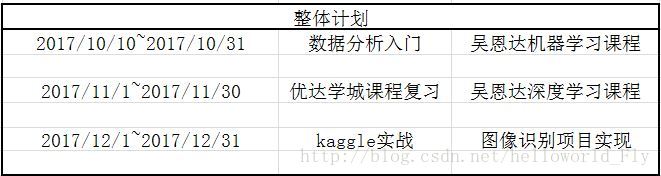
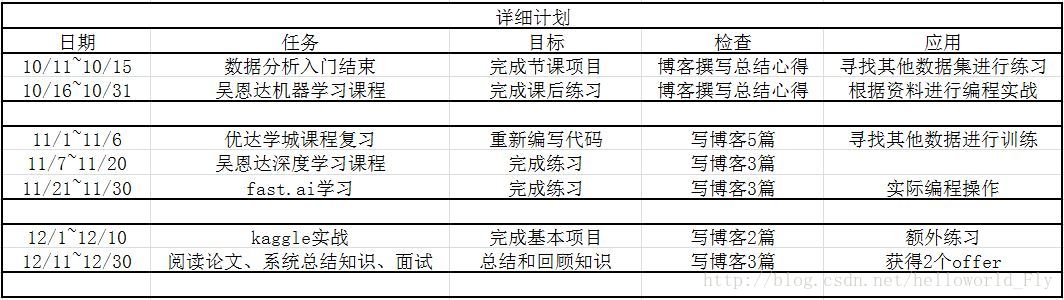
Udacity 資料分析入門總結
目錄
學習內容
*Python資料分析
1.資料讀取
2.資料修正(數值和日期格式的轉化)
3.資料探索(熟悉資料內容,提出問題)
4.問題處理(異常值、特殊值和特定資料提取)
5.資料視覺化(關鍵資料視覺化圖表呈現)*Numpy和Pandas處理一維資料
待學習*Numpy和Pandas處理二維資料
待學習
學習感受
課程篇
Udacity的課程總是一如既往的詳細,均是從基礎開始講起,最重要的是講解知識時提出許多具有啟發性的問題,加上合理的練習設計,學起來總是事半功倍。
內容篇
第一部分內容比較基礎,重點在於對列表、字典和元組的理解和使用。主要通過合理的建立字典和列表,將我們感興趣的資料放入,而將不感興趣和異常值去除。
而這個操作一般都是:建立字典——for迴圈——if條件選擇——輸出目標值到新字典。
內容的重點在於:熟悉資料內容,提出能從資料中獲得的有趣問題,以何種思路去回答問題,以及如何根據問題獲得有價值的資訊。
總結回顧
按照學習內容依次總結:
1.讀取csv檔案:
# 用到特殊庫檔案unicodecsv
import unicodecsv
def read_csv(file):
with open(file, 'rb' 讀取csv格式檔案,並返回列表。
2.資料修正
from datetime import datetime as dt
# 將字串格式的時間轉為 Python datetime 型別的時間。
# 如果沒有時間字串傳入,返回 None
def parse_date(date):
if date == '':
return None
else:
return dt.strptime(date, '%Y-%m-%d' 其中涉及到日期修改,用到datetime庫的strptime函式,在使用時格式為dt.strptime(date, “%Y-%m-%d”)。當然其輸出格式可以多種選擇,可以自行搜尋文件檢視格式。
資料型別轉換可以直接強制轉換為對應型別:int(i),其中有部分資料需要將尾數去掉,如課程完成值為1.5,需要轉化為1,可利用如下程式碼:
b = int(float(a))3.資料探索
提供資料為:
enrollments(第一個專案完成情況(內含學員賬號、加入時間、取消時間等))
daily-engagement(每天學習情況(內含學員賬號、瀏覽課程時間、完成課程總數和完成專案總數))
project-submissions(提交專案情況(內含提交專案日期、專案狀態等))
提問:
學員花費在課程上時間與學員提交專案關係?(求得資料中學員花費在課程上的總時間)
# 匯入 defaultdict ,可輸出空列表
from collections import defaultdict
# 定義在資料 data 中尋找特定項 value 的函式
def find_special_value(value, data):
engagement_by_account = defaultdict(list)
# 在資料中提取 “account_key”,並將對應資料傳遞給 “engagement_by_account”, 形成字典 “engagement_by_account”
for data_point in data:
account_key = data_point["account_key"]
engagement_by_account[account_key].append(data_point)
# 建立空字典,儲存結果
total_by_account = {}
# 字典 “engagement_by_account” 用兩次for迴圈查詢資料中對應 "value" 項,並將其累加,存入字典 “total_by_account”中,注意其中的 "items"
for account_key, engagement_by_student in engagement_by_account.items():
total = 0
for engagement_record in engagement_by_student:
total += engagement_record[value]
total_by_account[account_key] = total
# 提取字典中 “value” 值並存入元組 "total_value" 中
total_value = total_by_account.values()
學員完成課程數與學員完成專案數關係?
