
CNN卷積神經網路實現MNIST識別
MNIST是手寫的資料庫,由Yann LeCun釋出,http://yann.lecun.com/exdb/lenet/index.html Tensorflow也把資料庫裡的東西封裝成方法,通過CNN卷積神經網路實現MNIST資料識別。
下載並安裝MNIST資料集,分為訓練集、測試集和驗證集,每個有55000張圖片,每張圖片大小為28*28,784畫素。
from tensorflow examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('mnist_data', one_hot = True)mnist_data是自己取的資料集名稱,存放在當前的py檔案位置。
one_hot是獨熱碼,例如1為0100000000,2為00100000000,以此類推。若為False,數字就為1、2、3…
構建實驗資料
input_x = tf.placeholder(tf.float32, [None, 28*28])/255.
output_y = tf.placeholder(tf.int32, [None, 10])
input_x_images = tf.reshape(train_x, [-1, 28, 28, 1])輸入是28*28畫素的圖片,輸出是1*1*10的預測。
構建卷積神經網路
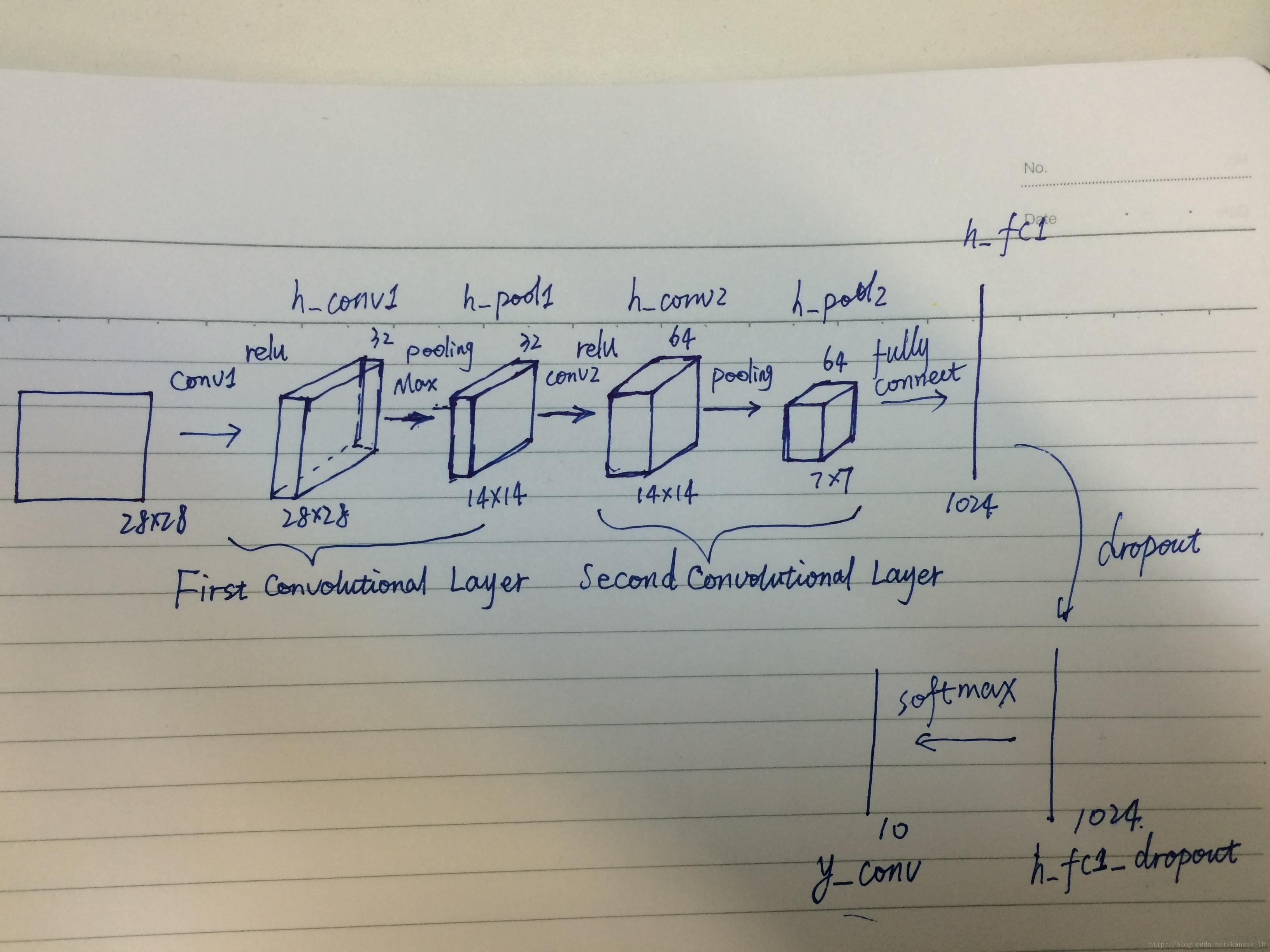
輸入為28*28的圖片,經過卷積—池化—卷積—池化—扁平化—1024的全連線層—1*1*10的全連線層—圖片預測。
這裡拿了網圖作為參考233,輸入28*28*1的灰度圖,乘1表示灰度圖,只有一個顏色,不是RGB的彩色圖。
從測試的資料集裡選取3000個手寫數字的圖片和對應標籤。
test_x = mnist.test.images[:3000]
test_y = mnist.test.labels[:3000]構建第一層卷積,用5×5的過濾器(filter又叫kernel),從左上角到右下角照這張圖,32個filter每掃一遍增加一層,depth為32。輸入的28*28*1的影象經過第一層卷積後變為28*28*32。
conv1 = tf.layers.conv2d(
inputs=input_x_images,
filters=32,
kernel_size=[5 這裡的步長設為1,padding為’same’表示輸出的大小不變,需要在外圍補兩圈0,啟用函式使用relu。經過第一層卷積神經網路後,形狀會變為[28, 28, 32]。接著進行第一層池化,又叫亞取樣。
pool1 = tf.layers.max_pooling2d(
inputs=conv1,
pool_size=[2, 2],
strides=2
) 池化層的輸入為卷積層的輸出,選用二維平面大小為[2, 2]的過濾器,步長選為2,不改變深度,池化層最終的輸出形狀為[14, 14, 32]。接著進行第二層卷積。
