
流量整形,延遲以及ACK丟失對TCP發送時序的影響
阿新 • • 發佈:2019-02-16
解析 article 單純 希望 cpp 忘記 spa 網絡設備 理論 TCP是一個連續不斷的涓涓細流或者滾滾長江,但這只是理想情況!經過諸多中間網絡設備,最終一個TCP流到達接收端的時候,將可能不再保持一個流的形式,而變成了一陣陣的突發...這些突發產生的ACK反過來反饋到發送端,進而對發送端的發送時序產生影響,也就是說對發送端的數據流進行整形,這真是一個典型的渦輪增壓反饋系統,根本不是通常認為的那樣不可控或者說另一個極端,僅僅是端到端!想駕馭它其實不是那麽難,如果有人說僅僅可以靠感覺就可以駕馭它,倒不如說它本來就是1+1=2那般有條有理。如果覺得TCP的行為很難理解,可能只是因為你在試圖破壞網絡的規則,網絡的規則只有兩點:效率和公平。真的,殺一個人很容易,卻代價高昂,與人相處,很難,卻可以細水長流終一生!
本文介紹一下網絡對TCP發送端時序的影響如何在報文序列上體現出來,使用Wireshark。
TCP的擁塞窗口並未體現在數據包本身,它完全是端到端利用網絡的反饋信息通過協議棧自己算出來的,這種反饋包括ACK序列以及超時事件等。那麽如何通過Wireshark展示的一個TCP流的包序列分析出TCP的擁塞窗口大小呢。
其實很簡單,只要算出in flight的數量即可。TCP的發送窗口等於擁塞窗口(cwnd)與對端通告窗口(awnd)中的最小值:
wnd=min(awnd,cwnd)
如果cwnd比awnd大,那可以不關註cwnd,因此其對數據發送無影響(TCP自帶了擁塞窗口限制機制,使其不會大得太多,此為制止突發),因此只關註cwnd小於awnd的情形,此時:
wnd=cwnd
我們知道,在TCP形成一個連續的ACK時鐘後,發送是平緩的,所謂的平緩指的是發送行為基於網絡上的數據包守恒原則,被確認一個,發送一個,因此:
cwnd=in flight+tosend
tosend是我們將要發送的數據包數量,按照數據包守恒,可以認為tosend是當前被ACK的數據量,按照段數計數,如果接收端未啟用delay ACK,那麽每次將ACK一個段,即:
cwnd=in flight+1
看上面的公式時,請暫時忘記擁塞窗口的突變,後面會講。接下來,如果對端啟用了delay ACK,那麽每次將最多ACK 2個段,即:
cwnd=in flight+max(thisACKed,2)
請暫時忘記ACK丟失的情況,這個普遍可能發生的現象會在TCP發送端到底是數ACK的數量還是數ACK確認的字節數之間引發爭議,我個人傾向於這個選擇交給TCP自己來做,這充分考慮到昂貴的無線鏈路中帶寬的前向後向不對稱性。然後考慮到擁塞避免階段,我們可以認為:
cwnd=cwnd+(1/cwnd|1)
如果在慢啟動階段,則:
cwnd=cwnd+1
因此,最終我們可得到擁塞窗口的大小:
cwnd=in flight+max(thisACKed,2)+(1/cwnd|1)
現在的問題是如何去求in flight的大小。非常簡單,公式如下:
in flight=當前發送到的-當前最後被確認的
我們用一個實際的抓包結果來確認一下,在此之前說明,Wireshark可以為你分析出大多數的in flight報文,只要它能精確確認兩個數值:當前發送到的序列號以及當前最後被確認的序列號。因此你可以不必自己去按照上述公式自己去計算,而是直接通過Wireshark就可以看到。我先展示一個確認包:
