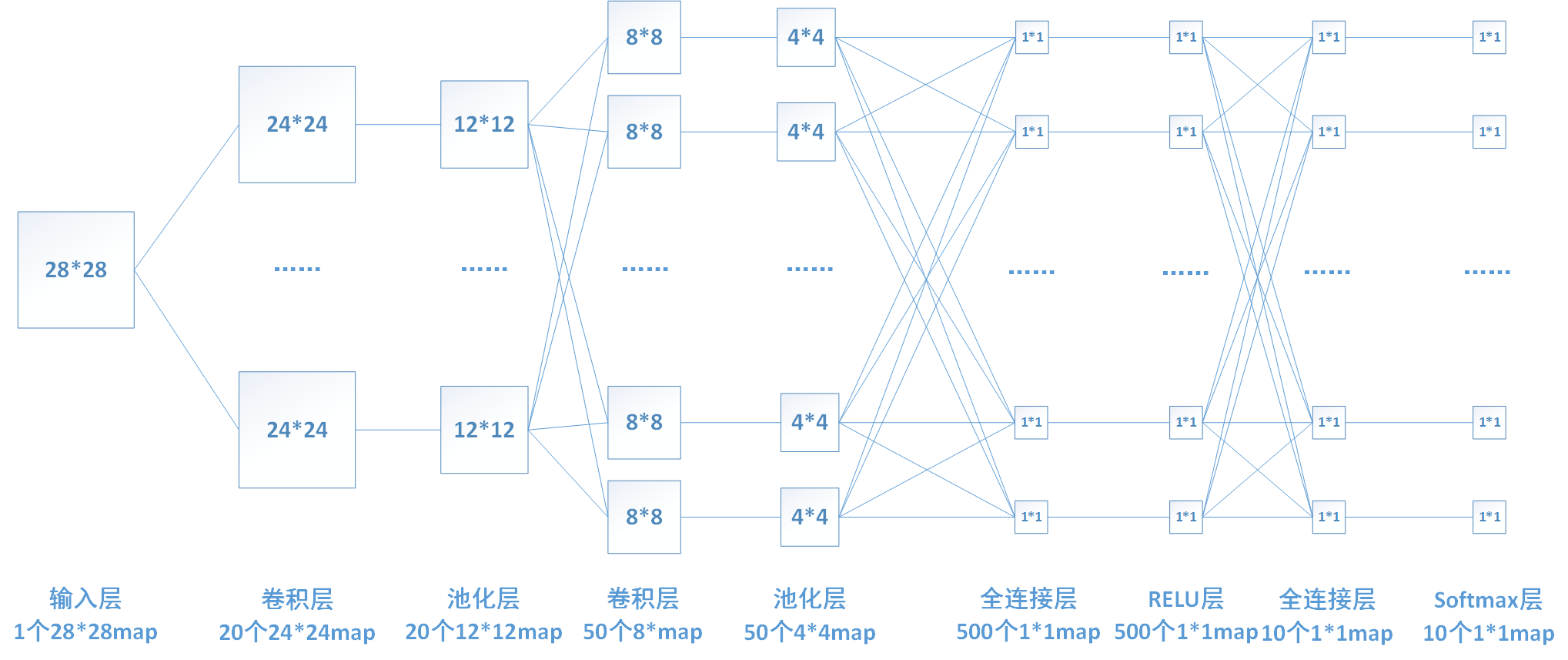
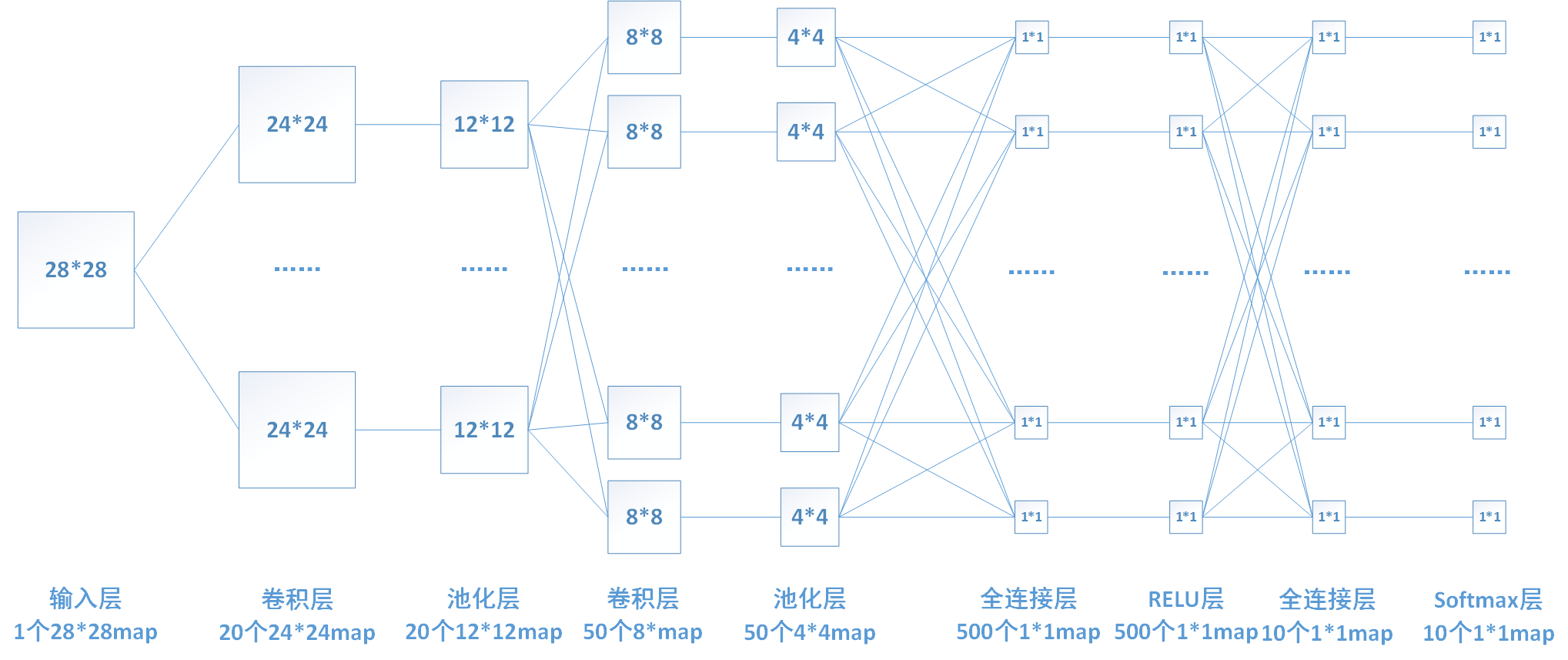
下圖中連線最密集的2個地方就是全連線層,這很明顯的可以看出全連線層的引數的確很多。在前向計算過程,也就是一個線性的加權求和的過程,全連線層的每一個輸出都可以看成前一層的每一個結點乘以一個權重係數W,最後加上一個偏置值b得到,即 。如下圖中第一個全連線層,輸入有50*4*4個神經元結點,輸出有500個結點,則一共需要50*4*4*500=400000個權值引數W和500個偏置引數b。
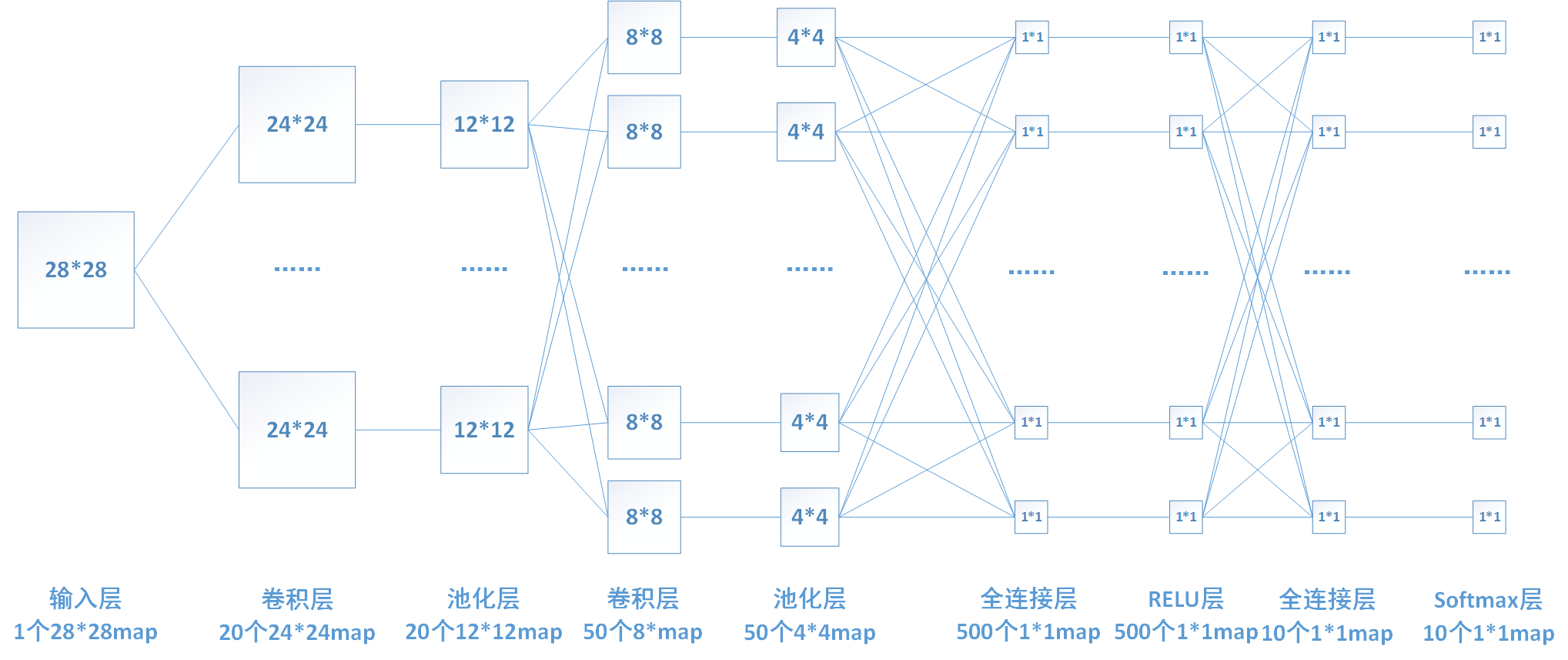
下面用一個簡單的網路具體介紹一下推導過程
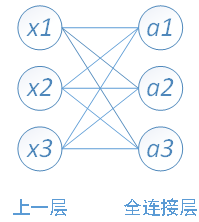
其中,x1、x2、x3為全連線層的輸入,a1、a2、a3為輸出,根據我前邊在筆記1中的推導,有
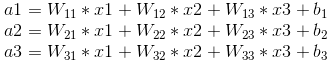
可以寫成如下矩陣形式:
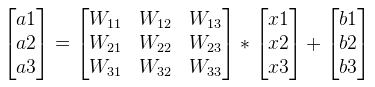
全連線層的反向傳播
以我們的第一個全連線層為例,該層有50*4*4=800個輸入結點和500個輸出結點。
由於需要對W和b進行更新,還要向前傳遞梯度,所以我們需要計算如下三個偏導數。
1、對上一層的輸出(即當前層的輸入)求導
若我們已知轉遞到該層的梯度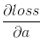 ,則我們可以通過鏈式法則求得loss對x的偏導數。
