
Kafka建立Topic時如何將分割槽放置到不同的Broker中
關注 iteblog_hadoop 公眾號並在評論區留言(認真寫評論,增加上榜的機會)。留言點贊數排名前5名的粉絲,各免費贈送一本《大資料之路:阿里巴巴大資料實踐》,明天18點就結束了,趕緊去參加吧。
如下面圖片不清晰,請訪問https://www.iteblog.com/archives/2219.html,或點選下面閱讀原文進行閱讀。
熟悉 Kafka的同學肯定知道,每個主題有多個分割槽,每個分割槽會存在多個副本,本文今天要討論的是這些副本是怎麼樣放置在 Kafka叢集的 Broker 中的。
大家可能在網上看過這方面的知識,網上對這方面的知識是千變一律,都是如下說明的:
為了更好的做負載均衡,Kafka儘量將所有的Partition均勻分配到整個叢集上。Kafka分配Replica的演算法如下:
-
將所有存活的N個Brokers和待分配的Partition排序
-
將第i個Partition分配到第(i mod n)個Broker上,這個Partition的第一個Replica存在於這個分配的Broker上,並且會作為partition的優先副本
-
將第i個Partition的第j個Replica分配到第((i + j) mod n)個Broker上
假設現在有5個 Broker,分割槽數為5,副本為3的主題,按照上面的說法,主題最終分配在整個叢集的樣子如下:
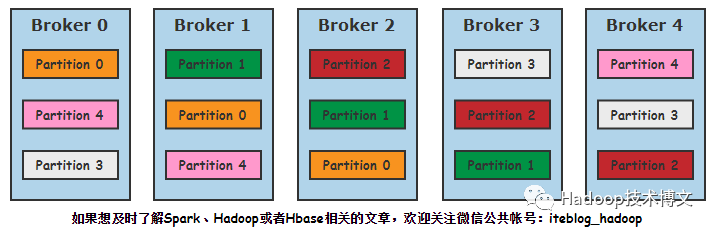
但事實真的是這樣的嗎?實際上如果真按照這種演算法,會存在以下明顯幾個問題:
-
所有主題的第一個分割槽都是存放在第一個Broker上,這樣會造成第一個Broker上的分割槽總數多於其他的Broker,這樣就失去了負載均衡的目的;
-
如果主題的分割槽數多於Broker的個數,多於的分割槽都是傾向於將分割槽發放置在前幾個Broker上,同樣導致負載不均衡。
所以其實上面的演算法不準確。嚴格來說,上面的演算法只是Kafka分配分割槽的一種特例(下面介紹演算法部分會說明)。下面我們來看看 Kafka 內部到底是如何將分割槽分配到各個 Broker 中的,其具體演算法實現函式就是 assignReplicasToBrokers,如下:

從上面的演算法可以看出:
-
副本因子不能大於 Broker 的個數;
-
第一個分割槽(編號為0)的第一個副本放置位置是隨機從 brokerList 選擇的;
-
其他分割槽的第一個副本放置位置相對於第0個分割槽依次往後移。也就是如果我們有5個 Broker,5個分割槽,假設第一個分割槽放在第四個 Broker 上,那麼第二個分割槽將會放在第五個 Broker 上;第三個分割槽將會放在第一個 Broker 上;第四個分割槽將會放在第二個 Broker 上,依次類推;
-
剩餘的副本相對於第一個副本放置位置其實是由 nextReplicaShift 決定的,而這個數也是隨機產生的;
所以如果我們依次如下呼叫上面的程式,ret 變數的輸出結果會如下:

注意,你執行上面的程式結果可能和我的不一樣,因為上面演算法中的 startIndex 和 nextReplicaShift 變數都是隨機生成的。其實 Kafka 建立主題就是這麼呼叫演算法的(fixedStartIndex
和 startPartitionId都是使用預設值)。另外,第一個放置的分割槽副本一般都是 Leader,其餘的都是 Follow 副本,也就是說,上面輸出的List第一個元素就是 Leader 副本所在的 Broker 編號。
到這裡我們應該知道,網上其他部落格介紹的 Kafka 分割槽是如何分配到各個 Broker 上其實是將 startIndex 設定成 0, 同時 fixedStartIndex 設定成 1,這樣本文最開頭介紹的演算法就對了。但其實 Kafka 內部並不是這樣呼叫的,大家注意。
如果我們還考慮機架的話,情況就更復雜了。這裡為了簡便起見,我們假設startIndex = 4,fixedStartIndex = 1。現在如果我們有兩個機架的 Kafka 叢集,brokers 0,
1 和 2 同屬於一個機架;brokers 3, 4 和 5 屬於另外一個機架。現在我們對這些 Broker 進行排序:0, 3, 1, 4, 2, 5(每個機架依次選擇一個Broker進行排序)。按照機架的 Kafka 分割槽放置演算法,如果分割槽0的第一個副本放置到broker 4上面,那麼其第二個副本將會放到broker 2上面,第三個副本將會放到 broker 5上面;同理,分割槽1的第一個副本放置到broker 2上面,其第二個副本將會放到broker 5上面,第三個副本將會放到 broker 0上面。這就保證了這兩個副本放置到不同的機架上面,即使其中一個機架出現了問題,我們的 Kafka 叢集還是可以正常執行的。現在把機架因素考慮進去的話,我們的分割槽看起來像下面一樣:
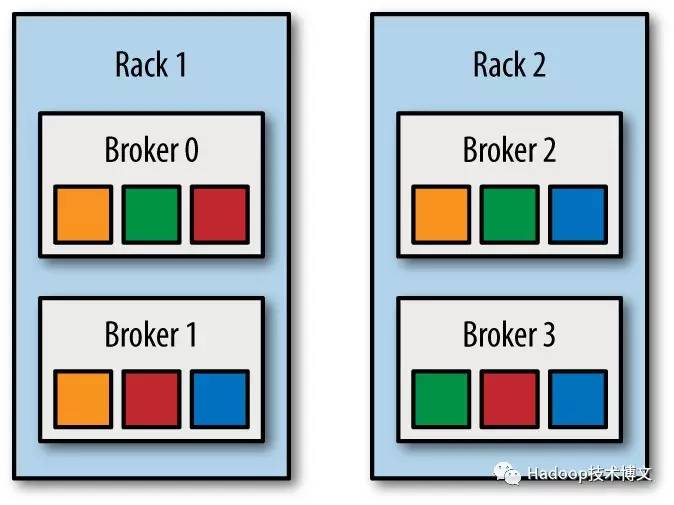
從上圖可以看出,只要上面其中一個機架沒有問題,我們的資料仍然可以對外提供服務。這就大大提高了叢集的可用性