
JDK1.8HashMap原始碼的簡單剖析(1)
HashMap原始碼的剖析
最近大家都在找實習,而對於Java方向的同學,面試最常問的也是Java集合中的Map,Map有那幾種,每種的簡單實現都是什麼,每種的使用場景都是什麼。
昨天去面試,結果被問到,面試官一般問的都是HashMap的原理,是怎麼實現的,然後裡面重要的幾個方法都是怎麼實現的。然後如果讓你實現一個HashMap,你會怎麼實現。
在瞭解HashMap之前,先理解一下雜湊表。
在討論雜湊表之前,先規範幾個接下來會用到的概念。雜湊表的本質是一個數組,陣列中每一個元素稱為一個箱子(bin),箱子中存放的是鍵值對。
雜湊表的儲存過程如下:
- 根據 key 計算出它的雜湊值 h。
- 假設箱子的個數為 n,那麼這個鍵值對應該放在第 (h % n) 個箱子中。
- 如果該箱子中已經有了鍵值對,就使用開放定址法或者拉鍊法解決衝突。
在使用拉鍊法解決雜湊衝突時,每個箱子其實是一個連結串列,屬於同一個箱子的所有鍵值對都會排列在連結串列中。
雜湊表還有一個重要的屬性: 負載因子(load factor),它用來衡量雜湊表的 空/滿 程度,一定程度上也可以體現查詢的效率,計算公式為:
負載因子 = 總鍵值對數 / 箱子個數
負載因子越大,意味著雜湊表越滿,越容易導致衝突,效能也就越低。因此,一般來說,當負載因子大於某個常數(可能是 1,或者 0.75 等)時,雜湊表將自動擴容。
雜湊表在自動擴容時,一般會建立兩倍於原來個數的箱子,因此即使 key 的雜湊值不變,對箱子個數取餘的結果也會發生改變,因此所有鍵值對的存放位置都有可能發生改變,這個過程也稱為重雜湊(rehash)。
雜湊表的擴容並不總是能夠有效解決負載因子過大的問題。假設所有 key 的雜湊值都一樣,那麼即使擴容以後他們的位置也不會變化。雖然負載因子會降低,但實際儲存在每個箱子中的連結串列長度並不發生改變,因此也就不能提高雜湊表的查詢效能。
基於以上總結,細心的讀者可能會發現雜湊表的兩個問題:
- 如果雜湊表中本來箱子就比較多,擴容時需要重新雜湊並移動資料,效能影響較大。
- 如果雜湊函式設計不合理,雜湊表在極端情況下會變成線性表,效能極低。
Java 8 中的雜湊表
JDK 的程式碼是開源的,可以從這裡下載到,我們要找的 HashMap.java 檔案的目錄在
openjdk/jdk/src/share/classes/java/util/HashMap.java。
HashMap 是基於 HashTable 的一種資料結構,在普通雜湊表的基礎上,它支援多執行緒操作以及空的 key 和 value。
在 HashMap 中定義了幾個常量:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;依次解釋以上常量:
DEFAULT_INITIAL_CAPACITY: 初始容量,也就是預設會建立 16 個箱子,箱子的個數不能太多或太少。如果太少,很容易觸發擴容,如果太多,遍歷雜湊表會比較慢。MAXIMUM_CAPACITY: 雜湊表最大容量,一般情況下只要記憶體夠用,雜湊表不會出現問題。DEFAULT_LOAD_FACTOR: 預設的負載因子。因此初始情況下,當鍵值對的數量大於16 * 0.75 = 12時,就會觸發擴容。TREEIFY_THRESHOLD: 上文說過,如果雜湊函式不合理,即使擴容也無法減少箱子中連結串列的長度,因此 Java 的處理方案是當連結串列太長時,轉換成紅黑樹。這個值表示當某個箱子中,連結串列長度大於 8 時,有可能會轉化成樹。UNTREEIFY_THRESHOLD: 在雜湊表擴容時,如果發現連結串列長度小於 6,則會由樹重新退化為連結串列。MIN_TREEIFY_CAPACITY: 在轉變成樹之前,還會有一次判斷,只有鍵值對數量大於 64 才會發生轉換。這是為了避免在雜湊表建立初期,多個鍵值對恰好被放入了同一個連結串列中而導致不必要的轉化。