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
strides=1,
padding='same',
activation=tf.nn.relu
) 第二層卷積採用64個過濾器,過濾器在二維的大小為[5, 5],步長為1,生成的形狀為[14, 14, 64]。
pool2 = tf.layers.max_pooling2d(
inputs=conv2,
pool_size=[2, 2],
strides=2
)經過第二層池化後生成的形狀為[7, 7, 64],進行平坦化操作,將圖形壓成1×1。並進行dropout。
flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
logits = tf.layers.dense(inputs=dropout, units=10)-1表示根據以後的確定的引數推斷出這個位置上維度的大小。
最後計算誤差,計算cross entropy交叉熵,再用softmax計算百分比概率。隨後用Adam優化器進行優化,學習率為0.001。
loss = tf.losses.softmax_cross_entropy(onehot_labels=output_y, logits=logits)
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
accuracy = tf.metrics.accuracy(
labels=tf.argmax(output_y, axis=1),
predictions=tf.argmax(logits, axis=1),)[1]
accuracy是計算預測值與實際標籤的匹配程度,會建立accuracy和update_op兩個區域性變數。
最後最後,建立會話,初始化變數,進行訓練。
sess = tf.Session()
init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init)
for i in range(20000):
batch = mnist.train.next_batch(50)
train_loss, train_op_ = sess.run([loss, train_op], {input_x: batch[0], output_y: batch[1]})
if i % 100 == 0:
test_accuracy = sess.run(accuracy, {input_x: test_x, output_y: test_y})
print("Step=%d, Train loss=%.4f, [Test accuracy=%.2f]") \
% (i, train_loss, test_accuracy)