有的時候,你可能會發現點擊Wireshark中某個數據包的時候,並沒有展示出in flight的值,那是因為前面有些數據包沒有抓到,而且這些未抓取到的數據包和當前數據包之間又沒有ACK包,所以不足以提供上述計算in flight值所需要的元素,因此就不會替你計算,不是沒有,而是丟失了信息,計算不出來而已。
但是有的時候,有人完全迷信Wireshark的結果(其實說的就包括我自己),所以造成了令人遺憾又可悲的結果。這到底是怎麽回事呢?且看下節。
tc qdisc add dev eth0 root netem delay 300ms
然後同樣在TCP發送端進行tcpdump抓包,然後用Wireshark來解析。
我們來看3064號ACK包到達發送端時候的情景:
要想明確知道原因,需要對抓包的位置有足夠的理解。tcpprobe顯示的是TCP棧那裏的情景,而tcpdump抓取的確實網卡邊界的情景,中間隔了一個“qdisc”邏輯,即隊列管理。也就是說TCP確實將732個數據段發出去了,因此它會認為其已經in flight了,但是這些數據並沒有到達網上,而是到達了qdisc隊列裏面,考慮到是千兆網絡同一網段的模擬,基本可以忽略傳輸延遲,因此tcpdump抓取的所謂in flight只是qdisc後面到達接收端的in flight。如果用端到端的觀點,qdisc確實也是sky的一部分,但是對於tcpdump附著的網卡來講,qdisc只是一個island,我想這就是區別:
在以上兩類反饋信號分別允許發送的數據量E和W中取最小的值作為發送量,這樣可以同時滿足二者的限制。
需要記住的是,發多少數據並不是擁塞窗口決定的,而是對端通告窗口決定的,這個決定由ACK時鐘流反饋到發送端,收到ACK後執行數據包守恒,放出被ACK的數據量,發送端理論上還可以發送通告窗口大小的數據,但要問一下網絡情況是否允許發送這麽多,這就是擁塞窗口的作用,它的增減是一個獨立的過程!唯一和別的邏輯交互的點在於:它的值減去in flight的值就是還可以發送的數據量,當它大於最大允許的突發時,擁塞窗口將不再增長,還是那句話,擁塞窗口不能突發增長,這是個反饋系統,只有反饋信號才能誘導窗口增長,所有的擁塞控制算法都在保證增窗是加性的,即緩慢的,一來這是線性控制系統中收斂性的要求,二來它可以讓擁塞控制系統捕獲到突發,從而禁止擁塞窗口的進一步增長以加重突發,最終造成網絡擁塞。這裏說的反饋信號就是本節開頭描述的那兩種反饋信號。
1).對端的接收端窗口容納的最高序列號線,階梯形。
2).發送端發出的序列號以及長度線,典型呈現“工”形。
3).接收端ACK的序列號線,階梯形
以下圖示簡單描述了上述的三類線:
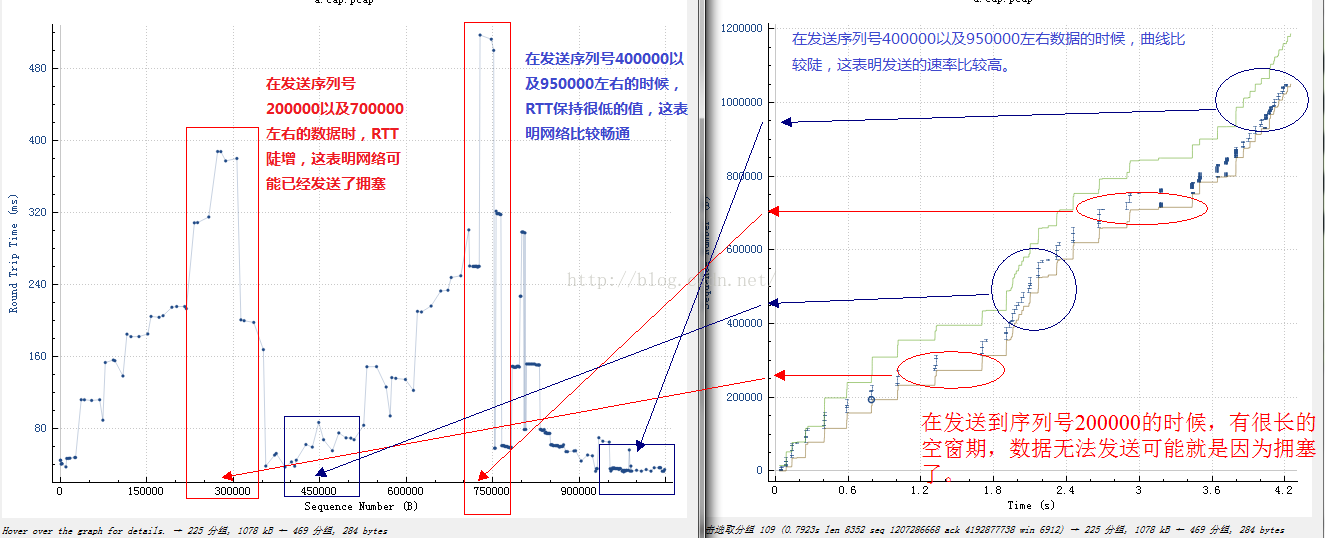
1).RTT不會緩增緩降(線性的),而是陡增陡降的(指數級),這是網絡排隊的本質決定的;
2).是RTT的變化率而不是RTT本身描述了網絡的情況,RTT可能是固有的,需要關註的是其變化率;
3).觀察RTT的變化率應從以下兩方面入手:
a.對變化率求導,甚至二階導數,找出拐點,預測隊列清空以及繼續排隊。事件發生的時候,TCP收到反饋後怕是來不及反應;
b.RTT持平的時候,可以過濾出噪聲丟包,這種信號如果能被TCP發送端捕獲,將不必乘性減窗而重傳。
下面展示一下從Wireshark的時間/序列號圖以及RTT/序列號的對比:
ACK是發送端的時鐘!
