
從MongoDB匯入資料到HDFS方法3
1.背景
公司希望使用MongoDB作為後端業務資料庫,使用Hadoop平臺作為資料平臺。最開始是先把資料從MongoDB匯出來,然後傳到HDFS,然後用Hive/MR處理。我感覺這也太麻煩了,現在不可能沒有人想到這個問題,於是就搜了一下,結果真找到一個MongoDB Connector for Hadoop
2.MongoDB簡介–摘自鄒貴金的《mongodb》一書
NoSQL資料庫與傳統的關係型資料庫相比,它具有操作簡單、完全免費、原始碼公開、隨時下載等特點,並可以用於各種商業目的。這使NoSQL產品廣泛應用於各種大型入口網站和專業網站,大大降低了運營成本。
2010年,隨著網際網路Web2.0網站的興起,NoSQL在國內掀起一陣熱潮,其中風頭最勁的莫過於MongoDB了。越來越多的業界公司已經將MongoDB投入實際的生產環境,很多創業團隊也將MongoDB作為自己的首選資料庫,創造出非常之多的移動網際網路應用。
MongoDB的文件模型自由靈活,可以讓你在開發過程中暢順無比。對於大資料量、高併發、弱事務的網際網路應用,MongoDB可以應對自如。MongoDB內建的水平擴充套件機制提供了從百萬到十億級別的資料量處理能力,完全可以滿足Web2.0和移動網際網路的資料儲存需求,其開箱即用的特性也大大降低了中小型網站的運維成本。
3.Hadoop HA叢集搭建與Hive安裝
4.正式開始
Installation
Obtain the MongoDB Hadoop Connector. You can either build it or download the jars. For Hive, you'll need the "core" jar and the "hive" jar.
Get a JAR for the MongoDB Java Driver. The connector requires at least version 3.0.0 of the driver "uber" jar (called "mongo-java-driver.jar" - 1
- 2
- 3
- 4
Requirements
Supported Hadoop and Hive versions
As of August 2013, only Hive versions <= 0.10 are stable. Mongo-Hadoop currently supports Hive versions >= 0.9. Some classes and functions are deprecated in Hive 0.11, but they’re still functional.
Hadoop versions greater than 0.20.x are supported. CDH4 is supported, but CDH3 with its native Hive 0.7 is not. However, CDH3 is compatible with newer versions of Hive. Installing a non-native version with CDH3 can be used with Mongo-Hadoop.
1.版本一定要按它要求的來,jar包去http://mvnrepository.com/下載就可以了,使用Hive只需要三個:
mongo-hadoop-core-1.5.1.jar
mongo-hadoop-hive-1.5.1.jar
mongo-java-driver-3.2.1.jar
2.將jar包拷到 HADOOPHOME/lib与” role=”presentation”>HADOOPHOME/lib與HADOOPHOME/lib與{HIVE_HOME}/lib下,然後啟動Hive,加入jar包
[[email protected] ~]$ hive
Logging initialized using configuration in jar:file:/home/hadoop/opt/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> add jar /home/hadoop/opt/hive/lib/mongo-hadoop-core-1.5.1.jar;#三個都加,我這就不寫了。- 1
- 2
- 3
- 4
3.Hive Usage有兩種連線方式:
其一MongoDB-based 直接連線hidden節點,使用 com.mongodb.hadoop.hive.MongoStorageHandler做資料Serde
其二BSON-based 將資料dump成bson檔案,上傳到HDFS系統,使用 com.mongodb.hadoop.hive.BSONSerDe
- 1
- 2
- 3
MongoDB-based方式
hive> CREATE TABLE eventlog
> (
> id string,
> userid string,
> type string,
> objid string,
> time string,
> source string
> )
> STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler'
> WITH SERDEPROPERTIES('mongo.columns.mapping'='{"id":"_id"}')
> TBLPROPERTIES('mongo.uri'='mongodb://username:[email protected]:port/xxx.xxxxxx');
hive> select * from eventlog limit 10;
OK
5757c2783d6b243330ec6b25 NULL shb NULL 2016-06-08 15:00:07 NULL
5757c27a3d6b243330ec6b26 NULL shb NULL 2016-06-08 15:00:10 NULL
