
jieba 分詞原始碼研讀(3)
前面兩篇文章說到了根據語料庫和頻度打分機制生成一個初步的分詞結果。但是我們的分詞結果僅僅用到了語料庫已有的詞語和頻度,所以對於語料庫中沒有出現的詞語判斷能力等於0,比如下面這句:
'喬治馬丁寫冰與火之歌拖了好久'
其分詞結果如下:
{0: (-99.10570994217552, 1), 1: (-95.82849854029436, 1), 2: (-86.8396051928814, 3), 3: (-84.72890670707343, 3), 4: (-75.00798674103962, 4), 5: (-66.83881448624362, 5), 6: (-56.61112681956269, 6), 7: (-50.688635432771534, 7), 8: (-41.82702063631733, 8), 9: (-35.77167914769012, 9), 10: (-25.879411293669556, 10), 11: (-16.115147905438818, 11), 12: (-11.89539448723901, 13), 13: (-8.9697445285742, 13), 14: (0.0, '')}
'喬治/馬丁/寫/冰/與/火/之/歌/拖/了/好久'
其中 “冰與火之歌" 沒有在語料庫裡出現過,所以沒有被識別出來的(注意沒有在語料庫裡出現過的詞通常稱作未登入詞,而初步的分詞會把未登入詞一個字一個字的”切割“開)。那麼應該怎麼樣改進呢?
回到 __cut_DAG 函式,這個函式前半部分用 calc 函式計算出了初步的分詞,而後半部分就是就是針對上面例子中未出現在語料庫的詞語進行分詞了。後半部分程式碼如下:
由於基於頻度打分的分詞會傾向於把不能識別的片語一個字一個字地切割開,所以對這些字的歸併就是識別未知詞語並且優化分詞結果的一個方向。在程式碼中,定義了一個buf 變數收集了這些連續的單個字,把它們組合成字串再交由 finalseg.cut 函式來進行下一步分詞。x = 0 buf =u'' N = len(sentence) while x<N: y = route[x][1]+1 l_word = sentence[x:y] if y-x==1: buf+= l_word else: if len(buf)>0: if len(buf)==1: yield buf buf=u'' else: if (buf not in FREQ): regognized = finalseg.cut(buf) for t in regognized: yield t else: for elem in buf: yield elem buf=u'' yield l_word x =y
該函式封裝在finalseg模組中,主要通過 __cut 函式來進行進一步的分詞。程式碼如下:
def __cut(sentence): global emit_P prob, pos_list = viterbi(sentence,('B','M','E','S'), start_P, trans_P, emit_P) begin, next = 0,0 #print pos_list, sentence for i,char in enumerate(sentence): pos = pos_list[i] if pos=='B': begin = i elif pos=='E': yield sentence[begin:i+1] next = i+1 elif pos=='S': yield char next = i+1 if next<len(sentence): yield sentence[next:]
要理解這段程式碼,必須先掌握一些相關的數學知識,因為這裡使用了隱含馬爾科夫模型(HMM)和維特比演算法(Viterbi)。
在HMM中有兩種狀態,一種是具有決定性的隱含著的狀態(簡稱狀態),另一種的顯性輸出的狀態(簡稱輸出)。在結巴分詞中狀態有4種,分別是B,M,E,S,對應於一個漢字在詞語中的地位即B(開頭),M(中間 ),E(結尾),S(獨立成詞),而輸出就是一個漢字。
在HMM中還有三種狀態分別是狀態分佈概率,狀態轉移概率和發射概率(發射概率是一個條件概率,表示在某一狀態下得到某一輸出的概率)。
現在我們的情況是已經得到了 sentence,即一串輸出,而想要知道的是這串漢字最有可能的BMES組合形式,從而進行分詞。這就需要使用到維特比演算法了。
在結巴分詞中作者經過大量的實驗在prob_start.py,prob_trans.py,prob_emit.py 中預存好了漢語的一些概率值。prob_start.py 中預存了每種狀態的概率,程式碼如下:
