
詳解巨集定義(#define)
C語言中用到巨集定義的地方很多,如在標頭檔案中為了防止標頭檔案被重複包含,則用到:
#ifndef cTest_Header_h
#define cTest_Header_h
//標頭檔案內容
#endif在我們常用的 stdio.h 標頭檔案中也可以見到很多巨集定義,如:
#define BUFSIZ 1024 //緩衝區大小
#define EOF (-1) //表文件末尾
#ifndef SEEK_SET
#define SEEK_SET 0 //表示檔案指標從檔案的開頭開始
#endif
#ifndef SEEK_CUR
#define SEEK_CUR 1 //表示檔案指標從現在的位置開始 從開始寫C語言到生成執行程式的流程大致如下(姑且忽略預處理之前的編譯器的翻譯處理流程等),在進行編譯的第一次掃描(詞法掃描和語法分析)之前,會有由預處理程式負責完成的預處理工作。
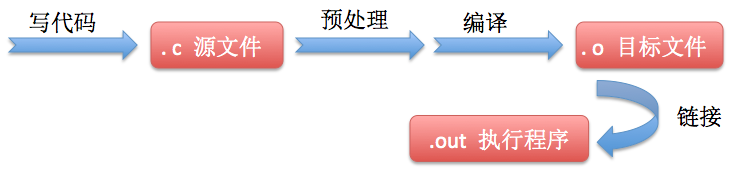
預處理工作是系統引用預處理程式對源程式中的預處理部分做處理,而預處理部分是指以“#”開頭的、放在函式之外的、一般放在原始檔的前面的預處理命令,如:包括命令 #include,巨集命令 #define 等,合理地利用預處理功能可以使得程式更加方便地閱讀、修改、移植、除錯等,也有利於模組化程式設計。本文主要介紹巨集定義的以下幾個部分:
1、概念及無參巨集
一種最簡單的巨集的形式如下:
#define 巨集名 替換文字
每個#define行(即邏輯行)由三部分組成:第一部分是指令 #define 自身,“#”表示這是一條預處理命令,“define”為巨集命令。第二部分為巨集(macro),一般為縮略語,其名稱(巨集名)一般大寫,而且不能有空格,遵循C變數命令規則。“替換文字”可以是任意常數、表示式、字串等。在預處理工作過程中,程式碼中所有出現的“巨集名”,都會被“替換文字”替換。這個替換的過程被稱為“巨集代換”或“巨集展開”(macro expansion)。“巨集代換”是由預處理程式自動完成的。在C語言中,“巨集”分為兩種:無引數 和 有引數。
無參巨集是指巨集名之後不帶引數,上面最簡單的巨集就是無參巨集。
#define M 5 // 巨集定義
#define PI 3.14 //巨集定義
int a[M]; // 會被替換為: int a[5];
int b = M; // 會被替換為: int b = 5;
printf("PI = %.2f\n", PI); // 輸出結果為: PI = 3.14注意巨集不是語句,結尾不需要加“;”,否則會被替換程序序中,如:
#define N 10; // 巨集定義
int c[N]; // 會被替換為: int c[10;];
//error:… main.c:133:11: Expected ']'以上幾個巨集都是用來代表值,所以被成為類物件巨集(object-like macro,還有類函式巨集,下面會介紹)。
如果要寫巨集不止一行,則在結尾加反斜線符號使得多行能連線上,如:
#define HELLO "hello \
the world"注意第二行要對齊,否則,如:
#define HELLO "hello the wo\
rld"
printf("HELLO is %s\n", HELLO);
//輸出結果為: HELLO is hello the wo rld 也就是行與行之間的空格也會被作為替換文字的一部分
而且由這個例子也可以看出:巨集名如果出現在源程式中的“”內,則不會被當做巨集來進行巨集代換。
巨集可以巢狀,但不參與運算:
#define M 5 // 巨集定義
#define MM M * M // 巨集的巢狀
printf("MM = %d\n", MM); // MM 被替換為: MM = M * M, 然後又變成 MM = 5 * 5巨集代換的過程在上句已經結束,實際的 5 * 5 相乘過程則在編譯階段完成,而不是在前處理器工作階段完成,所以巨集不進行運算,它只是按照指令進行文字的替換操作。再強調下,巨集進行簡單的文字替換,無論替換文字中是常數、表示式或者字串等,預處理程式都不做任何檢查,如果出現錯誤,只能是被巨集代換之後的程式在編譯階段發現。
巨集定義必須寫在函式之外,其作用域是 #define 開始,到源程式結束。如果要提前結束它的作用域則用 #undef 命令,如:
#define M 5 // 巨集定義
printf("M = %d\n", M); // 輸出結果為: M = 5
#define M 100 // 取消巨集定義
printf("M = %d\n", M); // error:… main.c:138:24: Use of undeclared identifier 'M'也可以用巨集定義表示資料型別,可以使程式碼簡便:
#define STU struct Student // 巨集定義STU
struct Student{ // 定義結構體Student
char *name;