5757c27e3d6b243330ec6b27 NULL shb NULL 2016-06-08 15:00:14 NULL
5757c2813d6b243330ec6b28 NULL shb NULL 2016-06-08 15:00:17 NULL
5757ee443d6b242900aead78 NULL shb NULL 2016-06-08 18:06:59 NULL
5757ee543d6b242900aead79 NULL smb NULL 2016-06-08 18:07:16 NULL
5757ee553d6b242900aead7a NULL cmcs NULL 2016-06-08 18:07:17 NULL
5757ee593d6b242900aead7b NULL vspd NULL 2016-06-08 18:07:21 NULL
575b73b2de64cc26942c965c NULL shb NULL 2016-06-11 10:13:06 NULL
575b73b5de64cc26942c965d NULL shb NULL 2016-06-11 10:13:09 NULL
Time taken: 0.101 seconds, Fetched: 10 row(s)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
這時HDFS裡是沒有存任何資料的,只有與表名一樣的資料夾
當你處理的時候,它是直接處理mongo裡最新的資料。當然,如果你想存到HDFS裡也可以,用CTAS語句就可以。
hive> create table qsstest as select * from eventlog limit 10;
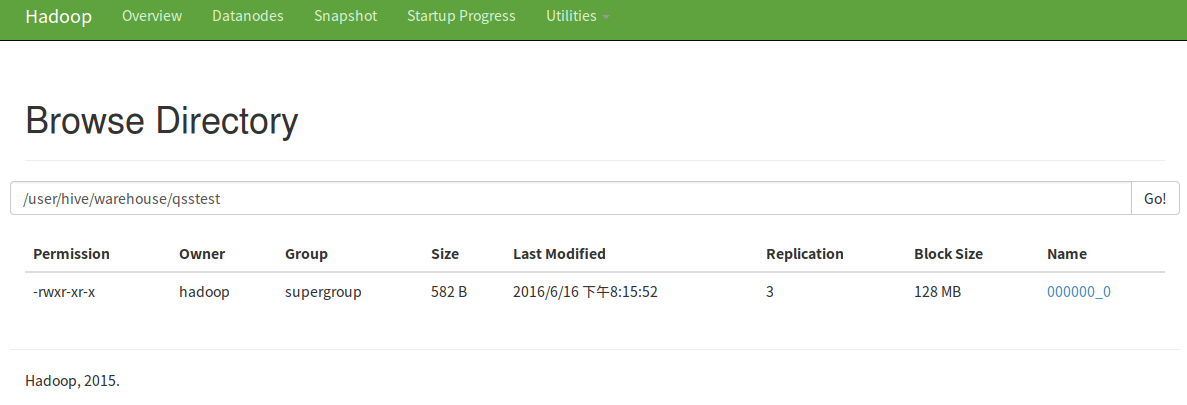
還可以下載下來呢
PS:mongo的使用者要有讀寫許可權,jar包別忘了拷進去!
另一種方式我感覺有點沒必要,沒試,但我找到一篇部落格詳細寫了。
下面轉自:MongoDB與Hadoop技術棧的整合應用
BSON-based方式
BSON-based需要先將資料dump出來,但這個時候的dump與export不一樣,不需要關心具體的資料內容,不需要指定fields list.
mongodump --host=datatask01:29017 --db=test --collection=ldc_test --out=/tmp
hdfs dfs -mkdir /dev_test/dli/bson_demo/
hdfs dfs -put /tmp/test/ldc_test.bson /dev_test/dli/bson_demo/
- 建立對映表
create external table temp.ldc_test_bson
(
id string,
fav_id array<int>,
info struct<github:string, location:string>
)
ROW FORMAT SERDE "com.mongodb.hadoop.hive.BSONSerDe"
WITH SERDEPROPERTIES('mongo.columns.mapping'='{"id":"id","fav_id":"fav_id","info.github":"info.github","info.location":"info.location"}')
STORED AS INPUTFORMAT "com.mongodb.hadoop.mapred.BSONFileInputFormat"
OUTPUTFORMAT "com.mongodb.hadoop.hive.output.HiveBSONFileOutputFormat"
location '/dev_test/dli/bson_demo/';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
OK,我們先來看下query的結果
0: jdbc:hive2://hd-cosmos-01:10000/default> select * from temp.ldc_test_mongo;
+--------------------+------------------------+-----------------------------------------------------------------+--+
| ldc_test_mongo.id | ldc_test_mongo.fav_id | ldc_test_mongo.info |
+--------------------+------------------------+-----------------------------------------------------------------+--+
| @Tony_老七 | [3,33,333,3333,33333] | {"github":"https://github.com/tonylee0329","location":"SH/CN"} |
+--------------------+------------------------+-----------------------------------------------------------------+--+
1 row selected (0.345 seconds)- 1
- 2
- 3
- 4
- 5
- 6
- 7
這樣資料就儲存在一個table,使用中如果需要開啟陣列,可以這樣
SELECT id, fid
FROM temp.ldc_test_mongo LATERAL VIEW explode(fav_id) favids AS fid;
-- 訪問struct結構資料
select id, info.github from temp.ldc_test_mongo- 1
- 2
- 3
- 4
//根據不同的資料型別進行反序列操作,複雜型別在內容做element的迴圈,最終呼叫的都是對原子型別的操作.
