
[Nutch]Nutch抓取過程中生成的目錄內容分析
在上一篇博文中有和大家介紹了nutch爬蟲抓取資料的整個過程,爬蟲一般會抓取到很多的內容,那麼這些內容都存放到什麼地方了呢?其實nutch在抓取的過程中會產生很多的目錄,會把抓到的內容分別儲存到不同的目錄之中。那麼,這些目錄的結構的什麼樣的?每個目錄裡面又儲存了哪些內容呢?本篇博文將為你揭曉。
從上一篇博文我們可以知道,nutch爬蟲在執行資料抓取的過程中,在data目錄下面有crawldb和segments兩個目錄:

下面我們對這兩個目錄裡面的內容做詳細的介紹:
1. crawldb
crawldb裡面儲存的是爬蟲在抓取過程中的所有的URL,裡面也有兩個目錄:current和old。

之前已經抓取過的url放到old目錄中,當前需要執行的放到current目錄裡面。
在current目錄下面有一個資料夾part-0000,如果是deploy模式的分散式方式,在這個目錄下會有相關的其他一些目錄,如:part-0001,part-0002等。在part-0000下面也有兩個目錄:data和index。

這個是hadoop的自身檔案格式,其中
- data存放hadoop的所有的表庫;
- index主要存放一些簡單的索引,用於加快和方便查詢。
2. segments
在segments目錄下面,nutch沒執行一個抓取週期,都會在segments目錄下面生成一個資料夾:

上一篇博文裡面我們在執行抓取的時候帶的引數的depth是設定為3:
nohup bin/nutch crawl urls -dir data -depth 3 -threads 100 &所以在這個命令執行完成之後,會生成3個目錄,這3個目錄都是以當前的時間作為標識。
在每個資料夾下面都存在6個子資料夾:

從上一篇博文裡面的第4小結可以看出nutch爬蟲抓取資料的整個過程:
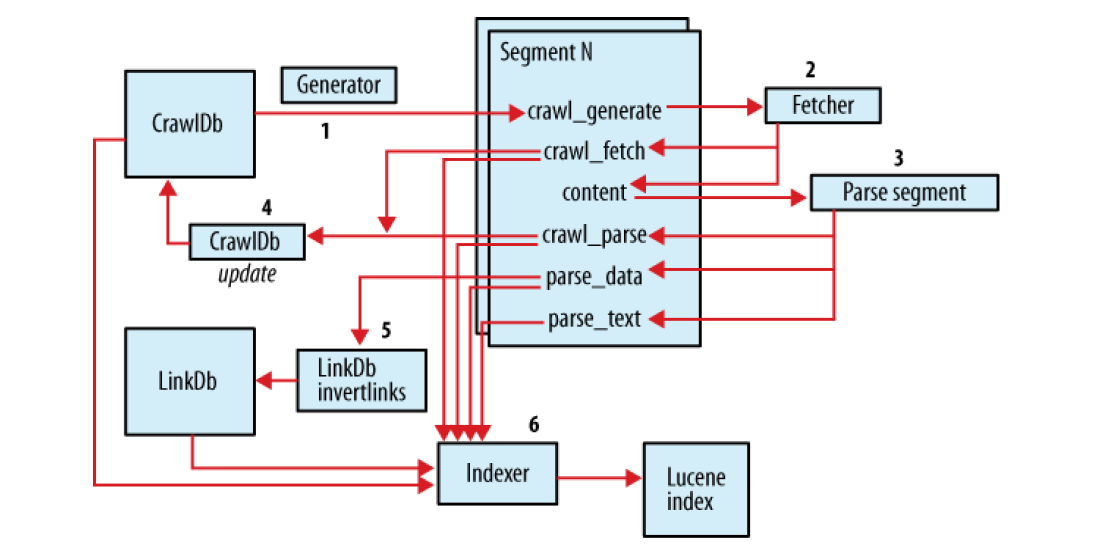
而從這個圖裡面,也可以看出,segments目錄下面的每個資料夾中的6個子資料夾都在Segment N裡面,並且每個資料夾都與nutch爬蟲抓取的4個過程有著相當緊密的聯絡。
從上圖裡面可以看出:
1. crawl_generate資料夾是nutch爬蟲在執行第1個過程generator的時候產生的。
2. crawl_fetch和content資料夾都是nutch爬蟲在執行第2個過程Fetcher的時候產生的。其中:
(1) content檔案裡裡面儲存的就是nutch爬蟲抓取的網頁的原始碼的二進位制的內容。
(2)crawl_fetch是每個url的抓取狀態:成功抓取、丟擲異常或者是其他的各種各樣的狀態。
3. crawl_parse、parse_data和parse_text是nutch爬蟲在執行第3個過程parse segment的時候 產生的。其中:
(1)crawl_parse 是每個url的解析狀態。有解析成功和解析失敗。
(2)parse_data 是儲存抓取內容的源資料。
(3)parse_text 是儲存抓取內容的文字資料。
等nutch爬蟲抓取完成之後,我們可以看到在data目錄下面變成了3個目錄,多了一個linkdb:

3. linkdb
linkdb目錄主要存放在連線過程中產生的內容,同樣的有一個part-0000目錄,在這個目錄下面也有data和index兩個子目錄。