學過概率論的讀者也許知道,理想狀態下雜湊表的每個箱子中,元素的數量遵守泊松分佈:
當負載因子為 0.75 時,上述公式中 λ 約等於 0.5,因此箱子中元素個數和概率的關係如下:
| 數量 | 概率 |
|---|---|
| 0 | 0.60653066 |
| 1 | 0.30326533 |
| 2 | 0.07581633 |
| 3 | 0.01263606 |
| 4 | 0.00157952 |
| 5 | 0.00015795 |
| 6 | 0.00001316 |
| 7 | 0.00000094 |
| 8 | 0.00000006 |
這就是為什麼箱子中連結串列長度超過 8 以後要變成紅黑樹,因為在正常情況下出現這種現象的機率小到忽略不計。一旦出現,幾乎可以認為是雜湊函式設計有問題導致的。
Java 對雜湊表的設計一定程度上避免了不恰當的雜湊函式導致的效能問題,每一個箱子中的連結串列可以與紅黑樹切換。
一、HashMap概述
在JDK1.8之前,HashMap採用陣列+連結串列實現,即使用連結串列處理衝突,同一hash值的連結串列都儲存在一個連結串列裡。但是當位於一個桶中的元素較多,即hash值相等的元素較多時,通過key值依次查詢的效率較低。而JDK1.8中,HashMap採用陣列+連結串列+紅黑樹實現,當連結串列長度超過閾值(8)時,將連結串列轉換為紅黑樹,這樣大大減少了查詢時間。
下圖中代表jdk1.8之前的hashmap結構,左邊部分即代表雜湊表,也稱為雜湊陣列,陣列的每個元素都是一個單鏈表的頭節點,連結串列是用來解決衝突的,如果不同的key對映到了陣列的同一位置處,就將其放入單鏈表中。(此圖借用網上的圖)
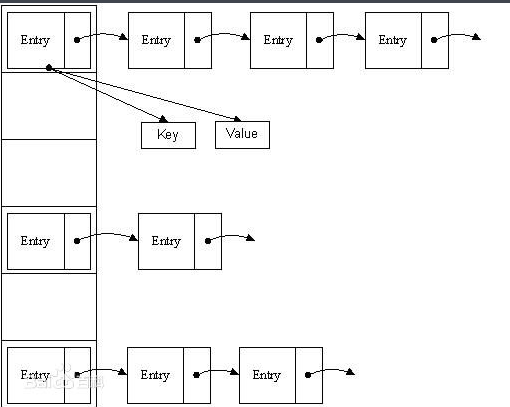
圖一、jdk1.8之前hashmap結構圖
jdk1.8之前的hashmap都採用上圖的結構,都是基於一個數組和多個單鏈表,hash值衝突的時候,就將對應節點以連結串列的形式儲存。如果在一個連結串列中查詢其中一個節點時,將會花費O(n)的查詢時間,會有很大的效能損失。到了jdk1.8,當同一個hash值的節點數不小於8時,不再採用單鏈表形式儲存,而是採用紅黑樹,如下圖所示(此圖是借用的圖)
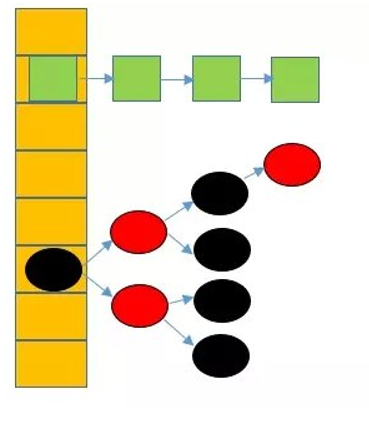
圖二、jdk1.8 hashmap結構圖
二、重要的field
- //table就是儲存Node類的陣列,就是對應上圖中左邊那一欄,
- /**
- * The table, initialized on first use, and resized as
- * necessary. When allocated, length is always a power of two.
- * (We also tolerate length zero in some operations to allow
- * bootstrapping mechanics that are currently not needed.)
- */
- transient Node<K,V>[] table;
- /**
- * The number of key-value mappings contained in this map.
- * 記錄hashmap中儲存鍵-值對的數量
- */
- transientint size;
- /**
- * hashmap結構被改變的次數,fail-fast機制
- */
- transientint modCount;
- /**
- * The next size value at which to resize (capacity * load factor).