int sNo;
};
STU stu = {"Jack", 20}; // 被替換為:struct Student stu = {"Jack", 20};
printf("name: %s, sNo: %d\n", stu.name, stu.sNo);如果重複定義巨集,則不同的編譯器採用不同的重定義策略。有的編譯器認為這是錯誤的,有的則只是提示警告。Xcode中採用第二種方式。如:
#define M 5 //巨集定義
#define M 100 //重定義,warning:… main.c:26:9: 'M' macro redefined這些簡單的巨集主要被用來定義那些顯式常量(Manifest Constants)(Stephen Prata,2004),而且會使得程式更加容易修改,特別是某一常量的值在程式中多次被用到的時候,只需要改動一個巨集定義,則程式中所有出現該變數的值都可以被改變。而且巨集定義還有更多其他優點,如使得程式更容易理解,可以控制條件編譯等。
#define 與 #typedef 的區別:
兩者都可以用來表示資料型別,如:
#define INT1 int
typedef int INT2;兩者是等效的,呼叫也一樣:
INT1 a1 = 3;
INT2 a2 = 5;但當如下使用時,問題就來了:
#define INT1 int *
typedef int * INT2;
INT1 a1, b1;
INT2 a2, b2;
b1 = &m; //... main.c:185:8: Incompatible pointer to integer conversion assigning to 'int' from 'int *'; remove &
b2 = &n; // OK因為 INT1 a1, b1; 被巨集代換後為: int * a1, b1;即定義的是一個指向int型變數的指標 a1 和一個int型的變數b1.而INT2 a2, b2;表示定義的是兩個變數a2和b2,這兩個變數的型別都是INT2的,也就是int *的,所以兩個都是指向int型變數的指標。
所以兩者區別在於,巨集定義只是簡單的字串代換,在預處理階段完成。而typede不是簡單的字串代換,而是可以用來做型別說明符的重新命名的,型別的別名可以具有型別定義說明的功能,在編譯階段完成的。
2、有參巨集
C語言中巨集是可以有引數的,這樣的巨集就成了外形與函式相似的類函式巨集(function-like macro),如:
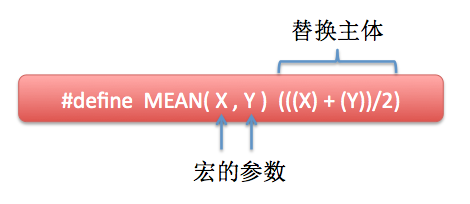
巨集呼叫:
巨集名(實參表);
printf(“MEAN = %d\n”, MEAN(7, 9)); // 輸出結果: MEAN = 8
和函式類似,在巨集定義中的引數成為形式引數,在巨集呼叫中的引數成為實際引數。
而且和無參巨集不同的一點是,有參巨集在呼叫中,不僅要進行巨集展開,而且還要用實參去替換形參。如:
#define M 5 //無參巨集
#define COUNT(M) M * M //有參巨集
printf("COUNT = %d\n", COUNT(10)); // 替換為: COUNT(10) = 10 * 10
// 輸出結果: COUNT = 100這看上去用法與函式呼叫類似,但實際上是有很大差別的。如:
#define COUNT(M) M * M //定義有參巨集
int x = 6;
printf("COUNT = %d\n", COUNT(x + 1));// 輸出結果: COUNT = 13
printf("COUNT = %d\n", COUNT(++x)); // 輸出結果: COUNT = 56 //warning:... main.c:161:34: Multiple unsequenced modifications to 'x'這兩個結果和呼叫函式的方法的結果差別很大,因為如果是像函式那樣的話,COUNT(x + 1)應該相當於COUNT(7),結果應該是 7 * 7 = 49,但輸出結果卻是21。原因在於,前處理器不進行技術,只是進行字串替換,而且也不會自動加上括號(),所以COUNT(x + 1)被替換為 COUNT(x + 1 * x + 1),代入 x = 6,即為 6 + 1 * 6 + 1 = 13。而解決辦法則是:儘量用括號把整個替換文字及其中的每個引數括起來:
#define COUNT(M) ((M) * (M)) 但即使用括號,也不能解決上面例子的最後一個情況,COUNT(++x) 被替換為 ++x * ++x,即為 7 * 8 = 56,而不是想要 7 * 7 = 49,解決辦法最簡單的是:不要在有參巨集用使用到“++”、“–”等。
上面說到巨集名中不能有空格,巨集名與形參表之間也不能有空格,而形參表中形參之間可以出現空格:
#define SUM (a,b) a + b //定義有參巨集
printf("SUM = %d\n", SUM(1,2)); //呼叫有參巨集。Build Failed!