,則我們可以通過鏈式法則求得loss對x的偏導數。首先需要求得該層的輸出ai對輸入xj的偏導數

再通過鏈式法則求得loss對x的偏導數:
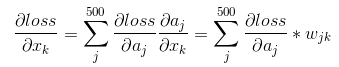
上邊求導的結果也印證了我前邊那句話:在反向傳播過程中,若第x層的a節點通過權值W對x+1層的b節點有貢獻,則在反向傳播過程中,梯度通過權值W從b節點傳播回a節點。
若我們的一次訓練16張圖片,即batch_size=16,則我們可以把計算轉化為如下矩陣形式。

2、對權重係數W求導
我們前向計算的公式如下圖,
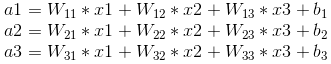
由圖可知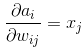
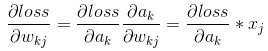
當batch_size=16時,寫成矩陣形式:

3、對偏置係數b求導
由上面前向推導公式可知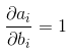 ,
,
即loss對偏置係數的偏導數等於對上一層輸出的偏導數。
當batch_size=16時,將不同batch對應的相同b的偏導相加即可,寫成矩陣形式即為乘以一個全1的矩陣:

啟用函式是用來引入非線性因素的。網路中僅有線性模型的話,表達能力不夠。比如一個多層的線性網路,其表達能力和單層的線性網路是相同的(可以化簡一個3層的線性網路試試)。我們前邊提到的卷積層、池化層和全連線層都是線性的,所以,我們要在網路中加入非線性的啟用函式層。一般一個網路中只設置一個啟用層。
