
大話機器學習(二)--KNN
一、有監督與無監督學習
總體來說講呢,機器學習又兩種學習方法,一個叫有監督學習(Supervised),一種叫無監督學習(Unsupervised)。顧名思義啊,一個就是有人看著,一個就是沒有。在機器學習中呢,就是有監督學習,會先告訴學習演算法,我有200本書,這些是我喜歡的,那些是我覺得一般的,那些是我討厭的。好,現在又給你一本書,請你告訴我,我對這本書的態度。
這樣的學習過程就是有監督的。
無監督的就是直接給你200本書,告訴你,給我分成幾類吧。分好後,你在給他一本書,問他,這本書和哪些是同一類?
大致就是這樣的意思。
二、KNN
今天,我們就來看一個很簡單的監督學習演算法,KNN(k-Nearest Neighbor)。基本步驟就是這樣:
1.把書分成n類,告訴演算法每一本書分別屬於哪一類
2.給演算法一本新書
3.演算法計算這本書和之前200本書的距離
4.取k個與這本書距離最近的已知類別的書。k本書中,哪種類別的書最多,那麼演算法就認為這本新書屬於哪種類別。換句話說,這些已知類別的書在投票。
可見,這本書與200本書的距離計算是一個很重要的點。投票的方法也是很重要的點。上訴只是講了最簡單的投票方法而已,可以按照不同的方法計算權重。KNN更加纖細的一些概要可以看我轉載的這一文章: http://blog.csdn.net/qtlyx/article/details/50618659
三、sklearn機器學習方法函式概要
咱們大概瞭解這一演算法之後呢,看一下sklearn的函式。 從剛才的講述中可以看出,演算法的輸入是樣本(samples),就是我們說的兩百本書;以及這些書對應的標籤(labels)。把這兩個告訴演算法之後,就是學習完成了。 sklearn裡面的機器學習方法函式有如下基本方法1.設定。
2.訓練
設定好引數,就是訓練,有監督的放樣本和標籤,無監督的,只有樣本。通常設定語句是這樣的:
設定完成可用的機器學習方法.fit(訓練樣本,[標籤])
3.預測。
訓練完之後就可以用這個東西來預測新的輸入的類別了。通常設定語句是這樣的:
設定完成可用的機器學習方法.predict(新樣本)
四、sklearn的KNN演算法示例

資料是這樣的:
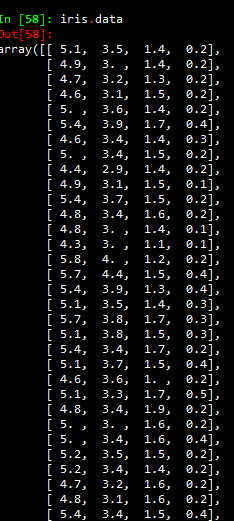
這是資料集的內容,共150條,這裡只截取了部分

這是對應的150個類別。
2.提取訓練資料集和測試資料集
i = 0
list = []
for i in range(0,150):
if i%3 != 0 :
list.append(i)samples= iris.data[list]
lab = iris.target[list]3.設定
n_neighbors = 15
clf = neighbors.KNeighborsClassifier(n_neighbors, weights='uniform')4.訓練
clf.fit(samples,lab)clf.predict(iris.data[3])
clf.predict(iris.data[6])
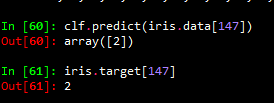
clf.predict(iris.data[147])
將這資料和iris.target對應下表比較發現時一樣的。
如:
五.完整程式碼
# -*- coding: utf-8 -*-
"""
Created on Mon Feb 01 16:27:13 2016
@author: Luyixiao
"""
# -*- coding: utf-8 -*-
import numpy as np
from sklearn import neighbors, datasets
n_neighbors = 15
iris = datasets.load_iris()
i = 0
list = []
for i in range(0,150):
if i%3 != 0 :
list.append(i)
samples= iris.data[list]
lab = iris.target[list]
n_neighbors = 15
clf = neighbors.KNeighborsClassifier(n_neighbors, weights='uniform')