# 訪問次數道理與求累計學習時間相同,將value值改為 "num_courses_visited"即可學員訪問課程教室天數與專案完成關係?
def find_lessons_value(value, data):
engagement_by_account = defaultdict(list)
for engagement_record in data:
account_key = engagement_record["account_key"]
engagement_by_account[account_key].append(engagement_record)
total_by_account = {}
for account_key, engagement_by_student in engagement_by_account.items():
total = 0
for engagement_record in engagement_by_student:
# 特別之處在於,訪問天數的計算:只能是每天為1或者0,即如果當天有訪問次數記錄,只記為1次;沒有記錄,記為0次!
if engagement_record[value]:
total += 1
total_by_account[account_key] = total
total_value = total_by_account.values()4.問題處理
異常值、特殊值和特定資料提取
資料集daily-engagement中鍵值問題“acct”:
# 將 "acct" 對應內容 Value 賦值給 "account_key" , 刪除 "acct"
def engagement in daily-engagement:
engagement["account_key"] = engagement["acct"]
del engagement["acct"]資料集中出現重複註冊問題:
# 通過 “account_key” 的唯一賬號,剔除重複使用者
def get_unique_student(data):
unique_student = set()
for data_point in data:
unique_student.add(data_point["account_key"])
return unique_student官方測試賬號異常問題:
# 為所有 Udacity 測試帳號建立一組 set
udacity_test_accounts = set()
for enrollment in enrollments:
if enrollment['is_udacity']:
udacity_test_accounts.add(enrollment['account_key'])
# 通過 "account_key" 找到不是官方測試賬號的資料存入 non_udacity_account 中
def remove_udacity_accounts(data):
non_udacity_data = []
for data_point in data:
if data_point["account_key"] not in udacity_accounts:
non_udacity_data.append(data_point)
return non_udacity_data5.資料視覺化
得到對應結果後,可通過強大、神奇的numpy來處理,比如:
import numpy
total_value = total_by_account.values()
print "mean:", np.mean(total_value)
print "standard Deviation", np.std(total_value)
print "Minium", np.min(total_value)
print "Maxium", np.max(total_value)最後再將結果視覺化,比如最基本的直方圖:
# 關鍵資料視覺化圖表呈現
def describe_data(data):
print 'Mean:', np.mean(data)
print 'Standard deviation:', np.std(data)
print 'Minimum:', np.min(data)
print 'Maximum:', np.max(data)
plt.hist(data)可以非常直觀的看到提出資料分佈!!!
學習原因及計劃
原因
資料分析與處理是進行深度學習必不可少的一門學科,在對大型、複雜資料進行處理時,不僅僅需要熟練的程式設計技巧,更需要紮實的理論和豐富的經驗來分析和理解資料的特性,並根據其特性來進行合適的模型選擇。學習完Udacity的深度學習納米課程已經兩個多月了,但在實戰專案中,發現對資料的預處理不足,會導致模型的訓練效果大打折扣,且Python的基礎不紮實,需要一段時間的磨練,決定花一週的時間學習資料分析入門和用 MongoDB 進行資料整理課程,打基礎同時鍛鍊程式設計能力,更深入的理解程式設計思想。
計劃
寫在最後的最後,希望我能堅持到底,享受這個過程,成為更好的自己,得到nice的結果!