啟用函式一般具有以下性質:
非線性: 線性模型的不足我們前邊已經提到。
處處可導:反向傳播時需要計算啟用函式的偏導數,所以要求啟用函式除個別點外,處處可導。
單調性:當啟用函式是單調的時候,單層網路能夠保證是凸函式。
輸出值的範圍: 當啟用函式輸出值是有限的時候,基於梯度的優化方法會更加穩定,因為特徵的表示受有限權值的影響更顯著;當啟用函式的輸出是無限的時候,模型的訓練會更加高效,不過在這種情況小,一般需要更小的learning rate.
3. 啟用函式常見啟用函式介紹:
實際中可選用的啟用函式有很多,如下圖:
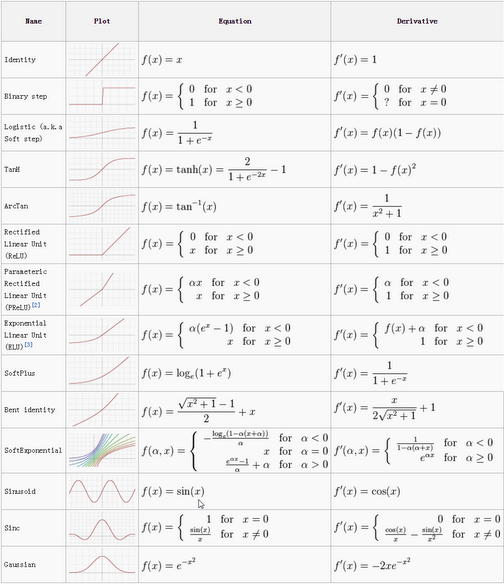
但不同的啟用函式效果有好有壞,現在一般比較常見的啟用函式有sigmoid、tanh和Relu,其中Relu由於效果最好,現在使用的比較廣泛。3種啟用函式具體介紹如下:
Sigmoid函式
Sigmoid函式表示式為: ,它將輸入值對映到[0,1]區間內,其函式影象如下圖(谷歌和百度搜索框輸入表示式就能給出影象,挺好用的)。
,它將輸入值對映到[0,1]區間內,其函式影象如下圖(谷歌和百度搜索框輸入表示式就能給出影象,挺好用的)。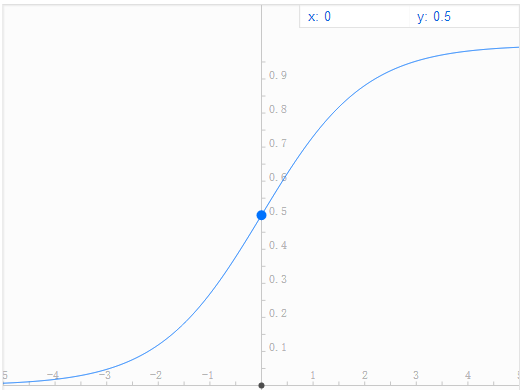
Sigmoid有一個十分致命的缺點就是它的導數值很小(sigmoid函式導數影象如下圖),其導數最大值也只有1/4,而且特別是在輸入很大或者很小的時候,其導數趨近於0。這直接導致的結果就是在反向傳播中,梯度會衰減的十分迅速(後面公式的推導過程會證明這一點),導致傳遞到前邊層的梯度很小甚至消失,訓練會變得十分困難。