如果連續的ACK丟失了,就會出現一個ACK確認了大塊數據的場景,由於前面ACK連續丟失,發送端久久未收到時鐘反饋導致數據不能發送,但其實就像帶突發的令牌桶一樣,這段時間內需要發送但未發送的數據可能被積累了,一旦收到一個確認很多數據的ACK,TCP希望這個ACK作為一個積累令牌可以補償ACK丟失帶來的空窗期,但是這樣做是有問題的,它可能會造成突發。因此TCP把這個策略的選擇留給了用戶,TCP有兩個選擇,一個是按照ACK確認的數據量來反饋,一個是按照單純的ACK包的數量來反饋,前一種選擇更精細,然而後一種選擇則更加真實的反饋了網絡情況。
值得註意的是,整個互聯網中已經有相當的百分比的數據包是單純的裸ACK包了,作為一種控制信令,它已經跟數據本身一樣縱橫逍遙在互聯網各個鏈路中了。
本文介紹一下網絡對TCP發送端時序的影響如何在報文序列上體現出來,使用Wireshark。
1.如何Wireshark看TCP擁塞窗口的大小
TCP的擁塞窗口並未體現在數據包本身,它完全是端到端利用網絡的反饋信息通過協議棧自己算出來的,這種反饋包括ACK序列以及超時事件等。那麽如何通過Wireshark展示的一個TCP流的包序列分析出TCP的擁塞窗口大小呢。
其實很簡單,只要算出in flight的數量即可。TCP的發送窗口等於擁塞窗口(cwnd)與對端通告窗口(awnd)中的最小值:
wnd=min(awnd,cwnd)
如果cwnd比awnd大,那可以不關註cwnd,因此其對數據發送無影響(TCP自帶了擁塞窗口限制機制,使其不會大得太多,此為制止突發),因此只關註cwnd小於awnd的情形,此時:
wnd=cwnd
我們知道,在TCP形成一個連續的ACK時鐘後,發送是平緩的,所謂的平緩指的是發送行為基於網絡上的數據包守恒原則,被確認一個,發送一個,因此:
cwnd=in flight+tosend
tosend是我們將要發送的數據包數量,按照數據包守恒,可以認為tosend是當前被ACK的數據量,按照段數計數,如果接收端未啟用delay ACK,那麽每次將ACK一個段,即:
cwnd=in flight+1
看上面的公式時,請暫時忘記擁塞窗口的突變,後面會講。接下來,如果對端啟用了delay ACK,那麽每次將最多ACK 2個段,即:
cwnd=in flight+max(thisACKed,2)