public Object deserializeField(final Object value, final TypeInfo valueTypeInfo, final String ext) {
if (value != null) {
switch (valueTypeInfo.getCategory()) {
case LIST:
return deserializeList(value, (ListTypeInfo) valueTypeInfo, ext);
case MAP:
return deserializeMap(value, (MapTypeInfo) valueTypeInfo, ext);
case PRIMITIVE:
return deserializePrimitive(value, (PrimitiveTypeInfo) valueTypeInfo);
case STRUCT:
// Supports both struct and map, but should use struct
return deserializeStruct(value, (StructTypeInfo) valueTypeInfo, ext);
case UNION:
// Mongo also has no union
LOG.warn("BSONSerDe does not support unions.");
return null;
default:
// Must be an unknown (a Mongo specific type)
return deserializeMongoType(value);
}
}
return null;
}
// 轉為java的原子型別儲存.
private Object deserializePrimitive(final Object value, final PrimitiveTypeInfo valueTypeInfo) {
switch (valueTypeInfo.getPrimitiveCategory()) {
case BINARY:
return value;
case BOOLEAN:
return value;
case DOUBLE:
return ((Number) value).doubleValue();
case FLOAT:
return ((Number) value).floatValue();
case INT:
return ((Number) value).intValue();
case LONG:
return ((Number) value).longValue();
case SHORT:
return ((Number) value).shortValue();
case STRING:
return value.toString();
case TIMESTAMP:
if (value instanceof Date) {
return new Timestamp(((Date) value).getTime());
} else if (value instanceof BSONTimestamp) {
return new Timestamp(((BSONTimestamp) value).getTime() * 1000L);
} else if (value instanceof String) {
return Timestamp.valueOf((String) value);
} else {
return value;
}
default:
return deserializeMongoType(value);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
相關推薦
從MongoDB匯入資料到HDFS方法3
1.背景 公司希望使用MongoDB作為後端業務資料庫,使用Hadoop平臺作為資料平臺。最開始是先把資料從MongoDB匯出來,然後傳到HDFS,然後用Hive/MR處理。我感覺這也太麻煩了,現在不可能沒有人想到這個問題,於是就搜了一下,結果真找到一個Mo
學習筆記:從0開始學習大資料-28. solr儲存資料在hdfs並從mysql匯入資料
環境 centos7 hadoop2.6.0 solr-7.5.0 一、建立hdfs為儲存的core 1.在hdfs建立索引資料目錄 [[email protected] bin]# hadoop fs -mkdir /user/solr/ [[email&
一個小例子集合xlrd,matplotlib,numpy,scipy使用方法(從Excel匯入資料)
最近因為一篇論文的原因,要從Excel中取得部分資料平作圖,但是得到的圖都是點陣圖,不是太好插入到論文中,因此,決定使用Python畫圖來解決此問題(不使用MATLAB的原因在於它畫出的圖是在是不好看呀) 首先使用的庫是xlrd庫,此庫的作用是從讀取Exc
MongoDB 批量以 JSON 形式匯入資料的方法
一些說明 為什麼要寫這篇文章? 最近在做一個 Node + Bootstrap + Vue + MongoDB 的練手專案,打算做一個線上分享詩歌的網站,雖然一開始的定位就註定不會有什麼使用者
從MongoDB抽取資料匯入mysql
# -*- coding: utf-8 -*- from pymongo import MongoClient import io import traceback import sys reload(sys) sys.setdefaultencoding('u
sqoop從mysql匯入超大表(3億資料)出錯記錄