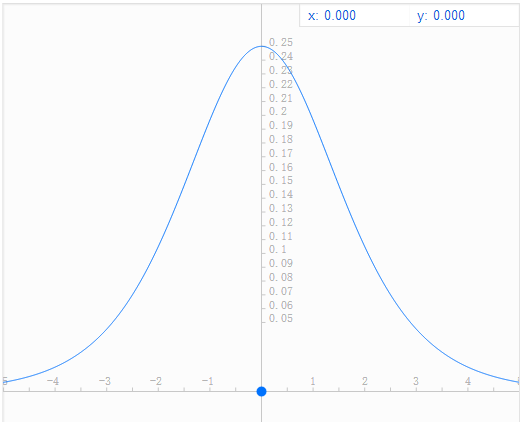
還有就是sigmoid函式的計算相對來說較為複雜(相對後面的relu函式),耗時較長,所以由於這些缺點,現在已經很少有人使用sigmoid函式。
Tanh函式
Tanh函式表示式為: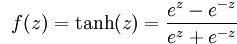 ,其影象為(函式複雜點百度就畫不了了
,其影象為(函式複雜點百度就畫不了了 ):
):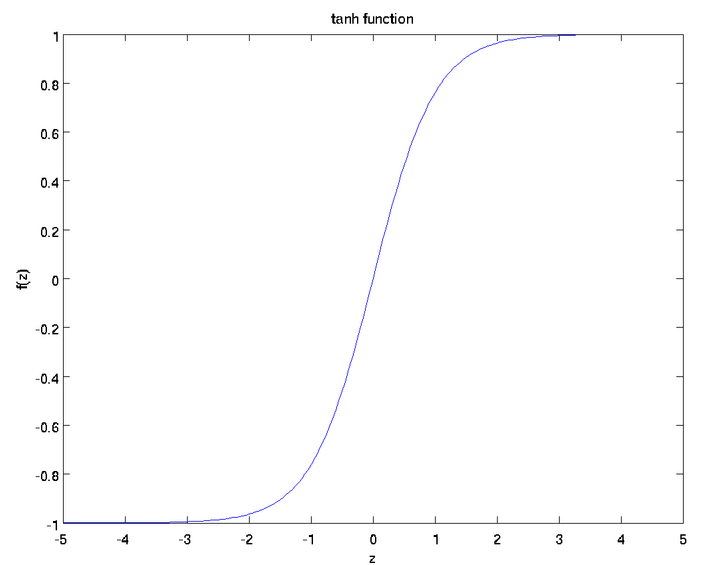
Tanh函式現在也很少使用。
Relu函式
Relu函式為現在使用比較廣泛的啟用函式,其表示式為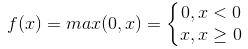 。當輸入x<0時,輸出為0;當x>0時,輸出等於輸入值。
。當輸入x<0時,輸出為0;當x>0時,輸出等於輸入值。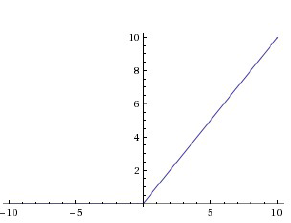
Relu函式相對於前邊2種啟用函式,有以下優點:
1、relu函式的計算十分簡單,前向計算時只需輸入值和一個閾值(這裡為0)比較,即可得到輸出值。在反向傳播時,relu函式的導數為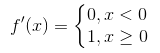 。計算也比前邊2個函式的導數簡單很多。
。計算也比前邊2個函式的導數簡單很多。