- * 擴容的門限值,當size大於這個值時,table陣列進行擴容
- */
- int threshold;
- /**
- * The load factor for the hash table.
- *
- */
- float loadFactor;
- /**
- * The default initial capacity - MUST be a power of two.
- * 預設初始化陣列大小為16
- */
- staticfinalint DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- /**
- * The maximum capacity, used if a higher value is implicitly specified
- * by either of the constructors with arguments.
- * MUST be a power of two <= 1<<30.
- */
- staticfinalint MAXIMUM_CAPACITY = 1 << 30;
- /**
- * The load factor used when none specified in constructor.
- * 預設裝載因子,
- */
- staticfinalfloat DEFAULT_LOAD_FACTOR = 0.75f;
- /**
- * The bin count threshold for using a tree rather than list for a
- * bin. Bins are converted to trees when adding an element to a
- * bin with at least this many nodes. The value must be greater
- * than 2 and should be at least 8 to mesh with assumptions in
- * tree removal about conversion back to plain bins upon
- * shrinkage.
- * 這是連結串列的最大長度,當大於這個長度時,連結串列轉化為紅黑樹
- */
- staticfinalint TREEIFY_THRESHOLD = 8;
- /**
- * The bin count threshold for untreeifying a (split) bin during a
- * resize operation. Should be less than TREEIFY_THRESHOLD, and at
- * most 6 to mesh with shrinkage detection under removal.
- */
- staticfinalint UNTREEIFY_THRESHOLD = 6;
- /**
- * The smallest table capacity for which bins may be treeified.
- * (Otherwise the table is resized if too many nodes in a bin.)
- * Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
- * between resizing and treeification thresholds.
- */
- staticfinalint MIN_TREEIFY_CAPACITY = 64;
三、建構函式
- //可以自己指定初始容量和裝載因子
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- thrownew IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
-
if
相關推薦
JDK1.8HashMap原始碼的簡單剖析(1)
HashMap原始碼的剖析 最近大家都在找實習,而對於Java方向的同學,面試最常問的也是Java集合中的Map,Map有那幾種,每種的簡單實現都是什麼,每種的使用場景都是什麼。 昨天去面試,結果被問到,面試官一般問的都是HashMap的原理,是怎麼實現的,然後裡面重
java HashSet原始碼簡單剖析
1. 首先明確hash演算法: 既然都是HashSet集合了,肯定與hash演算法有關,我的理解就像是在查詢新華字典(雜湊表)一樣,按照拼音(雜湊值)先找到在哪頁(哪個儲存區域),再在該頁(區域)查詢。比全部遍歷提高了查詢效率。 2. HashSet集合是如何保證唯一性的? 通過
JDK1.8HashMap原始碼分析
關鍵變數解析 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 /** * 最大容量 2^30 */ static final int MAXIMUM_C
live555 原始碼簡單分析1:主程式
live555是使用十分廣泛的開源流媒體伺服器,之前也看過其他人寫的live555的學習筆記,在這裡自己簡單總結下。 live555原始碼有以下幾個明顯的特點: 1.標頭檔案是.hh字尾的,但沒覺得和.h字尾的有什麼不同 2.採用了面向物件的程式設計思路,裡面各種物件 好
jdk1.8原始碼解析(1):HashMap原始碼解析