因為 SUM 被替換為:(a,b) a + b如果用函式求一個整數的平方,則是:
int count(int x){
return x * x;
}所以在巨集定義中:#define COUNT(M) M * M 中的形參不分配記憶體單元,所以不作型別定義。而函式 int count(int x)中形參是區域性變數,會在棧區分配記憶體單元,所以要作型別定義,而且實參與形參之間是“值傳遞”。而巨集只是符號代換,不存在值傳遞。
巨集定義也可以用來定義表示式或者多個語句。如:
#define JI(a,b) a = i + 3; b = j + 5; //巨集定義多個語句
int i = 5, j = 10;
int m = 0, n = 0;
JI(m, n); // 巨集代換後為: m = i + 3, n = j + 5;
printf("m = %d, n = %d\n", m, n); // 輸出結果為: m = 8, n = 153、# 運算子
比如如果我們巨集定義了:
#define SUM (a,b) ((a) + (b)) 我們想要輸出“1 + 2 + 3 + 4 = 10”,用以下方式顯得比較麻煩,有重複程式碼,而且中間還有括號:
printf("(%d + %d) + (%d + %d) = %d\n", 1, 2, 3, 4, SUM(1 + 2, 3+ 4));那麼這時可以考慮用 # 運算子來在字串中包含巨集引數,# 運算子的用處就是把語言符號轉化為字串。例如,如果 a 是一個巨集的形參,則替換文字中的 #a 則被系統轉化為 “a”。而這個轉化的過程成為 “字串化(stringizing)”。用這個方法實現上面的要求:
#define SUM(a,b) printf(#a " + "#b" = %d\n",((a) + (b))) //巨集定義,運用 # 運算子
SUM(1 + 2, 3 + 4); //巨集呼叫
//輸出結果:1 + 2 + 3 + 4 = 10呼叫巨集時,用 1 + 2 代替 a,用 3 + 4 代替b,則替換文字為:printf(“1 + 2” ” + ” “3 + 4” ” = %d\n”,((1 + 2) + (3 + 4))),接著字串連線功能將四個相鄰的字串轉換為一個字串:
"1 + 2 + 3 + 4 = %d\n"4、## 運算子
和 # 運算子一樣,## 運算子也可以用在替換文字中,而它的作用是起到粘合的作用,即將兩個語言符號組合成一個語言符號,所以又稱為“前處理器的粘合劑(Preprocessor Glue)”。用法:
#define NAME(n) num ## n //巨集定義,使用 ## 運算子
int num0 = 10;
printf("num0 = %d\n", NAME(0)); //巨集呼叫NAME(0)被替換為 num ## 0,被粘合為: num0。
5、可變巨集:… 和 __VA_ARGS__
我們經常要輸出結果時要多次使用 prinf(“…”, …); 如果用上面例子#define SUM(a,b) printf(#a ” + “#b” = %d\n”,((a) + (b))),則格式比較固定,不能用於輸出其他格式。
這時我們可以考慮用可變巨集(Variadic Macros)。用法是:
#define PR(...) printf(__VA_ARGS__) //巨集定義
PR("hello\n"); //巨集呼叫
//輸出結果:hello在巨集定義中,形參列表的最後一個引數為省略號“…”,而“__VA_ARGS__”就可以被用在替換文字中,來表示省略號“…”代表了什麼。而上面例子巨集代換之後為: printf(“hello\n”);
還有個例子如:
#define PR2(X, ...) printf("Message"#X":"__VA_ARGS__) //巨集定義
double msg = 10;
PR2(1, "msg = %.2f\n", msg); //巨集呼叫
//輸出結果:Message1:msg = 10.00在巨集呼叫中,X的值為10,所以 #X 被替換為”1”。巨集代換後為:
printf("Message""1"":""msg = %.2f\n", msg);接著這4個字串連線成一個:
printf("Message1:msg = %.2f\n", msg);要注意的是:省略號“…”只能用來替換巨集的形參列表中最後一個!