2、由於relu函式的導數為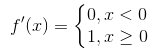
Relu函式也有很明顯的缺點,就是在訓練的時候,網路很脆弱,很容易出現很多神經元值為0,從而再也訓練不動。一般我們將學習率設定為較小值來避免這種情況的發生。
為了解決上面的問題,後來又提出很多修正過的模型,比如Leaky-ReLU、Parametric ReLU和Randomized ReLU等,其思想一般都是將x<0的區間不置0值,而是設定為1個引數與輸入值相乘的形式,如αx,並在訓練過程對α進行修正。
啟用函式層的推導
啟用函式層的前向計算
這裡我以relu層為例介紹一下啟用函式層的推導,由於relu層沒有引數,所以不需要進行權值的更新,只需進行梯度的傳遞。下圖還是我們熟悉的那個網路,其中倒數第三層為啟用函式relu層。
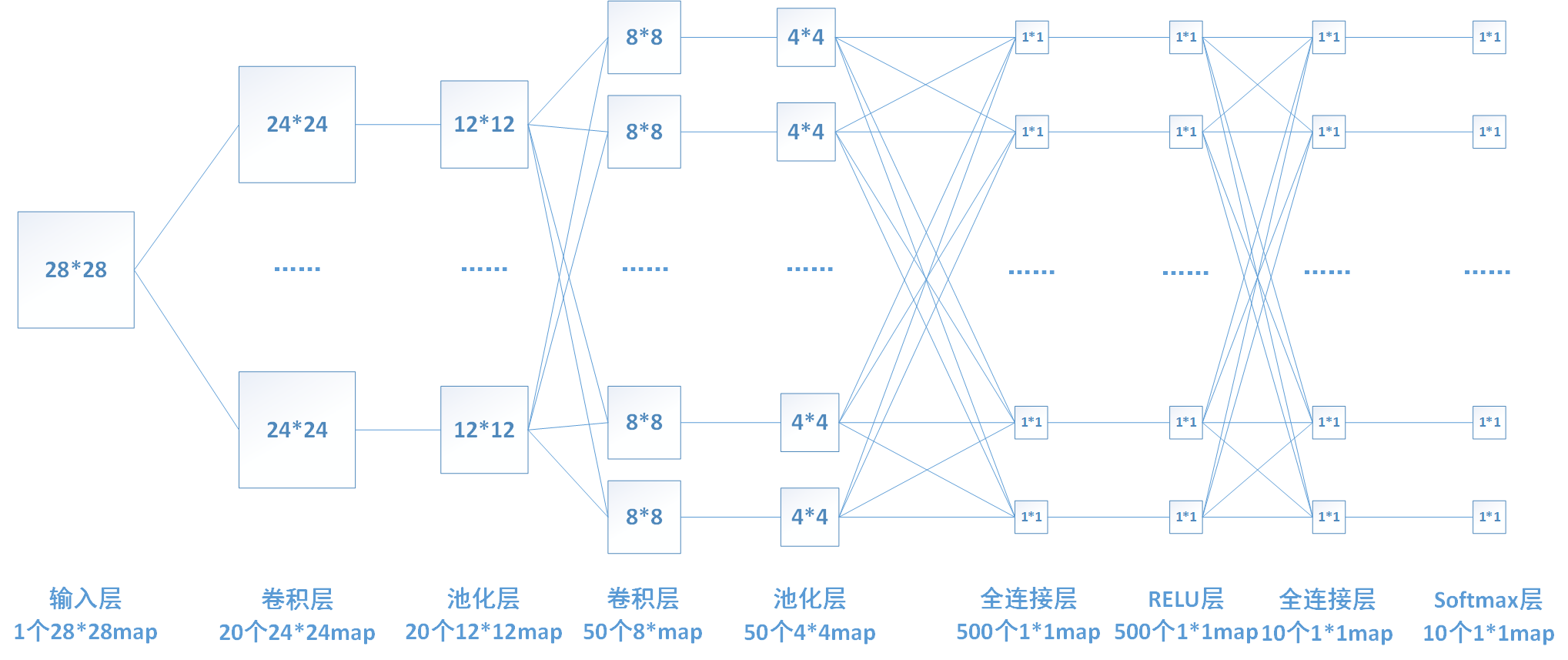
relu函式的表示式為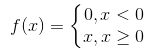
啟用函式層的反向傳播
Relu函式的導數為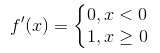 。假設該層前向計算過程為
。假設該層前向計算過程為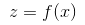 ,其中f(x)為relu函式。反向傳播時已知
,其中f(x)為relu函式。反向傳播時已知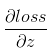 ,根據鏈式求導法則
,根據鏈式求導法則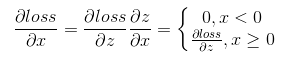 。