請暫時忘記ACK丟失的情況,這個普遍可能發生的現象會在TCP發送端到底是數ACK的數量還是數ACK確認的字節數之間引發爭議,我個人傾向於這個選擇交給TCP自己來做,這充分考慮到昂貴的無線鏈路中帶寬的前向後向不對稱性。然後考慮到擁塞避免階段,我們可以認為:
cwnd=cwnd+(1/cwnd|1)
如果在慢啟動階段,則:
cwnd=cwnd+1
因此,最終我們可得到擁塞窗口的大小:
cwnd=in flight+max(thisACKed,2)+(1/cwnd|1)
現在的問題是如何去求in flight的大小。非常簡單,公式如下:
in flight=當前發送到的-當前最後被確認的
我們用一個實際的抓包結果來確認一下,在此之前說明,Wireshark可以為你分析出大多數的in flight報文,只要它能精確確認兩個數值:當前發送到的序列號以及當前最後被確認的序列號。因此你可以不必自己去按照上述公式自己去計算,而是直接通過Wireshark就可以看到。我先展示一個確認包:
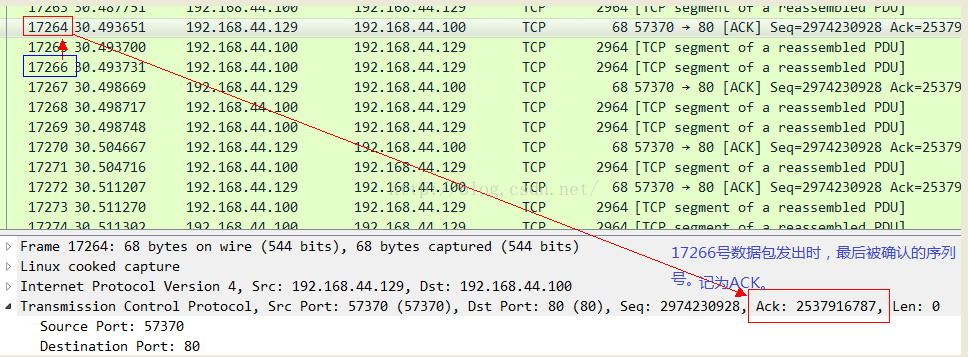
然後看一下到此為止發送的數據包的序列號:
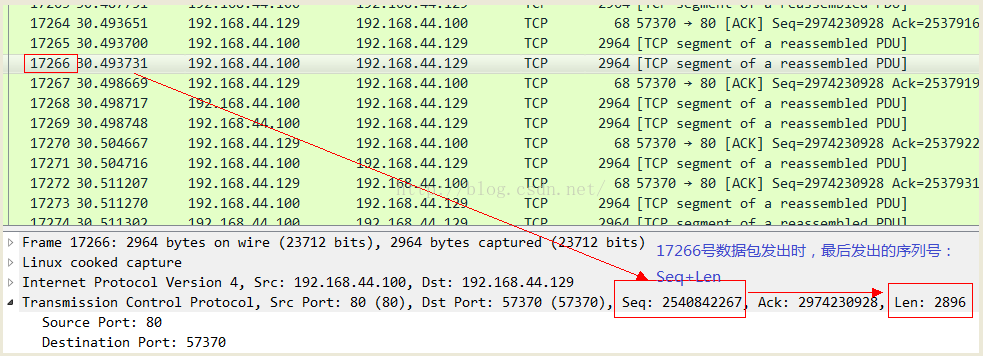
最後我們算一下in flight的數量以及Wireshark展示的相應的值:
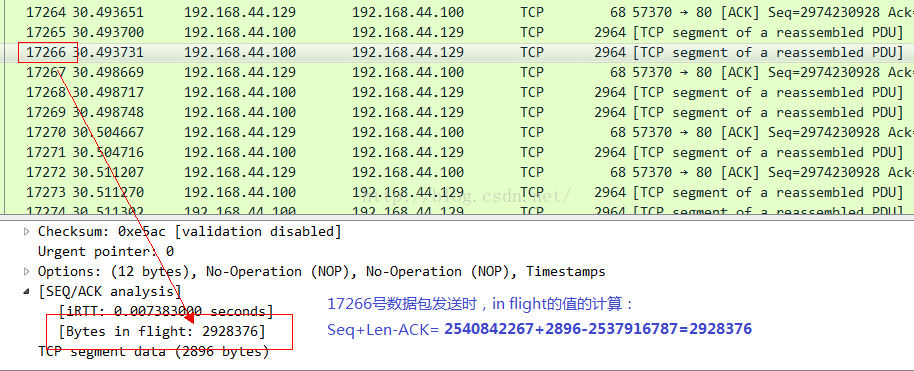
它們是完全一致的!
有的時候,你可能會發現點擊Wireshark中某個數據包的時候,並沒有展示出in flight的值,那是因為前面有些數據包沒有抓到,而且這些未抓取到的數據包和當前數據包之間又沒有ACK包,所以不足以提供上述計算in flight值所需要的元素,因此就不會替你計算,不是沒有,而是丟失了信息,計算不出來而已。
但是有的時候,有人完全迷信Wireshark的結果(其實說的就包括我自己),所以造成了令人遺憾又可悲的結果。這到底是怎麽回事呢?且看下節。
2.多余的數據包flight到哪兒了?
我做了一個測試,在TCP的發送端加入下列命令模擬一個300ms的數據包延遲:tc qdisc add dev eth0 root netem delay 300ms
然後同樣在TCP發送端進行tcpdump抓包,然後用Wireshark來解析。
我們來看3064號ACK包到達發送端時候的情景:
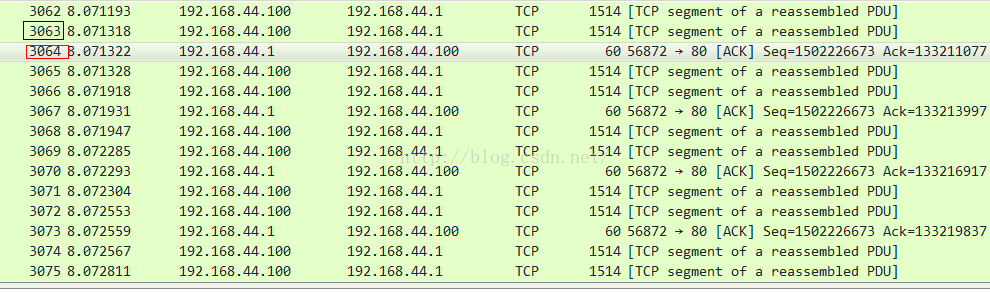
