
AI晶片:深鑑科技基於深度壓縮的FPGA設計
眾所周知,深度學習屬於計算密集型,模型中引數眾多,佔用很大的儲存空間。這一特點,在嵌入式終端上應用時,因為硬體資源有限,就成了制約實際應用的瓶頸。
因此,減少模型需要的儲存空間有著迫切的理論及現實意義。
深鑑科技的創始人韓鬆,本科畢業於清華大學,斯坦福博士,目前在MIT,一直研究深度壓縮技術,並在FPGA上實現了基於深度壓縮技術的ESE,成果發表為論文。
本文主要是分析韓鬆的2篇論文,來一窺深度壓縮的玄妙。
2篇論文,一篇關於深度壓縮技術,一篇關於深度壓縮技術在語音識別上的FPGA方案ESE。
論文如下:
(1)Deep Compression:Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
(2)ESE:Efficient Speech Recognition Engine with Sparse LSTM on FPGA
下文首先分析深度學習技術,然後再看看深度學習技術的FPGA實現。
一、Deep Compression
論文主要介紹採用深度壓縮技術儲存深度學習神經網路模型的大量權重,將所需的儲存空間壓縮數十倍之多,並且並不損傷模型的準確性。
總體來說,深度壓縮技術比較有現實意義,值得細細品味。
深度壓縮技術,採用剪枝+量化+霍夫曼編碼,形成三級大流水,如圖1所示,實現高度壓縮權重佔用的儲存空間。
在硬體上計算模型時,需要將經過深度壓縮儲存的權重值重新解壓縮。
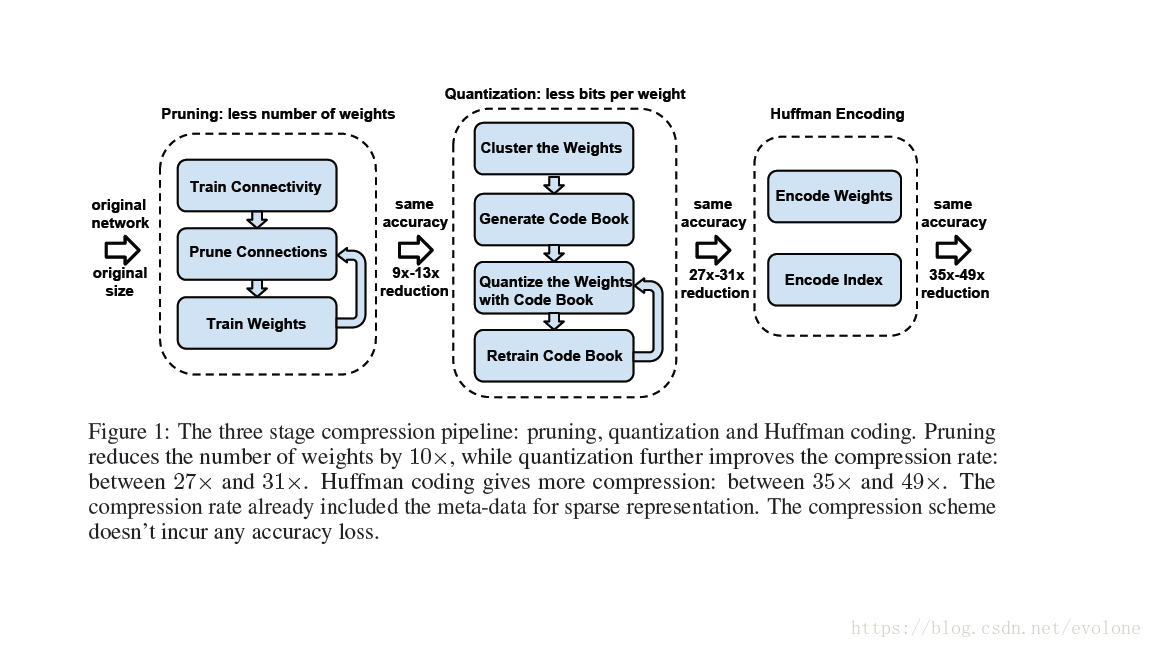
圖1 三級壓縮流水線
由圖1可知,剪枝(pruning)會減少weights的數量,量化(quantization)會減少weights的種類,都對網路模型的準確性造成影響,因此都需要反覆訓練網路達到原始網路的準確精度。而霍夫曼編碼(huffman encoding)並不修改weights的數量,只是改變編碼方式,並不影響網路的精度。

圖2壓縮儲存稀疏矩陣