。所以反向傳播時,只需將前向計算時輸入大於0的結點對應的梯度向前傳,小於0的結點的梯度置零即可。 4. softmax
softmax簡介
Softmax迴歸模型是logistic迴歸模型在多分類問題上的推廣,在多分類問題中,待分類的類別數量大於2,且類別之間互斥。比如我們的網路要完成的功能是識別0-9這10個手寫數字,若最後一層的輸出為[0,1,0, 0, 0, 0, 0, 0, 0, 0],則表明我們網路的識別結果為數字1。
Softmax的公式為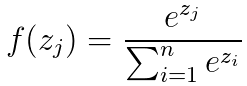
softmax層的推導
softmax層的前向計算
在我們的網路中,最後一層是softmax層。
softmax公式為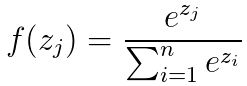
Softmax還有另一種計算方法。假設zk為輸入中的最大值,則softmax也可以寫成這種形式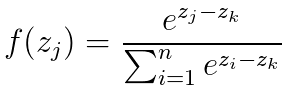
softmax層的反向傳播
設softmax的輸出為a,輸入為z,損失函式為loss。則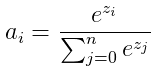 ,
, 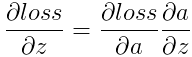 。其中
。其中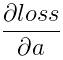 在caffe中是top_diff,a為caffe中的top_data,均為已知量。需要計算的是