在收到該ACK包之前,發送端發送的最後一個數據包是3063號包,從3063號包中可以看到in flight的大小(見前面計算方法),數據包裏顯示的in flight只有不到5個數據包,而這是幾乎不可能的,我只是在千兆網絡上模擬了一個300ms的延遲而已。此時同步用tcpprobe抓取內核協議棧的相關信息,二者的比較如下所示:
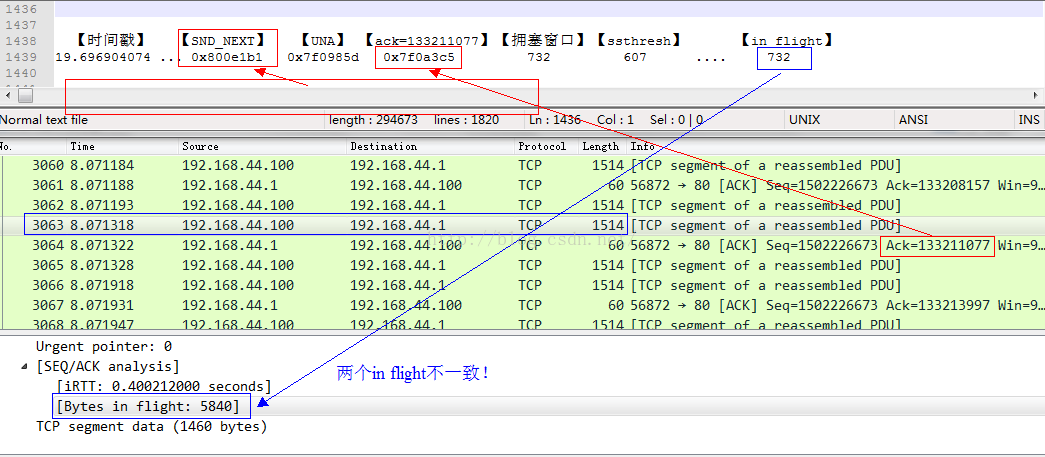
為了展示協議棧裏面in flight的值,我修改了tcpprobe,加入了tcp_packets_in_flight(tp)的統計。可以看到732*1460這個大小和Wireshark展示的5840相差甚遠!缺失的那些數據flight到哪裏了?根據tcpprobe的同一行展示的SND_NXT,我們在Wireshark裏面找相關信息:
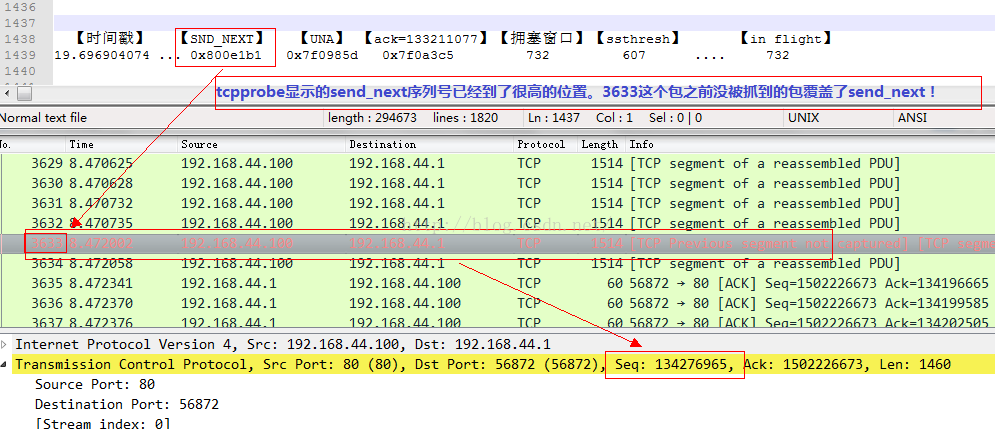
3633號包和3063號包之間正好相隔570個包,加上3063號包那裏已經計算的4個包,一共也才574到575個包,而tcpprobe顯示的是732個數據包in flight,那些缺失的哪裏去了?這個是因為tcpdump在抓包的時候,由於packet套接字的效率問題,緩沖區爆滿,被kernel丟棄了。這就是抓包時顯示的“142 packets dropped by kernel”所表達的含義。
要想明確知道原因,需要對抓包的位置有足夠的理解。tcpprobe顯示的是TCP棧那裏的情景,而tcpdump抓取的確實網卡邊界的情景,中間隔了一個“qdisc”邏輯,即隊列管理。也就是說TCP確實將732個數據段發出去了,因此它會認為其已經in flight了,但是這些數據並沒有到達網上,而是到達了qdisc隊列裏面,考慮到是千兆網絡同一網段的模擬,基本可以忽略傳輸延遲,因此tcpdump抓取的所謂in flight只是qdisc後面到達接收端的in flight。如果用端到端的觀點,qdisc確實也是sky的一部分,但是對於tcpdump附著的網卡來講,qdisc只是一個island,我想這就是區別:
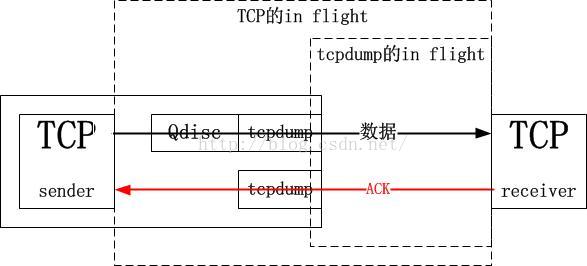
這下上面的疑問應該可以解釋了。接下來我先扯一點理論方面的東西。
3.插一點理論:擁塞窗口自動變速調節