背景: 從mysql中將三張大表匯入到hive,分別大小為6000萬,3億,3億。 使用工具: sqoop 匯入指令碼: #!/bin/bash source /etc/profile source ~/.bash_profile sqoop import -D
Oracle 使用SQL Loader 從外部匯入資料
在專案中經常會有一些基礎資料需要從Excel或其他檔案中匯入。大部分的格式都是樹結構。如果是這樣,我們對資料稍加整理,即可使用Oracle的資料匯入工具SQL Loader匯入我們所需要的資料到指定的表中。SQL Loader的詳細用法,可自己查詢相關詳細的文件,這裡只做簡單的使用介紹。 1
MongoDB匯入資料資料夾(包括bson和json檔案)報錯
MongoDB匯入資料報錯 很多部落格都說在linux下 使用 mongorestore -d db_name 資料夾目錄 就可以匯入資料夾中的內容 記錄一個傻瓜錯誤: mongorestore是一個獨立可執行程式 這個命令不能放在mongo shell裡執行 應該
Docker映象儲存為檔案及從檔案匯入映象的方法
1、概述 我們製作好映象後,有時需要將映象複製到另一臺伺服器使用。 能達到以上目的有兩種方式,一種是上傳映象到倉庫中(本地或公共倉庫),但是另一臺伺服器很肯能只是與當前伺服器區域網想通而沒有公網的,所以如果使用倉庫的方式,只能自己搭建私有倉庫,這會在另一篇文章中介紹。
Spark一些常用的資料處理方法-3.MLlib的模型(還沒寫完)
因為mllib屬於基礎庫,且本系列主要作為普及性文章,所以我不打算更新相關原理及其數學關係,有興趣自學的童鞋可以去網上翻,基本原理都是一樣的。 3.1 什麼叫模型 我理解的模型,就是對現實業務的一種數字化抽象。它既可以是一套數學公式的各種引數組合,也可以
Redis批量匯入資料的方法
有時候,我們需要給redis庫中插入大量的資料,如做效能測試前的準備資料。遇到這種情況時,偶爾可能也會懵逼一下,這裡就給大家介紹一個批量匯入資料的方法。 先準備一個redis protocol的檔案(redis protocol可以參考這裡:https://redis.io/topics/protocol)
Solr從資料庫匯入資料
一. 資料匯入(DataImportHandler-DIH) DIH 是solr 提供的一種針對資料庫、xml/HTTP、富文字物件匯入到solr 索引庫的工具包。這裡只針對資料庫做介紹。 A、準備以下jar包 apache-solr-dataimporthandl
spark從mongodb匯入資料到hive
1、首先新增mongo-spark依賴,官網地址 https://docs.mongodb.com/spark-connector/ <dependency> <groupId>org.mongodb.spar
symfony2實現從資料庫獲取資料的方法
假設有一張表:test,欄位:name,color 有兩條記錄:Tom blue Lily red 1 $conn=$this->getDoctrine()->getConnection();
C++從Excel匯入資料
前三步和”C++將資料匯出到Excel “一樣。 第四步中程式碼不一樣,如下: int pathleng; char charpath[200]; GetCurrentDirectory(512,(LPSTR)charpath);
向HBase中匯入資料3:使用MapReduce從HDFS或本地檔案中讀取資料並寫入HBase(增加使用Reduce批量插入)
前面我們介紹了:為了提高插入效率,我們在前面只使用map的基礎上增加使用reduce,思想是使用map-reduce操作,將rowkey相同的項規約到同一個reduce中,再在reduce中構建put物件實現批量插入測試資料如下:注意到有兩條記錄是相似的。package cn
MongoDB匯入大的json、csv資料檔案,匯入不完全的解決方法
轉載文章:轉自:點選開啟“https://blog.csdn.net/qq_33206732/article/details/78788483#commentsedit” 昨天,做了一個東西,就是把生產上的mongodb資料使用mongoexport匯出了一個.json檔案用於本地做分析使用,裡
MongoDB的資料匯入到HDFS上的Hive中記錄
需求 公司以前的舊資料存放在伺服器上面的MongoDB上,現在要使用這些資料進行大資料分析處理,那麼就出現了MongoDB的資料匯入到HDFS上的Hive資料表中的需求.現在寫下該部落格Mark一下! 實現步驟 1.下載jar檔案: 2.
SQLite3建立資料庫的方法 和 SQLite從Excel檔案中匯入資料 及 python/qpython sqlite 中文 亂碼
之一 有關SQLite3使用: 1.將sqlite3.exe檔案放在任何位置(本人放在E:\Php) 2.在CMD下進入到E:\Php下(cd .. cd E:\php) PS:進入其他驅動盤不需要打cd命令,比如進入D盤打D:\就可以了。cd命令是開啟檔案目
Java-讀取某個目錄下所有檔案、資料夾和3種從檔案路徑中獲取檔名的方法
1 讀取某個目錄下所有檔案、資料夾 public static ArrayList<String> getFiles(String path) { ArrayList<Str