
譜聚類matlab演算法實現及詳解
阿新 • • 發佈:2019-02-16
此時此景,我想先講個故事。我哈哈哈。
譜聚類(spectral clustering)的思想最早可以追溯到一個古老的希臘傳說,話說當時有一個公主,由於其父王去世後,長兄上位,想獨攬大權,便殺害了她的丈夫,而為逃命,公主來到了一個部落,想與當地的酋長買一塊地,於是將身上的金銀財寶與酋長換了一塊牛皮,且與酋長約定只要這塊牛皮所佔之地即可。聰明的酋長覺得這買賣可行,於是乎便答應了。殊不知,公主把牛皮撕成一條條,沿著海岸線,足足圍出了一個城市。(這是我從別人那裡抄的。)
譜聚類的核心思想就是讓所分類內連線線的權值和最大,類之間連線線的權值和最小。權值越大,越相似。就這莫簡單,都可以用數學運算求出來的。能推匯出這個原理的真他麼牛B。
本文主要針對譜聚類的matlab程式做了一些註釋和說明。譜聚類主要分為兩步:1、構圖。2、切圖。它是圖論研究的分支之一。構圖的方法有三種:一、ε-neighborhood。二、k-nearest neighborhood即k近鄰法。三、fully-connected(本文所用)。
切圖有兩種方法:一、Retio-cut。二、N-cut()(本文所用)。
本文的譜聚類spectral clustering構圖用的是fully-connected,即鄰接矩陣W與相似矩陣相同。切圖用的是N-cut。3、在用K-means對拉普拉斯矩陣L從小到大的特徵值對應的特徵向量進行聚類,本文用的是倒數第一小和倒數第二小。要想理解建議先看理論在做理解。下面還是看具體的matlab實現吧,關鍵地方都做了註釋。
data = [4.8848 1.0673; -2.8681 -4.0956; 0.6969 4.9512; 4.9716 0.5319; -1.2985 -4.8284; -4.8493 1.2182; 0.7024 -4.9504; -1.3674 4.8094; -1.5181 -4.7640; 0.5733 -4.9670; -4.3832 -2.4058; -4.7152 -1.6634; -4.2404 -2.6494; -4.5369 -2.1015; -2.1619 4.5085; -4.8585 -1.1811; 4.7854 -1.4491; 3.8996 3.1294; -0.5561 4.9690; -2.9575 4.0315; 9.7921 -2.0286; -8.4303 5.3786; 8.8957 -4.5680; -4.4793 -8.9407; -9.1732 -3.9815; -8.8980 4.5634; 8.2141 -5.7034; 5.5402 -8.3250; -9.7634 2.1626; 2.4367 -9.6986; -3.4128 9.3996; 3.3661 -9.4164; -0.2576 9.9967; 9.6692 -2.5507; -7.9397 6.0796; -5.7559 -8.1774; -1.4651 -9.8921; 4.3449 -9.0068; -6.4241 -7.6636; 9.9996 -0.0901; -9.8780 -1.5573; 3.0273 9.5308; 4.1979 -9.0762; 7.2136 6.9256; -8.5106 5.2507; 8.9359 -4.4888; -7.3309 -6.8013; 9.3538 -3.5364; -9.9753 0.7018; -5.8005 8.1458] %%譜聚類spectral clustering。1、構圖用的是fully-connected,即鄰接矩陣W與相似矩陣相同 %%2、切圖。切圖用的是N-cut。L=D^-0.5*L*D^-0.5。3、在用K-means對L的特徵向量進行聚類, %%注意分及各類用幾個特徵向量。 % clc; % clear; % load('data.mat') % data = allpts figure(1) plot(data(:,1),data(:,2),'bo'); m = length(data); %% %% step1:構圖,計算鄰接矩陣W sigsq = 0.9; %高斯距離裡面的方差 Aisq = data(:,1).^2 + data(:,2).^2 Dotprod = data*data' distmat = repmat(Aisq,1,m) + repmat(Aisq',m,1) -2*Dotprod; %此處畫圖理解 Afast = exp(-distmat/(2*sigsq)); W = Afast; figure(2) subplot(2,3,2); imagesc(W);colorbar; %% step2:計算拉普拉斯矩陣L D = diag(sum(W)); %度矩陣degree matrix L = D-W; %拉普拉斯矩陣 L = D^-0.5*L*D^-0.5; %標準化,切圖我們用的是N-cut,所以要對拉普拉斯矩陣作標準化處理,使得量綱一致 subplot(2,3,3) imagesc(L);colorbar; %% step3:切圖。 [X,di] = eig(L); [Xsort,Dsort] = eigsorts(X,di); %將特徵值按照從小到大的順序排列,特徵向量跟隨做相應變化。 Xuse = Xsort(:,1:2); %取第一列與第二列,因為要分成k=2,即要分成兩類。 subplot(2,3,4) imagesc(Xuse);colorbar; Xsq = Xuse.*Xuse; divmat = repmat(sqrt(sum(Xsq')'),1,2); Y = Xuse./divmat %將Xuse標準化 subplot(2,3,5) imagesc(Y);colorbar; %% step4:用k-means均值聚類對Y進行聚類 [c,Dsum,z] = kmeans(Y,2); c1 = find(c==1); c2 = find(c==2); subplot(2,3,6) plot(data(c1,1),data(c1,2),'co') hold on; plot(data(c2,1),data(c2,2),'mo') title('譜聚類'); %% 畫出kmenas聚類對元資料聚類效果 [cc,Dsum2,z2] = kmeans(data,2); subplot(2,3,1) kk = cc; c1 = find(cc==1); c2 = find(cc==2); plot(data(c1,1),data(c1,2),'bo') hold on; plot(data(c2,1),data(c2,2),'ro') title('均值聚類');
function [Vsort,Dsort] = eigsorts(V,D) %拉普拉斯矩陣的特徵向量V與特徵值D
d = diag(D);
[Ds,s] = sort(d); %從小到大排列
Dsort = diag(Ds);
M = length(D);
Vsort = zeros(M,M)
for i = 1:M
Vsort(:,i) = V(:,s(i));
end
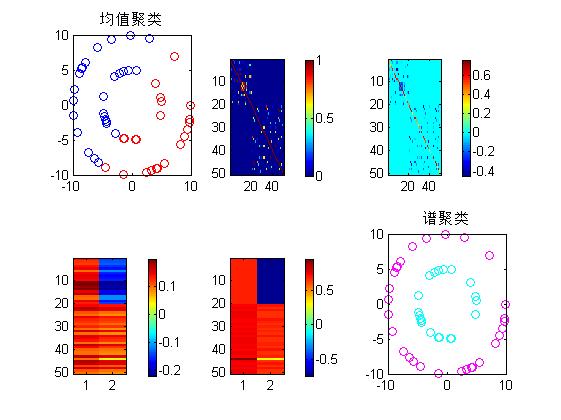
多麼漂亮的圖啊。