TCP發送端基於ACK帶來的反饋信號發送數據:1).端到端的數據包守恒反饋
在接收端通告窗口允許的範圍內執行數據守恒策略,接收端確認了多少數據就再發多少數據,記為E。2).網絡擁塞狀況反饋
根據ACK確認到達的速率,其字段中算出的RTT以及被確認的數據量來增減擁塞窗口,執行加性增乘性減邏輯以保證收斂。在擁塞窗口允許範圍內最大限度發送發送通告窗口內的數據,記為W。在以上兩類反饋信號分別允許發送的數據量E和W中取最小的值作為發送量,這樣可以同時滿足二者的限制。
需要記住的是,發多少數據並不是擁塞窗口決定的,而是對端通告窗口決定的,這個決定由ACK時鐘流反饋到發送端,收到ACK後執行數據包守恒,放出被ACK的數據量,發送端理論上還可以發送通告窗口大小的數據,但要問一下網絡情況是否允許發送這麽多,這就是擁塞窗口的作用,它的增減是一個獨立的過程!唯一和別的邏輯交互的點在於:它的值減去in flight的值就是還可以發送的數據量,當它大於最大允許的突發時,擁塞窗口將不再增長,還是那句話,擁塞窗口不能突發增長,這是個反饋系統,只有反饋信號才能誘導窗口增長,所有的擁塞控制算法都在保證增窗是加性的,即緩慢的,一來這是線性控制系統中收斂性的要求,二來它可以讓擁塞控制系統捕獲到突發,從而禁止擁塞窗口的進一步增長以加重突發,最終造成網絡擁塞。這裏說的反饋信號就是本節開頭描述的那兩種反饋信號。
如果你讀過Linux的TCP協議實現的代碼,我想你應該知道,收到ACK後,可發送的數據量大於一個可承受突發後將不會執行擁塞避免邏輯,由於窗口是緩慢增加的,一旦增加到超過一個突發的節奏,就會馬上被拉回來,拉回到in flight的位置。如果你沒讀過,就看看RFC,然後...算了,請記住這個結論。我本來想把這個反饋系統按照控制論的機理畫個圖出來,但還是覺得多此一舉,還是直接看數據包吧。且看下節。
4.陣發發送與平緩發送
在描述這個問題前,我先給出一個關於Wireshark的“統計-TCP流圖形-時間序列(tcptrace)”圖的一個查看方法。我不建議看Stenves,因為它的信息不全。在tcptrace圖中,我們可以看到三條線:1).對端的接收端窗口容納的最高序列號線,階梯形。
2).發送端發出的序列號以及長度線,典型呈現“工”形。
3).接收端ACK的序列號線,階梯形
以下圖示簡單描述了上述的三類線:
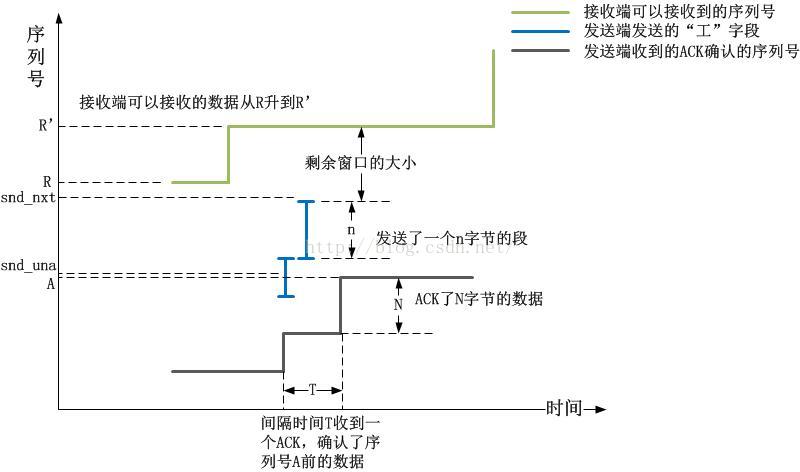