jdk1.8 HashMap資料結構 圖1-HashMap類圖 圖2-TreeNode類圖 由圖1-HashMap類圖可知HashMap底層資料結構是由一個Node<K,V>的陣列構成。具體Node<
Caffe框架原始碼剖析(1)—構建網路
今天花了一整天時間進行閱讀和除錯Caffe框架程式碼,單單是以Lenet網路進行測試就可見框架的大致工作原理。賈揚清在Caffe中大量使用了STL、模板、智慧指標,有些地方為了效率也犧牲了一些程式碼可讀性,處處彰顯了大牛風範。為了他人閱讀方便,現將程式碼流程簡單梳理一下。 1.LeNe
(二十三)原型模式詳解(clone方法原始碼的簡單剖析)
作者:zuoxiaolong8810(左瀟龍),轉載請註明出處,特別說明:本博文來自博主原部落格,為保證新部落格中博文的完整性,特複製到此留存,如需轉載請註明新部落格地址即可。 &nbs
openTSDB原始碼詳解之Deferred類程式碼簡單示例1
openTSDB原始碼詳解之Deferred類程式碼簡單示例1 1.示例1 1.1 程式碼 /** * simplest with only 1 defer * 最簡單的,僅僅只有1個defer */ public static void test
Spring原始碼深度解析-1、Spring核心類簡單介紹
在更新JAVA基礎原始碼學習的同時,也有必要把Spring抓一抓,以前對於spring的程度僅在於使用,以及一點IOC/AOP的概念,具體深層的瞭解不是很深入,每次看了一點原始碼就看不下去,然後一轉眼都忘記看了啥。 所以這次專門買了書,來細細品味下Spring。 希望能從這一波學習中加強自己
thrift 原始碼剖析1 :TProcessor
TProcessor 這層主要負責應用層也就是需要我們平常自己實現的一層,它裡面封裝了Handler類。一般thrift 生成的程式碼中我們只需要負責寫Handler類的邏輯即可,Handler中的邏輯就是我們自己定義的服務邏輯。 分析 demo Servi
雲風的 BLOG: Lua GC 的原始碼剖析 (1)
/* ** Union of all Lua values */ typedef union { GCObject *gc; void *p; lua_Number n; int b; } Value; /* ** Tagge
caffe原始碼簡單解析——Blob(1)
使用caffe也有一段時間了,但更多是使用Python的介面,使用現有的ImageNet訓練好的模型進行圖片分類。為了更好的瞭解caffe這個框架,也為了提高自己的水平,在對卷積神經網路有了一些研究之後,終於開始研讀caffe的原始碼了,今天看了Blob類的一些內容,做個總
Spark核心原始碼深度剖析(1) - Spark整體流程 和寬依賴和窄依賴
1 Spark 整體流程 2 寬依賴和窄依賴 2.1 窄依賴 Narrow Dependency,一個RDD對它的父RDD,只有簡單的一對一的依賴關係。即RDD的每個 partition僅僅依賴於父RDD中的一個 partition。父RDD和子RDD的
Redis: Jedis 原始碼剖析1-連結建立和收發命令
Jedis作為Redis Java語言推薦的客戶端被廣泛使用。讓我們一探Jedis原始碼究竟。 我們以如下程式碼來DEBUG觀察Jedis原始碼: //建立Redis客戶端 Jedis jedis = new Jedis(); //呼叫set 命令,返
Python原始碼剖析[1] —— 編譯Python
在中間的部分,可以看到Python的核心,直譯器(interpreter)。在直譯器中,箭頭的方向指示了Python執行時的資料流方向。其中Scanner對應詞法分析,將檔案輸入的Python原始碼或從命令列輸入的一行行Python程式碼切分為一個一個的token;Parser對應語法分析部分,在Scanne
mmdetection原始碼剖析(1)--NMS
# mmdetection原始碼剖析(1)--NMS 熟悉目標檢測的應該都清楚**NMS**是什麼演算法,但是如果我們要與C++和cuda結合直接寫成Pytorch的操作你們清楚怎麼寫嗎?最近在看**mmdetection**的原始碼,發現其實原來寫C++和cuda的擴充套件也不難,下面給大家講一下。 C
Nginx技術深度剖析(1)
web服務器 nginx 深度剖析(1)Nginx核心模塊:Nginx核心模塊負責Nginx的全局應用,主要對應用主配置文件的Main區塊和Events區塊區域,這裏有很多Nginx必須的全局參數配置。(2)標準的HTTP功能模塊集合:這些模塊雖然不是必須的,但是是都很常用啊。因此會被Nginx自動編譯安裝到
HTML表格的簡單使用1
tle div oct class 失效 合並單元格 改變顏色 char 數據 1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="UT
ASP.NET Core 運行原理剖析1:初始化WebApp模版並運行
正式版 功能 option urn server ack reference 修改 tin ASP.NET Core 運行原理剖析1:初始化WebApp模版並運行 核心框架 ASP.NET Core APP 創建與運行 總結 之前兩篇文章簡析.NET Core
Hbase簡單學習---1
技術 gpo info class mage put div com 學習 1.求和2.put一行數據或一列數據3.刪除某一列的數據4.全表掃描5.get某一行或某一列的數據6.相當於組合的命令,對表進行初始化刪除一個然後又創建一個表 Hbase簡單學習---1