
adaboost原理圖解
Adaboost演算法及分析
從圖1.1中,我們可以看到adaboost的一個詳細的演算法過程。Adaboost是一種比較有特點的演算法,可以總結如下:
1)每次迭代改變的是樣本的分佈,而不是重複取樣(re weight)
2)樣本分佈的改變取決於樣本是否被正確分類
總是分類正確的樣本權值低
總是分類錯誤的樣本權值高(通常是邊界附近的樣本)
3)最終的結果是弱分類器的加權組合
權值表示該弱分類器的效能
簡單來說,Adaboost有很多優點:
1)adaboost是一種有很高精度的分類器
2)可以使用各種方法構建子分類器,adaboost演算法提供的是框架
3)當使用簡單分類器時,計算出的結果是可以理解的。而且弱分類器構造極其簡單
4)簡單,不用做特徵篩選
5)不用擔心overfitting!
總之:adaboost是簡單,有效。
下面我們舉一個簡單的例子來看看adaboost的實現過程:

圖中,“+”和“-”分別表示兩種類別,在這個過程中,我們使用水平或者垂直的直線作為分類器,來進行分類。
第一步:

根據分類的正確率,得到一個新的樣本分佈D2,一個子分類器h1
其中劃圈的樣本表示被分錯的。在右邊的途中,比較大的“+”表示對該樣本做了加權。
第二步:

根據分類的正確率,得到一個新的樣本分佈D3,一個子分類器h2
第三步:
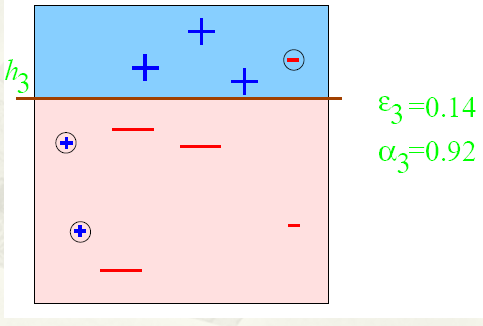
得到一個子分類器h3
整合所有子分類器:
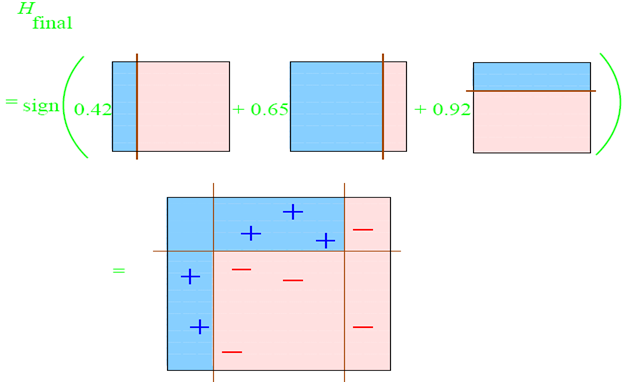
因此可以得到整合的結果,從結果中看,及時簡單的分類器,組合起來也能獲得很好的分類效果,在例子中所有的。
Adaboost演算法的某些特性是非常好的,在我們的報告中,主要介紹adaboost的兩個特性。一是訓練的錯誤率上界,隨著迭代次數的增加,會逐漸下降;二是adaboost演算法即使訓練次數很多,也不會出現過擬合的問題。