P={'B': -0.26268660809250016,
'E': -3.14e+100,
'M': -3.14e+100,
'S': -1.4652633398537678}prob_trans.py中預存了狀態將的轉移概率,程式碼如下:
P={'B': {'E': -0.510825623765990, 'M': -0.916290731874155},
'E': {'B': -0.5897149736854513, 'S': -0.8085250474669937},
'M': {'E': -0.33344856811948514, 'M': -1.2603623820268226},
'S': {'B': -0.7211965654669841, 'S': -0.6658631448798212}}對於一個sentence,第一個漢字的狀態概率稱為初始概率,可以用貝葉斯公式得到:
P(i)*P(k/i)=P(k)*P(i/k)
其中P(i)表示狀態的概率,在檔案prob_start.py 中可以找到,P(k/i)即發射概率(儲存在prob_emit.py),而P(k)即某個漢字出現的概率,忽略不計。則有:
P(i/k)=P(i)*P(k/i)
根據這個公式就有了sentence第一個字的狀態的概率值。那麼第二個字的狀態概率就是:
P(i2) = P(i1)*P(i2 | i1)*P(i2 | k2)*P(k2)÷P(i2) = P(i1)*P(i2 | i1)*P(k2 | i2)
其中P(i1)表示第一個字的狀態概率,P(i2)表示第二個字的狀態概率,P(i2 | i1)表示狀態i1到i2的轉移概率,P(k2 | i2)表示發射概率。
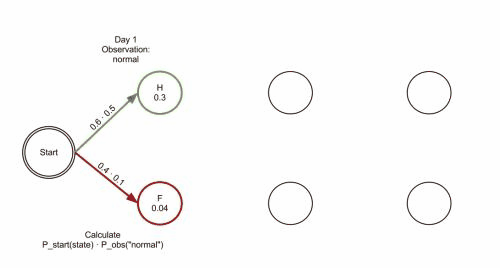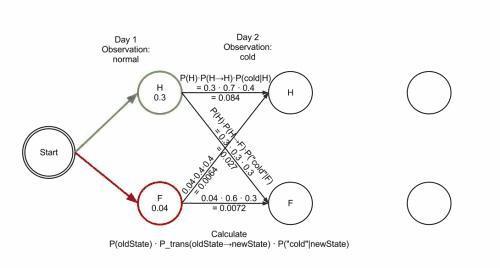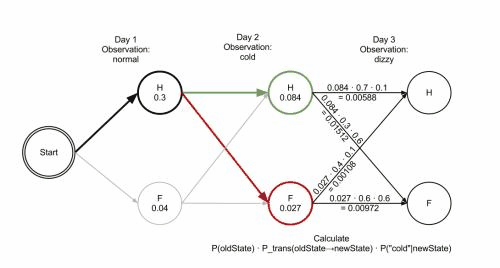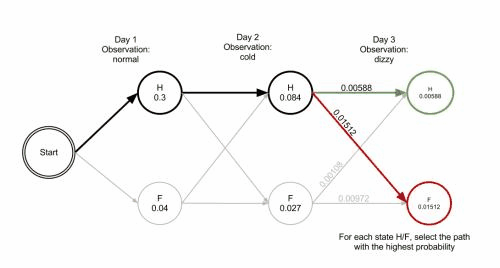
以此類推,由於每一個狀態都有4種選擇(BMES),所以根據每種選擇導致的狀態轉移路徑計算得出的概率值也不同,維特比演算法的目的就在於找出概率最大的一種轉移路徑。比如sentence的長度為2(兩個漢字),那麼演算法的目的就是使上面的P(i2) 最大化。那麼維特比演算法的特點是什麼呢?其實到達某一種中間狀態的路徑有很多條,比如在第三個節點到達狀態M,可能路徑有 S->B->M,也可以是B->M->M,維特比演算法會在中間這一步中就進行”剪枝“,它只記住路徑中概率較大的那一條路徑,而概率較小的忽略不計,所以只用記住到達這個節點的一條路徑就行了。
維基百科裡有一張 gif圖 很好地說明了這種剪枝手段:
結巴分詞中維特比演算法:
#狀態轉移矩陣,比如B狀態前只可能是E或S狀態
PrevStatus = {
'B':('E','S'),
'M':('M','B'),
'S':('S','E'),
'E':('B','M')
}
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}] #狀態概率矩陣
path = {}
for y in states:
V[0][y] = start_p[y] + emit_p[y].get(obs[0],MIN_FLOAT)#計算初始狀態概率,由於概率值做了對數化,所以乘號變成了加號
path[y] = [y]
for t in range(1,len(obs)):
V.append({})
newpath = {}
for y in states:
em_p = emit_p[y].get(obs[t],MIN_FLOAT)
(prob,state ) = max([(V[t-1][y0] + trans_p[y0].get(y,MIN_FLOAT) + em_p ,y0) for y0 in PrevStatus[y] ])
V[t][y] =prob
newpath[y] = path[state] + [y]#剪枝,只儲存概率最大的一種路徑
path = newpath
(prob, state) = max([(V[len(obs) - 1][y], y) for y in ('E','S')])#求出最後一個字哪一種狀態的對應概率最大,最後一個字只可能是兩種情況:E(結尾)和S(獨立詞)
return (prob, path[state])在得到了 BMES 劃分後,__cut再進行分詞,至此結巴分詞的所有奧祕就展現無遺了。
參考連線: