
Learning to Rank 中Listwise關於ListNet演算法講解及實現
前一篇文章"Learning to Rank中Pointwise關於PRank演算法原始碼實現"講述了基於點的學習排序PRank演算法的實現.該篇文章主要講述Listwise
Approach和基於神經網路的ListNet演算法及Java實現.包括:
1.基於列的學習排序(Listwise)介紹
2.ListNet演算法介紹
3.ListNet演算法Java實現
LTR中單文件方法是將訓練集裡每一個文件當做一個訓練例項,文件對方法是將同一個查詢的搜尋結果裡任意兩個文件對作為一個訓練例項,文件列方法是將一個查詢裡的所有搜尋結果列表作為一個訓練例項.
一. 基於列的學習排序(Listwise)介紹
Listwise方法將一個查詢對應的所有搜尋結果評分作為一個例項,訓練得到一個最優的評分函式.在給出如下資料集中:(資料集介紹詳見上一篇文章)
下面介紹一種基於搜尋結果排序組合的概率分佈情況來訓練.如下圖:
參考《這就是搜尋引擎:核心技術詳解 by:張俊林》第5章

使用者輸入查詢Q1,假設返回的搜尋結果集合裡包含A、B和C三個文件,搜尋引擎要對搜尋結果排序,而3個文件順序共有6種排列組合方式:ABC、ACB、BAC、BCA、CAB和CBA,每種排列組合都是一種可能的搜尋結果排序方法.
我們可以把函式g設想成最優評分函式(人工打分),對查詢Q1來說:文件A得6分,文件B得4分,文件C得3分;我們的任務是找到一個函式,使得其對Q1的搜尋結果打分順序儘可能的接近標準函式g.其中函式f和h就是實際的評分函式,通過比較兩個概率之間的KL距離,發現f比h更接近假想的最優函式g.故選擇函式f為搜尋的評分函式.
Listwise主要的演算法包括:AdaRank、SVM-MAP、ListNet、LambdaMART等.
二. ListNet演算法介紹
Pointwise學習排序是將訓練集中的每個文件看作一個樣本獲取Rank函式,主要解決辦法是把分類問題轉換為單個文件的分類和迴歸問題,如PRank.
Pairwise學習排序(下篇介紹)是將同一個查詢中不同的相關標註的兩個文件看作一個樣本,主要解決思想是把Rank問題轉換為二值分類問題,如RankNet.
Listwise學習排序是將整個文件序列看作一個樣本,主要是通過直接優化資訊檢索的評價方法和定義損失函式兩種方法實現.ListNet演算法將Luce模型引入到了排序學習方法中來表示文件序列,同時大多數基於神經網路的排序學習演算法都是基於Luce模型(Luce模型就是將序列的任意一種排序方式表示成一個概率值)來表示序列的排序方式的.
ListNet演算法參考:
《Learning to Rank: From Pairwise Approach to Listwise Approach》
《基於神經網路的Listwise排序學習方法的研究》 By:林原
通過該演算法步驟解釋如下:
1.首先輸入訓練集train.txt資料.{x,y}表示查詢號對應的樣本文件,包括標註等級Label=y(46維微軟資料集共3個等級:0-不相關,1-部分相關,2-全部相關),x表示對應的特徵和特徵值,需要注意的是x(m)表示m個qid數,每個x(m)中有多個樣本文件.
2.初始化操作.迭代次數T(設定為30次)和Learning rate(ita可以為0.003、0.001、0.03、0.01等),同時初始化權重w.
3.兩層迴圈操作.第一層是迴圈迭代次數:for t = 1 to T do;第二層迴圈是迭代查詢總數(qid總數):for i = 1 to m do.
4.計算該行分數用當前權重w.注意權重w[46]是一維陣列,分別對應46個特徵值,同時f(w) = w * x.

5.計算梯度向量delta_w(46個維度).其中計算公式如下:
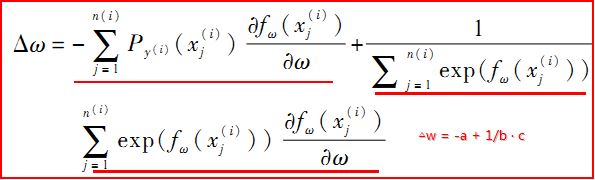
其中n(i)表示查詢號qid=i對應的總文件數,j表示qid=i的當前文件.x的右上方下標表示對應的qid數,右下方下標表示對應的文件標號.而P是計算概率的函式,如下:
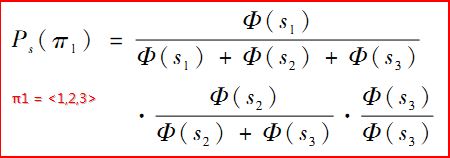
它表示S1排第一、S2排第二且S3排第三的概率值.這就是使用Luce模型使一個序列的排序方式表示成一個單一的概率值.實際過程中,我們通過使用exp()函式來表示fai.主要保證其值為正、遞增.
但N!的時間複雜度很顯然效率很低,所以提出了Top-K概率來解決,即用前k項的排列概率來近似原有的整個序列的概率,通過降低精準度來換取執行時間.
Top-K概率公式如下:
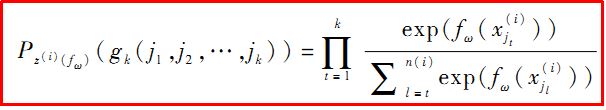
在下面的Java程式碼實現中我採用的是Top-1,即獲取當前行文件排第一的概率值.
6.迴圈更新權重w.
7.最後輸出w[46]權重,訓練過程結束.通過該模型可以進行測試預測排序,test.txt通過該權重進行w*x打分,再進行從高到低排序即可.
PS:這僅僅是我結合兩篇論文後的個人理解,如果有錯誤或不足之處,歡迎探討!同時感謝我的同學XP和MT,我們一起探討和分享才理解了一些ListNet演算法及程式碼.
三. ListNet演算法Java實現
(PS:該部分程式碼非常感謝我的組長XP和MT,他們在整個程式設計路上對我幫助是一生的.同時自己也希望以後工作中能找到更多的老師和摯友指導我前行~)
程式碼中有詳細的註釋,按照每個步驟完成.左圖是主函式,它主要包括:讀取檔案並解析資料、寫資料、學習排序模型和打分預測,右圖是學習排序的核心演算法.


程式碼如下:
[java] view plain copy print?
- package listNet_xiuzhang;
- import java.io.BufferedReader;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileWriter;
- import java.io.InputStreamReader;
- publicclass listNet {
- //檔案總行數(標記數)
- privatestaticint sumLabel;
- //特徵值 46個 (標號1-46)
- privatestaticdouble feature[][] = newdouble[100000][48];
- //特徵值權重 46個 (標號1-46)
- privatestaticdouble weight [] = newdouble[48];
- //相關度 其值有0-2三個級別 從1開始記錄
- privatestaticint label [] = newint[1000000];
- //查詢id 從1開始記錄
- privatestaticint qid [] = newint[1000000];
- //每個Qid的doc數量
- privatestaticint doc_ofQid[] = newint[100000];
- privatestaticint ITER_NUM=30; //迭代次數
- privatestaticint weidu=46; //特徵數
- privatestaticint qid_Num=0; //Qid數量
- privatestaticint tempQid=-1; //臨時Qid數
- privatestaticint tempDoc=0; //臨時doc數
- /**
- * 函式功能 讀取檔案
- * 引數 String filePath 檔案路徑
- */
- publicstaticvoid ReadTxtFile(String filePath) {
- try {
- String encoding="GBK";
- File file=new File(filePath);
- if(file.isFile() && file.exists()) { //判斷檔案是否存在
- InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding);
- BufferedReader bufferedReader = new BufferedReader(read);
- String lineTxt = null;
- sumLabel =1; //初始化從1記錄
- //按行讀取資料並分解資料
- while((lineTxt = bufferedReader.readLine()) != null) {
- String str = null;
- int lengthLine = lineTxt.length();
- //獲取資料 字串空格分隔
- String arrays[] = lineTxt.split(" ");
- for(int i=0; i<arrays.length; i++) {
- //獲取每行樣本的Label值
- if(i==0) {
- label[sumLabel] = Integer.parseInt(arrays[0]);
- }
- elseif(i>=weidu+2){ //讀取至#跳出 0-label 1-qid 2:47-特徵
- continue;
- }
- else {
- String subArrays[] = arrays[i].split(":"); //特徵:特徵值
- if(i==1) { //獲取qid
- //判斷是否是新的Qid
- if(tempQid != Integer.parseInt(subArrays[1])) {
- if(tempQid != -1){ //不是第一次出現新Qid
- //賦值上一個為qid_Num對應的tempDoc個文件
- doc_ofQid[qid_Num]=tempDoc;
- tempDoc=0;
- }
- //當tempQid不等於當前qid時下標加1
- //相等則直接跳至Doc加1直到不等
- qid_Num++;
- tempQid=Integer.parseInt(subArrays[1]);
- }
- tempDoc++; //新的文件
- qid[sumLabel] = Integer.parseInt(subArrays[1]);
- }
- else { //獲取46維特徵值
- int number = Integer.parseInt(subArrays[0]); //判斷特徵
- double value = Double.parseDouble(subArrays[1]);
- feature[sumLabel][number] = value; //number陣列標號:1-46
- }
- }
- }
- sumLabel++;
- }
- doc_ofQid[qid_Num]=tempDoc;
- read.close();
- } else {
- System.out.println("找不到指定的檔案\n");
- }
- } catch (Exception e) {
- System.out.println("讀取檔案內容出錯");
- e.printStackTrace();
- }
- }
- /**
- * 學習排序
- * 訓練模型得到46維權重
- */
- publicstaticvoid LearningToRank() {
- //變數
- double index [] = newdouble[1000000];
- double tao [] = newdouble[1000000];
- double yita=0.00003;
- //初始化
- for(int i=0;i<weidu+2;i++) { //從1到136為權重,0和137無用
- weight[i] = (double) 1.0; //權重初值
- }
- System.out.println("training...");
- //計算權重 學習演算法
- for(int iter = 0; iter<ITER_NUM; iter++) //迭代ITER_NUM次
- {
- System.out.println("---迭代次數:"+iter);
- int now_doc=0; //全域性文件索引
- for(int i=1; i<=qid_Num; i++) //總樣qid數 相當於兩層迴圈T和m
- {
- double delta_w[] = newdouble[weidu+2]; //46個梯度組成的向量
- int doc_of_i=doc_ofQid[i]; //該Qid的文件數
- //得分f(w),一個QID有多個文件,一個文件為一個分,所以一個i對應一個分數陣列
- double fw[] = newdouble[doc_of_i+2];
- /* 第一步 算得分陣列fw fin */
- for(int k=1;k<=doc_of_i;k++) { //初始化
- fw[k]=0.0;
- }
- for(int k=1;k<=doc_of_i;k++) { //每個文件的得分
- for(int p=1;p<=weidu;p++) {
- fw[k]=fw[k]+weight[p]*feature[now_doc+k][p]; //算出這個文件的分數
- }
- }
- /*
- * 第二步 算梯度delta_w向量
- * a=Σp*x,a是向量
- * b=Σexpf(x),b是數字
- * c=expf(x)*x,c是向量
- * 最終結果delta_w是向量
- */
- double[] a=newdouble[weidu+2],c=newdouble[weidu+2];
- for(int k=0;k<weidu+2;k++){a[k]=0.0;} //初始化
- for(int k=0;k<weidu+2;k++){c[k]=0.0;} //初始化
- double b=0.0;
- //算a:----
- for(int k=1; k<=doc_of_i; k++) {
- double p=1.0; //先不topK
- double[] temp=newdouble[48];
- for(int q=1;q<=weidu;q++) {
- //算P: ----第q個向量排XX的概率是多少
- //分母:
- double fenmu=0.0;
- for(int m=1;m<=doc_of_i;m++) {
- fenmu=fenmu+Math.exp(fw[m]); //所有文件得分
- }
- //top-1 exp(s1) / exp(s1)+exp(s2)+..+exp(sn)
- for(int m=1;m<=doc_of_i;m++) {
- p=p*(Math.exp(fw[m])/fenmu);
- }
- //算積
- temp[q]=temp[q]+p*feature[now_doc+k][q];
- }
- for(int q=1; q<=weidu; q++){
- a[q]=a[q]+temp[q];
- }
- } //End a
- //算b:---- fin.
- for(int k=1; k<=doc_of_i; k++){
- b=b+Math.exp(fw[k]);
- }
- //算c:----
- for(int k=1; k<=doc_of_i; k++){
- double[] temp=newdouble[weidu+2];
- for(int q=1; q<=weidu; q++){
- temp[q]=temp[q]+Math.exp(fw[k])*feature[now_doc+k][q];
- }
- for(int q=1; q<=weidu; q++){
- c[q]=c[q]+temp[q];
- }
- }
- //算梯度:delta_x=-a+1/b*c
- for(int q=1; q<=weidu; q++){
- delta_w[q]= (-1)*a[q] + ((1.0/b)*c[q]);
- }
- //**********
- /* 第三步 更新權重 fin. */
- for(int k=1; k<=weidu; k++){
- weight[k]=weight[k]-yita*delta_w[k];
- }
- now_doc=now_doc+doc_of_i; //更新當前文件索引
- }
- } //End 迭代次數
- //輸出權重
- for(int i=1;i<=weidu;i++) //從1到136為權重,0和137無用
- {
- System.out.println(i+"wei:"+weight[i]);
- }
- }
- /**
- * 輸出權重到檔案fileModel
- * @param fileModel
- */
- publicstaticvoid WriteFileModel(String fileModel) {
- //輸出權重到檔案
- try {
- System.out.println("write start.總行數:"+sumLabel);
- FileWriter fileWriter = new FileWriter(fileModel);
- //寫資料
- fileWriter.write("## ListNet");
- fileWriter.write("\r\n");
- fileWriter.write("## Epochs = "+ITER_NUM);
- fileWriter.write("\r\n");
- fileWriter.write("## No. of features = 46");
- fileWriter.write("\r\n");
- fileWriter.write("1 2 3 4 5 6 7 8 9 10 ... 39 40 41 42 43 44 45 46");
- fileWriter.write("\r\n");
- fileWriter.write("0");
- fileWriter.write("\r\n");
- for(int k=0; k<weidu; k++){
- fileWriter.write("0 "+k+" "+weight[k+1]);
- fileWriter.write("\r\n");
- }
- fileWriter.close();
- System.out.println("write fin.");
- } catch(Exception e) {
- System.out.println("寫檔案內容出錯");
- e.printStackTrace();
- }
- }
- /**
- * 預測排序
- * 正規應對test.txt檔案進行打分排序
- * 但我們是在Hadoop實現該打分排序步驟 此函式僅測試train.txt打分
- */
- publicstaticvoid PredictRank(String fileScore) {
- //輸出得分
- try {
- System.out.println("write start.總行數:"+sumLabel);
- String encoding = "GBK";
- FileWriter fileWriter = new FileWriter(fileScore);
- //寫資料
- for(int k=1; k<sumLabel; k++){
- double score=0.0;
- for(int j=1;j<=weidu;j++){
- score=score+weight[j]*feature[k][j];
- }
- fileWriter.write("qid:"+qid[k]+" score:"+score+" label:"+label[k]);
- fileWriter.write("\r\n");
- }
- fileWriter.close();
- System.out.println("write fin.");
- } catch(Exception e) {
- System.out.println("寫檔案內容出錯");
- e.printStackTrace();
- }
- }
- /**
- * 主函式
- */
- publicstaticvoid main(String args[]) {
- String fileInput = "Fold1\\train.txt"; //訓練
- String fileModel = "model_weight.txt"; //輸出權重模型
- String fileScore = "score_listNet.txt"; //輸出得分
- //第1步 讀取檔案並解析資料
- System.out.println("read...");
- ReadTxtFile(fileInput);
- System.out.println("read and write well.");
- //第2步 排序計算
- LearningToRank();
- //第3步 輸出模型
- WriteFileModel(fileModel);
- //第4步 打分預測排序
- PredictRank(fileScore);
- }
- /*
- * End
- */
- }
package listNet_xiuzhang;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.InputStreamReader;
public class listNet {
//檔案總行數(標記數)
private static int sumLabel;
//特徵值 46個 (標號1-46)
private static double feature[][] = new double[100000][48];
//特徵值權重 46個 (標號1-46)
private static double weight [] = new double[48];
//相關度 其值有0-2三個級別 從1開始記錄
private static int label [] = new int[1000000];
//查詢id 從1開始記錄
private static int qid [] = new int[1000000];
//每個Qid的doc數量
private static int doc_ofQid[] = new int[100000];
private static int ITER_NUM=30; //迭代次數
private static int weidu=46; //特徵數
private static int qid_Num=0; //Qid數量
private static int tempQid=-1; //臨時Qid數
private static int tempDoc=0; //臨時doc數
/**
* 函式功能 讀取檔案
* 引數 String filePath 檔案路徑
*/
public static void ReadTxtFile(String filePath) {
try {
String encoding="GBK";
File file=new File(filePath);
if(file.isFile() && file.exists()) { //判斷檔案是否存在
InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
sumLabel =1; //初始化從1記錄
//按行讀取資料並分解資料
while((lineTxt = bufferedReader.readLine()) != null) {
String str = null;
int lengthLine = lineTxt.length();
//獲取資料 字串空格分隔
String arrays[] = lineTxt.split(" ");
for(int i=0; i<arrays.length; i++) {
//獲取每行樣本的Label值
if(i==0) {
label[sumLabel] = Integer.parseInt(arrays[0]);
}
else if(i>=weidu+2){ //讀取至#跳出 0-label 1-qid 2:47-特徵
continue;
}
else {
String subArrays[] = arrays[i].split(":"); //特徵:特徵值
if(i==1) { //獲取qid
//判斷是否是新的Qid
if(tempQid != Integer.parseInt(subArrays[1])) {
if(tempQid != -1){ //不是第一次出現新Qid
//賦值上一個為qid_Num對應的tempDoc個文件
doc_ofQid[qid_Num]=tempDoc;
tempDoc=0;
}
//當tempQid不等於當前qid時下標加1
//相等則直接跳至Doc加1直到不等
qid_Num++;
tempQid=Integer.parseInt(subArrays[1]);
}
tempDoc++; //新的文件
qid[sumLabel] = Integer.parseInt(subArrays[1]);
}
else { //獲取46維特徵值
int number = Integer.parseInt(subArrays[0]); //判斷特徵
double value = Double.parseDouble(subArrays[1]);
feature[sumLabel][number] = value; //number陣列標號:1-46
}
}
}
sumLabel++;
}
doc_ofQid[qid_Num]=tempDoc;
read.close();
} else {
System.out.println("找不到指定的檔案\n");
}
} catch (Exception e) {
System.out.println("讀取檔案內容出錯");
e.printStackTrace();
}
}
/**
* 學習排序
* 訓練模型得到46維權重
*/
public static void LearningToRank() {
//變數
double index [] = new double[1000000];
double tao [] = new double[1000000];
double yita=0.00003;
//初始化
for(int i=0;i<weidu+2;i++) { //從1到136為權重,0和137無用
weight[i] = (double) 1.0; //權重初值
}
System.out.println("training...");
//計算權重 學習演算法
for(int iter = 0; iter<ITER_NUM; iter++) //迭代ITER_NUM次
{
System.out.println("---迭代次數:"+iter);
int now_doc=0; //全域性文件索引
for(int i=1; i<=qid_Num; i++) //總樣qid數 相當於兩層迴圈T和m
{
double delta_w[] = new double[weidu+2]; //46個梯度組成的向量
int doc_of_i=doc_ofQid[i]; //該Qid的文件數
//得分f(w),一個QID有多個文件,一個文件為一個分,所以一個i對應一個分數陣列
double fw[] = new double[doc_of_i+2];
/* 第一步 算得分陣列fw fin */
for(int k=1;k<=doc_of_i;k++) { //初始化
fw[k]=0.0;
}
for(int k=1;k<=doc_of_i;k++) { //每個文件的得分
for(int p=1;p<=weidu;p++) {
fw[k]=fw[k]+weight[p]*feature[now_doc+k][p]; //算出這個文件的分數
}
}
/*
* 第二步 算梯度delta_w向量
* a=Σp*x,a是向量
* b=Σexpf(x),b是數字
* c=expf(x)*x,c是向量
* 最終結果delta_w是向量
*/
double[] a=new double[weidu+2],c=new double[weidu+2];
for(int k=0;k<weidu+2;k++){a[k]=0.0;} //初始化
for(int k=0;k<weidu+2;k++){c[k]=0.0;} //初始化
double b=0.0;
//算a:----
for(int k=1; k<=doc_of_i; k++) {
double p=1.0; //先不topK
double[] temp=new double[48];
for(int q=1;q<=weidu;q++) {
//算P: ----第q個向量排XX的概率是多少
//分母:
double fenmu=0.0;
for(int m=1;m<=doc_of_i;m++) {
fenmu=fenmu+Math.exp(fw[m]); //所有文件得分
}
//top-1 exp(s1) / exp(s1)+exp(s2)+..+exp(sn)
for(int m=1;m<=doc_of_i;m++) {
p=p*(Math.exp(fw[m])/fenmu);
}
//算積
temp[q]=temp[q]+p*feature[now_doc+k][q];
}
for(int q=1; q<=weidu; q++){
a[q]=a[q]+temp[q];
}
} //End a
//算b:---- fin.
for(int k=1; k<=doc_of_i; k++){
b=b+Math.exp(fw[k]);
}
//算c:----
for(int k=1; k<=doc_of_i; k++){
double[] temp=new double[weidu+2];
for(int q=1; q<=weidu; q++){
temp[q]=temp[q]+Math.exp(fw[k])*feature[now_doc+k][q];
}
for(int q=1; q<=weidu; q++){
c[q]=c[q]+temp[q];
}
}
//算梯度:delta_x=-a+1/b*c
for(int q=1; q<=weidu; q++){
delta_w[q]= (-1)*a[q] + ((1.0/b)*c[q]);
}
//**********
/* 第三步 更新權重 fin. */
for(int k=1; k<=weidu; k++){
weight[k]=weight[k]-yita*delta_w[k];
}
now_doc=now_doc+doc_of_i; //更新當前文件索引
}
} //End 迭代次數
//輸出權重
for(int i=1;i<=weidu;i++) //從1到136為權重,0和137無用
{
System.out.println(i+"wei:"+weight[i]);
}
}
/**
* 輸出權重到檔案fileModel
* @param fileModel
*/
public static void WriteFileModel(String fileModel) {
//輸出權重到檔案
try {
System.out.println("write start.總行數:"+sumLabel);
FileWriter fileWriter = new FileWriter(fileModel);
//寫資料
fileWriter.write("## ListNet");
fileWriter.write("\r\n");
fileWriter.write("## Epochs = "+ITER_NUM);
fileWriter.write("\r\n");
fileWriter.write("## No. of features = 46");
fileWriter.write("\r\n");
fileWriter.write("1 2 3 4 5 6 7 8 9 10 ... 39 40 41 42 43 44 45 46");
fileWriter.write("\r\n");
fileWriter.write("0");
fileWriter.write("\r\n");
for(int k=0; k<weidu; k++){
fileWriter.write("0 "+k+" "+weight[k+1]);
fileWriter.write("\r\n");
}
fileWriter.close();
System.out.println("write fin.");
} catch(Exception e) {
System.out.println("寫檔案內容出錯");
e.printStackTrace();
}
}
/**
* 預測排序
* 正規應對test.txt檔案進行打分排序
* 但我們是在Hadoop實現該打分排序步驟 此函式僅測試train.txt打分
*/
public static void PredictRank(String fileScore) {
//輸出得分
try {
System.out.println("write start.總行數:"+sumLabel);
String encoding = "GBK";
FileWriter fileWriter = new FileWriter(fileScore);
//寫資料
for(int k=1; k<sumLabel; k++){
double score=0.0;
for(int j=1;j<=weidu;j++){
score=score+weight[j]*feature[k][j];
}
fileWriter.write("qid:"+qid[k]+" score:"+score+" label:"+label[k]);
fileWriter.write("\r\n");
}
fileWriter.close();
System.out.println("write fin.");
} catch(Exception e) {
System.out.println("寫檔案內容出錯");
e.printStackTrace();
}
}
/**
* 主函式
*/
public static void main(String args[]) {
String fileInput = "Fold1\\train.txt"; //訓練
String fileModel = "model_weight.txt"; //輸出權重模型
String fileScore = "score_listNet.txt"; //輸出得分
//第1步 讀取檔案並解析資料
System.out.println("read...");
ReadTxtFile(fileInput);
System.out.println("read and write well.");
//第2步 排序計算
LearningToRank();
//第3步 輸出模型
WriteFileModel(fileModel);
//第4步 打分預測排序
PredictRank(fileScore);
}
/*
* End
*/
}四. 總結
上面的程式碼我更希望你關注的是ListNet在訓練模型過程中的程式碼,也就是通過train.txt獲取得到46維的權重的模型.通過該模型你可以對test.txt進行打分(權重*特徵值)排序,而上面的程式碼僅是對train.txt進行了簡單的打分操作,那時因為我們的作業是基於Hadoop或Spark分散式處理基礎上的.所以該部分由其他同學完成.
同時你也可以通過開源的RankLib或羅磊同學的ListNet演算法進行學習,地址如下:
http://people.cs.umass.edu/~vdang/ranklib.html
最後我們使用開源的MAP和[email protected]簡單對該演算法進行了效能評估,同時附上Hadoop上的執行截圖(MapReduce只找到了PRank的一張截圖).


希望文章對大家有所幫助,同時我是根據論文寫出的Java程式碼,如果有錯誤或不足之處,還請海涵~同時歡迎提出問題,我對機器學習和演算法的瞭解還是初學,但是會盡力答覆.同時發現該部分的程式碼真的很少,所以才寫了這樣一些文章,後面還準備寫寫Pairwise和Map\NDCG評價.
(By:Eastmount 2015-2-5 夜10點 http://blog.csdn.net/eastmount/article/)
相關推薦
【學習排序】 Learning to Rank 中Listwise關於ListNet演算法講解及實現
程式碼如下:package listNet_xiuzhang; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileWriter; import
Learning to Rank 中Listwise關於ListNet演算法講解及實現
前一篇文章"Learning to Rank中Pointwise關於PRank演算法原始碼實現"講述了基於點的學習排序PRank演算法的實現.該篇文章主要講述Listwise Approach和基於神經網路的ListNet演算法及Java實現.包括: 1.基於列的學習排序(Listwise
【學習排序】 Learning to Rank中Pointwise關於PRank演算法原始碼實現
最近終於忙完了Learning to Rank的作業,同時也學到了很多東西.我準備寫幾篇相關的文章簡單講述自己對它的理解和認識.第一篇準備講述的就是Learning to Rank中Pointwise的認識及PRank演算法的實現.主要從以下四個方面進行講述: 1.學
Learning to rank (software, datasets)
rdl n) gbrt comm eve ftw eva ext ros Datasets for ranking (LETOR datasets) MSLR-WEB10k and MSLR-WEB30k You’ll need much patien
Learning to Rank
pager ros base span 方式 disco 機器 osi containe https://www.cnblogs.com/wentingtu/archive/2012/03/13/2393993.html Table of Contents 1 前言
Learning to Rank(轉)
搜索 class 差異 https mode 表示 排序 cef hot https://blog.csdn.net/kunlong0909/article/details/16805889 Table of Contents 1 前言 2 LTR流程 3 訓練數據
learning to rank學習筆記
learning to rank是這幾年火起來的一個學科,可以應用於檢索、推薦等排序場景中。我們的業務場景大都和排序相關,那麼掌握住learning to rank就又多了一條解決業務問題的方法。 常見的排序演算法: 1.文字相關性計算方法:BM25,TF_IDF,word2vec等。
Learning to Rank for Information Retrieval
Learning to Rank for Information Retrieval(LETOR) 是Microsoft的一個資訊檢索相關度排序的資料集,有 Supervised ranking Semi-supervised ranking Rank aggregation Lis
機器學習排序之Learning to Rank簡單介紹
PS:文章主要轉載自CSDN大神hguisu的文章"機器學習排序": http://blog.csdn.net/hguisu/article/details/7989489 最近需要完成課程作業——分散式排序學習系統.它是在
