
MPI之聚合通訊collective communication-廣播
一、前言
點對點的通訊學習已經通過一個案例完成了,現在開始新的一節:collective communication。聚合通訊是在通訊子中的所有的程序都參與的通訊方式。
二、聚合與同步
1、同步
對於所有的程序來說,聚合通訊必然包含了一個同步點。也就是說所有的程序必須在他們又一次執行新動作之前都到達某個點。這跟GPU中執行緒同步的概念很相似,很好理解。如果n個執行緒或者程序不遵守這個規矩,那麼就會發生有的執行緒或者程序正在寫某幾個暫存器的資料,而本應該都在寫或者等待都寫完再讀取的幾個程序或者執行緒卻在此時讀取了另外幾個暫存器的資料,那麼我想這樣資料沒有人敢用。
MPI_Barrier就是這樣的一個函式,他確保除非所有的程序同時呼叫,否則他不會拒絕任何程序通過這個節點。
MPI_Barrier(MPI_Comm communicator)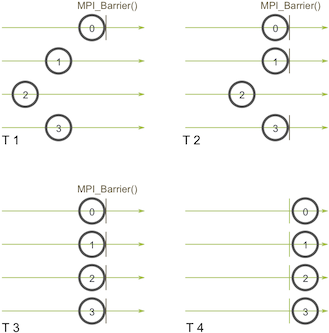
T1,T2時刻,都只有部分的程序再call MPI_Barrier,此時是沒有什麼鳥用的,只有當T3時刻時,才會通過。
最後,如果沒有MPI_Barrier,那麼任何聚合通訊都是浮雲。
2、廣播
廣播機制:
一個程序將相同的資料傳送給通訊子中所有的程序。
該機制最主要的應用是將輸入資料傳送給並行程式,或者將配置引數傳送給所有的程序。
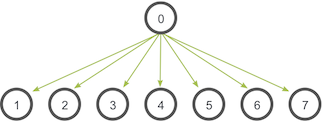
上圖中,0號執行緒是根程序,他儲存有最原始的資料的拷貝,其他所有的程序接收這些資料的拷貝。
MPI_Bcast
MPI_Bcast(
void* data,//資料 雖然根程序和接收程序執行的是不同的任務,但是他們呼叫的是一樣的MPI_Bcast函式。當根程序呼叫的時候,void* data會被髮送到其他所有的程序中,如果是其他接收程序呼叫MPI_Bcast函式,void* data就會被根程序中的資料初始化。
實際上可以用MPI_Send 和 MPI_Recv 來實現,很naive
void my_bcast(void* data, int count, MPI_Datatype datatype, int 上述實現有個問題:假設每個程序只有一個輸入輸出的網路連線,那麼該程式就只有一個網路連線去讓0號程序去給所有的程序傳送資料。
更聰明的一種做法是樹狀通訊演算法:
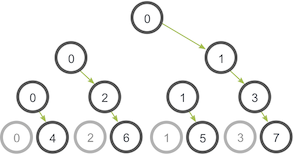
0號程序傳送資料給1號程序,然後0號程序也傳送資料給2號程序在樹的第二級上。不同的是1號程序現在也將資料傳送給3號程序,2號程序將資料傳送給6號程序。
根據上述思想自定義實現
明天再寫。。。