
《計算機視覺-一種現代方法(第2版)》讀書筆記五:高層視覺
本篇思維導圖
影象配準(Registration)
1.配準剛性物體
- 變換:旋轉(rotation)、平移(translation)、縮放(scale)
∑i[(sR(θ)xi+t)−yc(i)]2∑i[(sR(θ)xi+t)−yc(i)]2 - 迭代最近點:通過估計對應點尋找正確的變換,然後估計基於對應點的變換,不斷重複
- 通過對應點搜尋變換:搜尋對應的區域性區域(圖形符號而不是點),使用它們來估計變換
- 應用:影象拼接(Image Masaics)
2.基於模型的視覺:用投影配準剛性物體
- 假設一個影象特徵集合與一個物體特徵集合對應,用這個對應關係產生一個從物體座標系到影象座標系的投影框架的猜測
- 使用這個投影假設來產生一個物體的影象,稱為反向投影
- 比較影象與所產生的物體影象,如果它們兩個足夠相似,就接受上述假設
3.配準可變形的物體
學習分類
1.分類、錯誤和損失
- 使用損失確定決策
- 訓練誤差、測試誤差和過擬合
- 正則化
- 錯誤率和交叉驗證
- ROC曲線
2.主要的分類策略
2.1 兩大通用策略
- 明確的概率模型(可理解為生成模型,如樸素貝葉斯模型)
- 直接確定決策邊界(可理解為判別模型)
2.2 策略1:使用基於馬氏距離的正態類條件概率密度

注:馬氏距離表示資料的協方差距離,它是一種有效計算兩個未知樣本集間相似度的方法。與歐式距離不同的是它考慮到各種特徵之間的聯絡,並且是尺度無關的。
該演算法的幾何解釋:在考慮方差情況下將資料項劃分到距類均值最近的類中(特別地,沿某一方向方差小的距類均值的距離有大權重,方差大的距類均值的距離權重小)
評價:在有很多訓練資料和類別的低維問題可以嘗試。馬氏距離的適用場景相對較少,因為當特徵向量是高維時求協方差矩陣比較困難。
2.3 策略2:類條件直方圖和樸素貝葉斯
如果有足夠的標記資料,就可以對類條件密度直方圖建模,這在低維情況下是有用的。
- 利用貝葉斯公式直接算出後驗概率然後進行比較
2.4 策略3:使用最近鄰的非引數分類器
對一個類別未知的樣本,可以假設其類別是在特徵空間中距離這個樣本最近的訓練樣本的類別,或找出距離待識別樣本最近的幾個,然後用這幾個訓練樣本的類別進行投票來確定待識別樣本的類別