關於Android中通知欄的講解及適配Android 8.0
前言 通知欄是Android系統原創的一個功能,雖然喬布斯一直認為Android系統是徹徹底底抄襲IOS的一個產品,但是通知欄確實是Android系統原創的,反而蘋果在ios 5之後也加入了類似的通知欄功能。 通知欄的設計非常巧妙,他預設情況下不佔用任何空間,只有當用戶需要的時候用手
經典圖割演算法中圖的構建及實現:Graph-Cut
經典圖割演算法中圖的構建及實現之graph-cut 本文目的: 講解目前典型的3種圖割演算法:graph-cut、grab-but、one-cut。本文主要講解graph-cut的方法在應用時,準則函式與圖構建關係,如何構建圖,以及如何程式碼實現圖的構建。圖割的原理網上文
經典圖割演算法中圖的構建及實現:one-Cut
經典圖割演算法中圖的構建及實現之one-cut-1 本文目的: 講解目前典型的3種圖割演算法:graph-cut、grab-but、one-cut。本文主要講解one-cut的方法在應用時,準則函式與圖構建關係,如何構建圖,以及如何程式碼實現圖的構建。圖割的原理網上文章和
Learning to Rank for IR的評價指標—MAP,NDCG,MRR
MAP(Mean Average Precision):單個主題的平均準確率是每篇相關文件檢索出後的準確率的平均值。主集合的平均準確率(MAP)是每個主題的平均準確率的平均值。MAP 是反映系統在全部相關文件上效能的單值指標。系統檢索出來的相關文件越靠前(rank 越高),MAP就可能越高。如果系統沒有返回相
區塊鏈共識演算法講解及發展
本文將介紹① 主流共識演算法,簡述演算法分類,適用範圍,應用場景等② PoW(Proof of Work) 工作量證明③ PoS(Proof of Stake) 權益證明④ DPoS(Delegated Proof of Stake) 委任權益證明⑤ PBFT(Practic
BZOJ2038: [2009國家集訓隊]小Z的襪子(hose) 莫隊演算法 莫隊演算法講解及時間複雜度證明
2038: [2009國家集訓隊]小Z的襪子(hose) Time Limit: 20 Sec Memory Limit: 259 MB Submit: 7088 Solved: 3258
learning to rank 評價指標 MAP NDCG
MAP(Mean average precision):評價一個rank方法效能的一個指標,現在有很多query,首先看rank方法對各個query來說效能分別是怎麼樣的(也就是AP),再平均起來,就是MAP。AP怎麼算那?舉個例子,現有一個query,與之相關的文件有
learning to rank學習
1. 什麼是learning to rank? 2. 如何訓練一個排序模型? 訓練預料產生 對訓練預料提取特徵,通常特徵包含tf/idf, click, bm25, pagerank等特徵 訓練模型,常見模型: pointwise pairwise listwi
Android中MVP模式講解及實踐
前兩年的時候,我經常逛http://androidweekly.net這個網站,上面就有過很多文章介紹MVP模式,我很感興趣,於是把這個東西介紹給身邊的同事,同事們好像沒有多大反應,可能是當時在國內MVP用的範圍還比較少吧。後來我換了工作,再後來某一天我發
Learning to Rank 簡介
非常好的一篇總結Learning to Rank的總結文章! 去年實習時,因為專案需要,接觸了一下Learning to Rank(以下簡稱L2R),感覺很有意思,也有很大的應用價值。L2R將機器學習的技術很好的應用到了排序中,並提出了一些新的理論和演算法,不僅有效地
Learning To Rank之LambdaMART的前世今生
1. 前言 我們知道排序在很多應用場景中屬於一個非常核心的模組,最直接的應用就是搜尋引擎。當用戶提交一個query,搜尋引擎會召回很多文件,然後根據文件與query以及使用者的相關程度對文件進行排序,這些文件如何排序直接決定了搜尋引擎的使用者體驗。其他重要的應