在caffe中是top_diff,a為caffe中的top_data,均為已知量。需要計算的是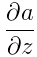 。
。直接求導可得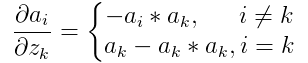
所以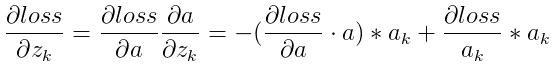
softmax層的損失函式
通常情況下softmax會被用在網路中的最後一層,用來進行最後的分類和歸一化。所以其實上邊softmax層的反向傳播一般不會用到。
Softmax的損失函式使用的是對數損失函式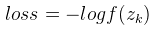 ,其中k為該樣本的label(即該樣本對應的正確輸出,比如我們要識別的圖片是數字7,則k=7,選擇softmax的第7個輸出值來計算loss)。一般我們進行訓練時一批圖片有多張,比如batch size = 16,則
,其中k為該樣本的label(即該樣本對應的正確輸出,比如我們要識別的圖片是數字7,則k=7,選擇softmax的第7個輸出值來計算loss)。一般我們進行訓練時一批圖片有多張,比如batch size = 16,則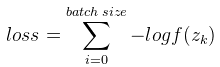 。
。由於我們的輸入為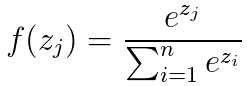
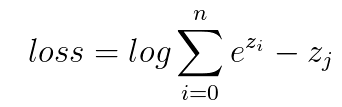
若loss對每個輸入z求導,則有