經過剪枝和量化之後的weight矩陣,是稀疏矩陣,如果依然將矩陣的所有存元素(非0元素和0元素)都儲存,那麼儲存空間依然和原來的一樣,但是,如果只儲存非0元素(可能只佔總數的10%,甚至更少),就能大幅度減少儲存空間,達到壓縮儲存的目的。
本文采用相鄰非0元素之間的相對距離來儲存非0元素,如圖2所示。其中表格第二行diff,代表相鄰非0元素之間的相對位置。這樣有個缺點,就是從壓縮儲存的weight恢復成矩陣模樣需要按順序解碼,這樣解碼就是序列的。另外,本文只採用3bits編碼間隔,最大間隔為7,意思是說,假設相鄰兩個非0元素的間隔不超過是7。如果超過了7,就插入0作為中轉,並記錄下來。
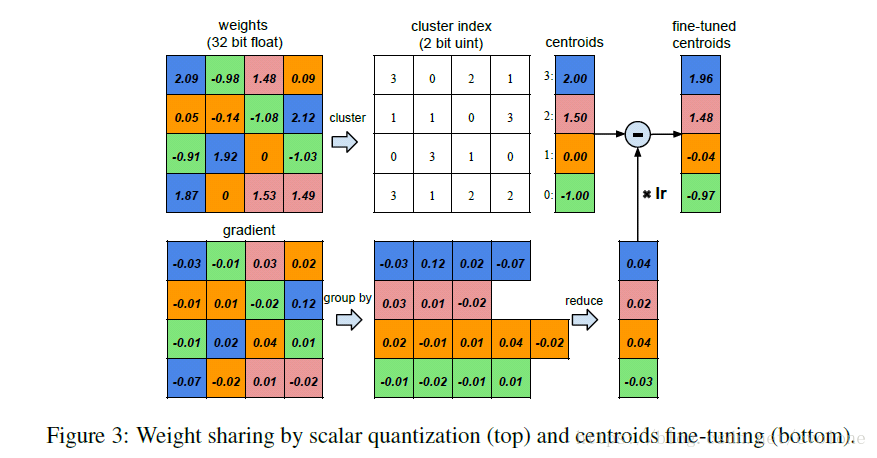
圖3 權重的量化共享
如圖3所示,為training過程中計算並更新weight的過程。
首先看左側的兩個圖,左上圖為權重weight,左下圖為梯度,都是4X4的矩陣。
觀察weight矩陣的元素值,發現16個元素的取值大小其實可以劃分成4個類,由四種顏色區分,相同顏色的weight用一個統一的值代表,這就是權值共享。這樣可以形成一個共享weight查詢表,這裡因為只分成4種,故可以只用2bits去編碼並替代原來的32bits的浮點數,如圖3中間的cluster index所示,實際計算時,根據2bits的編碼去查詢正確的32bits權值。
根據左上圖的四種顏色分類將左下圖的梯度值按照同樣的分組,將相同顏色的梯度值累加起來,然後與learning rate (lr)相乘,再與查詢表中對應的weight相減,得到更新後的權值。
真正在計算權值的分類時,採用的是k-means聚類方法。
另外,權值的聚類分類,只在同一層layer中有效,不能跨layer共享權值。
好吧,說了這麼多,那到底效果怎麼樣呢?
直接上圖。
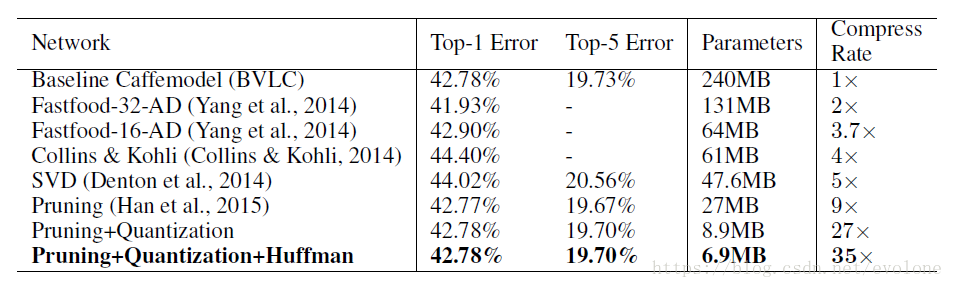
圖4 深度壓縮實驗結果
可以看出,在不損失模型準確度的前提下,模型引數引數由最原始的240M壓縮到6.9M,壓縮率達到驚人的35倍。
可以看出,深鑑科技的深度壓縮效果還是很驚人的。