評價:這一策略總是有用的,當訓練資料很多時與其他分類方法相比也保持有競爭力。
2.5 策略4:線性SVM
- 線性可分情況
- 線性不可分情況
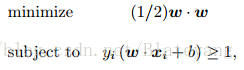
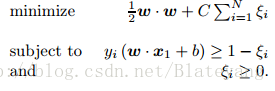
2.6 策略5:核SVM
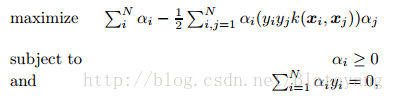
2.7 策略6:Boosting和Adaboost
集合多個弱分類器構造強分類器
3.建立分類器的實際方法
3.1 選擇分類器的經驗
經驗建議對大多數問題可以首先用線性SVM去嘗試,如果效果不理想,接下來換用核SVM或boosting方法
3.2 訓練資料處理的兩個技巧
- 資料增廣:縮放、裁剪、旋轉、翻轉等
- bootstrapping(自助法)
- 基本思想:將被分類錯誤的正負樣本插入到訓練集中重新訓練分類器,反覆迭代
- 變體:hard negative mining
從負樣本中選取出一些有代表性的負樣本(分類器檢測出的錯誤的正樣本,被稱作hard negative),不斷重新訓練,使得分類器的訓練結果更好
3.3 從二分類器中建立多分類器
- all-vs-all方法:為每類都建立一個分類器
- one-vs-all方法:為每類和其餘類建立一個分類器(比all-vs-all方法往往要更可靠和有效一些)
3.4 求解SVM和核SVM
分類影象
基本思路:利用一個已標記的資料集,建立特徵,然後訓練分類器
1. 建立好的影象特徵
不同的特徵構建適用於不同的情況。關鍵是建立那些能暴露類間變化並且抑制類內變化的特徵。
任何一種特徵表示形式都應該是對影象的旋轉、平移或縮放魯棒的,因為這些變換並不會影響影象的含義
1.1 應用例子
- 檢測特定影象(如色情圖片識別)
- 材料分類
- 場景分類
1.2 用GIST特徵編碼佈局
GIST特徵綜合了一幅影象不同部分的梯度資訊(尺度和方向),提供了關於一個場景的粗略描述
- 對於場景分類一個自然的線索就是圖片的整體佈局,GIST特徵企圖捕獲的正是這種佈局。
- GIST特徵的計算過程
- 用32個Gabor濾波器(4個尺度,8個方向)卷積影象,產生32幅特徵圖
- 把每個特徵圖等分成16個區域(4*4網格),求每個區域的特徵值均值
- 連線所有32幅特徵圖的特徵均值,形成一個16*32=512維的GIST特徵
1.3 用視覺單詞(visual words)概況影象
- 記錄具有特點的區域性影象塊,用某些區域性特徵(如SIFT特徵)描述這些區域性鄰域並進行向量量化得到視覺單詞,然後通過直方圖的形式對視覺單詞集進行統計概括,如果在一幅影象中大多數單詞與另一幅影象中的大多數單詞匹配,它們的視覺單詞直方圖就會是相似的。
- 衡量直方圖的相似性,普遍採用的是直方圖的交距離:K(h,g)=∑imin(hi,gi)K(h,g)=∑imin(hi,gi)
1.4 空間金字塔核
是視覺單詞直方圖方法的一個重要變體,能產生可有效粗略編碼空間佈局的核
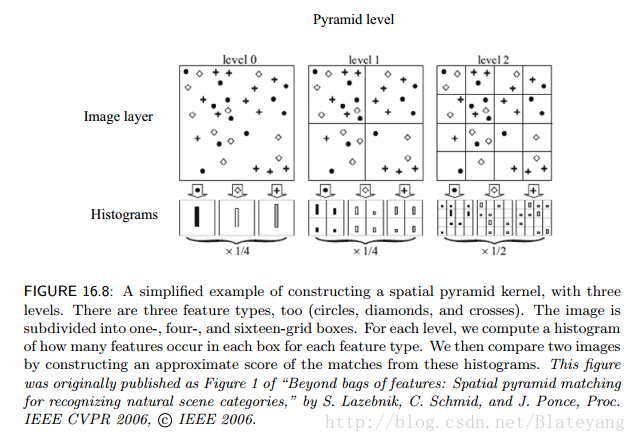
- 模型
wlwl表示相匹配的grid權重,越精細的grid權重越大 - 應用
空間金字塔核在場景影象分類上做得很好,在標準影象分類任務上也要優於直方圖交核;它能夠很好地表示相對獨立的物體或自然場景,但對於缺少紋理的物體或與背景相似的物體會遇到麻煩
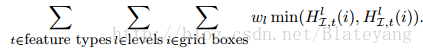
1.5 用主成分(PCA)降維

PCA建立了在特定維數下最能表達原高維資料變化的新的特徵集,但是並不能保證這個特徵集能幫助我們實現有效分類。
1.6 用典型變數(canonical variates)降維
典型變數指能夠明顯地反映出不同類別樣本間差異的線性特徵,這些特徵能使類間儘可能分開

2. 分類含有單個物體的影象
2.1 影象分類策略
- 通用策略是計算特徵,利用特徵向量構建多分類器
- 典型方法
- 使用HOG和SIFT特徵的變體,結合顏色特徵
- 視覺單詞字典(計算影象的視覺單詞,進行向量量化,用視覺單詞的直方圖表示影象然後使用直方圖交方法對其分類)
- 空間金字塔核金字塔匹配核
3. 影象分類實踐
3.1 關於影象特徵的程式碼
3.2 影象分類資料集
3.3 資料集偏差(bias)
指資料集的性質與真實世界的性質存在表示偏差
- 避免偏差的策略:
- 從多種不同的途徑收集大量資料
- 在使用資料集評估複雜方法前使用基本方法小心地評估資料集
- 採取與收集訓練資料不同的策略來收集資料,並通過評估它們來量化偏差的影響