按照軸線圖標以及解釋,我覺得可以說明一切了,所有的情況,畫一條垂直於水平面的線,就是有用的線,它就是代表了窗口。接下來準備一些環境和數據吧。抓取一個TCP流,用Wireshark看,點擊“統計-TCP流圖形-時間序列(tcptrace)”,可以看到一張圖,遠看,它是這個樣子:
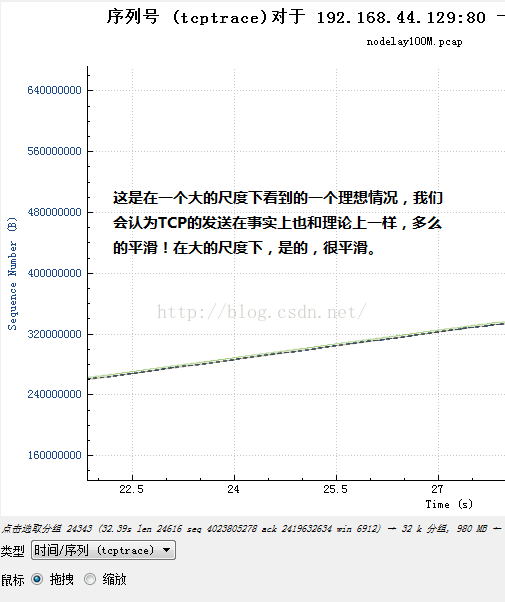
可是縮放以後近看,它可能是這個樣子:
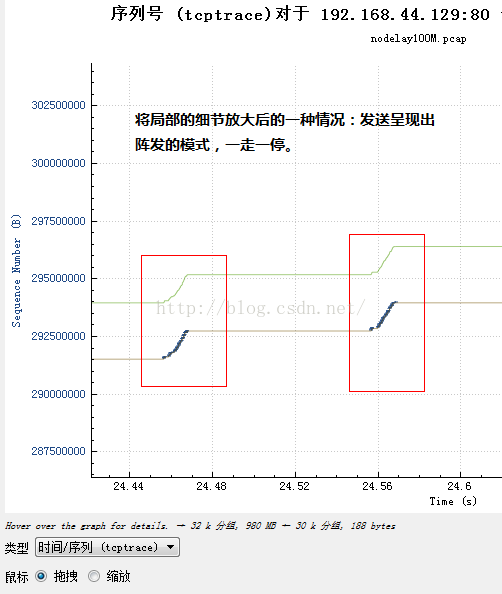
或者說是這個樣子:
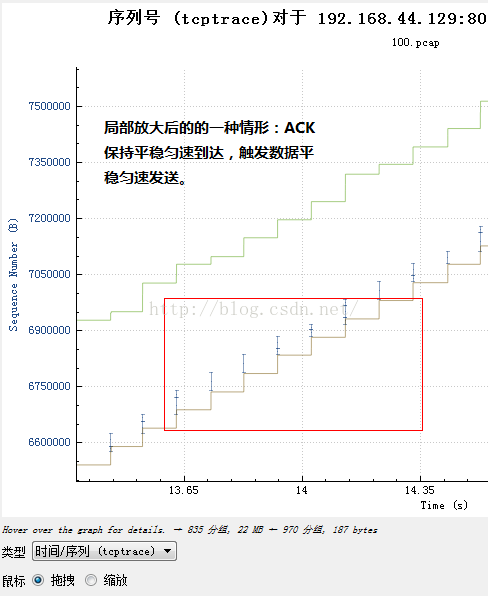
怎麽回事呢?正常情況,如果一個TCP流按照常規手段達到一個“平衡”的位置,那麽TCP的數據和這些數據產生的ACK序列就構成一個閉合的環形,應該是等距間隔到達的ACK觸發平滑的數據發送,可是為什麽不是這樣呢?是什麽導致了上述兩幅圖的差異呢?我們繼續把圖放大來看。對於那種陣發發送的序列,我們放大發送數據的那一部分:
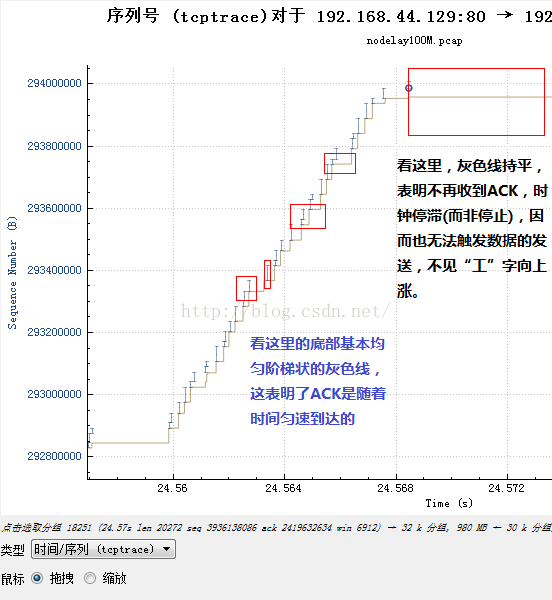
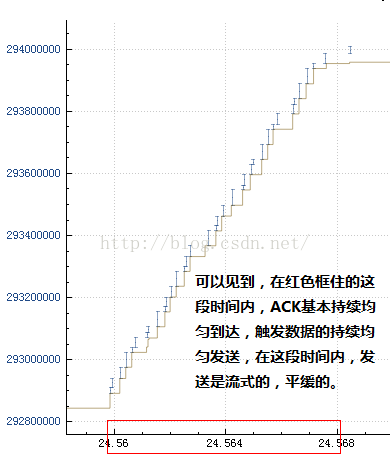
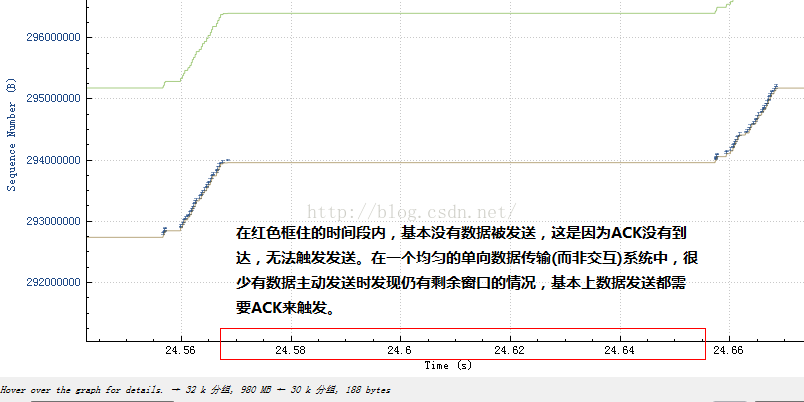
然後再結合不發送數據的那一部分:
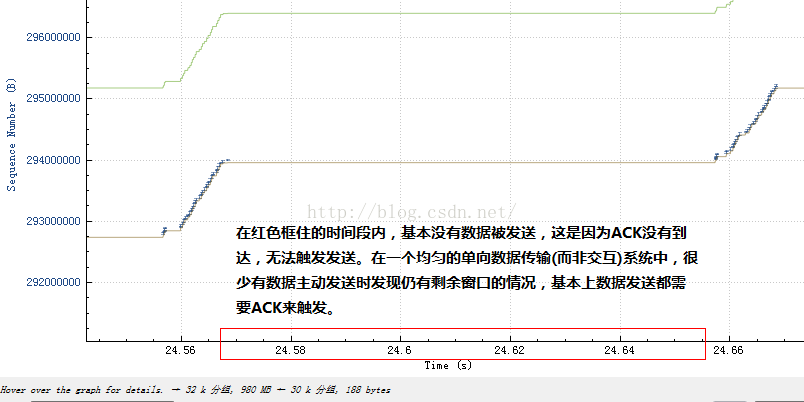
看到什麽了嗎?在發送數據的那部分,ACK是持續到來的,而在不發送數據的那一刻,ACK並無到來!由於TCP的發送是ACK驅動的,因此我們可以認為,是ACK的陣發導致了數據的陣發發送!那麽ACK為何會陣發到達呢?在發送端一再堅持平緩pacing發送的前提下,原因肯定是中間設備阻滯了數據包序列,然後分批放行,導致數據包分批到達接收端,然後分批產生ACK,進而造成了分批觸發新的數據,由此反復循環!
具體可以看一下流量整形的細節,本文不再描述。最簡單的就是統一設置一個延時,由於TCP是由慢啟動開始的,因此一開始數據量只是初始窗口大小的一小段,然後等待這段數據的ACK,再發送另外的段,這種陣發模式將會由於統一延時而被保持下去,即便是數據已經塞滿了網絡,也還是會保持下去。事實上由於統一延時也是一堵時間墻,因此僅僅設置一個統一的延時,並無法真正模擬“長肥管道”,雖然長肥管道裏的數據包也是統一延時的,但這些延時是時間展開的,tc設置的統一延時則是時間阻滯的,因此,設置統一延時後,除了你會看到窗口大增之外,和長肥管道一點也不像。
5.如何從RTT看網絡擁塞
下面我們來看一下RTT對數據發送的影響,這方面的理論已經爛大街了,所以我不想一再重復。結論如下:1).RTT不會緩增緩降(線性的),而是陡增陡降的(指數級),這是網絡排隊的本質決定的;
2).是RTT的變化率而不是RTT本身描述了網絡的情況,RTT可能是固有的,需要關註的是其變化率;
3).觀察RTT的變化率應從以下兩方面入手:
a.對變化率求導,甚至二階導數,找出拐點,預測隊列清空以及繼續排隊。事件發生的時候,TCP收到反饋後怕是來不及反應;
b.RTT持平的時候,可以過濾出噪聲丟包,這種信號如果能被TCP發送端捕獲,將不必乘性減窗而重傳。
下面展示一下從Wireshark的時間/序列號圖以及RTT/序列號的對比:
6.ACK丟失的情況
最後我們來看下ACK丟失會怎樣。通常人們很難想象ACK會丟失,也不會在乎ACK丟失的後果,人們總是僅僅關註手頭上正在做的,比如TCP數據的發送。ACK是可能丟失的,並且ACK不會被ACK,因此不會被重傳,TCP接收端記得住它接收到了哪裏,因此任意時刻它都能給出正確的ACK。問題是這對於發送端意味著什麽。ACK是發送端的時鐘!
如果連續的ACK丟失了,就會出現一個ACK確認了大塊數據的場景,由於前面ACK連續丟失,發送端久久未收到時鐘反饋導致數據不能發送,但其實就像帶突發的令牌桶一樣,這段時間內需要發送但未發送的數據可能被積累了,一旦收到一個確認很多數據的ACK,TCP希望這個ACK作為一個積累令牌可以補償ACK丟失帶來的空窗期,但是這樣做是有問題的,它可能會造成突發。因此TCP把這個策略的選擇留給了用戶,TCP有兩個選擇,一個是按照ACK確認的數據量來反饋,一個是按照單純的ACK包的數量來反饋,前一種選擇更精細,然而後一種選擇則更加真實的反饋了網絡情況。
值得註意的是,整個互聯網中已經有相當的百分比的數據包是單純的裸ACK包了,作為一種控制信令,它已經跟數據本身一樣縱橫逍遙在互聯網各個鏈路中了。
再分享一下我老師大神的人工智能教程吧。零基礎!通俗易懂!風趣幽默!還帶黃段子!希望你也加入到我們人工智能的隊伍中來!https://blog.csdn.net/jiangjunshow
流量整形,延遲以及ACK丟失對TCP發送時序的影響