
使用者行為日誌分析
使用者行為日誌概述
概念定義:使用者每次訪問網站時,所有的行為資料:訪問,瀏覽,搜尋,點選。。。
使用者行為軌跡,流量日誌。。。
比如:點課程,有記錄,點html css,時間,IP,pc端?對大資料感興趣
為什麼
1.可以通過日誌分析得到網站訪問量
2.網站粘性
3.相應推薦(搜尋洗衣機,根據點選日誌,能夠分析出來最近對家用電器感興趣,給你打標籤,為了促進新的訂單產生)
生成渠道:nginx,ajax(滑鼠懸停以及頁面主鍵構成)
使用者行為日誌內容;
ip
賬號
時間區域
使用的客戶端
業務相關
連結地址跳轉
分類:
1)訪客系統屬性,作業系統,瀏覽器
2)訪問特徵:url,ref,停留時間
3)訪問資訊:sessionid ,ip 這幹嘛用?能夠獲取到地市
如何
意義
網站的眼睛:來自哪裡,找什麼?你那些頁面最受歡迎?從哪裡進來的?
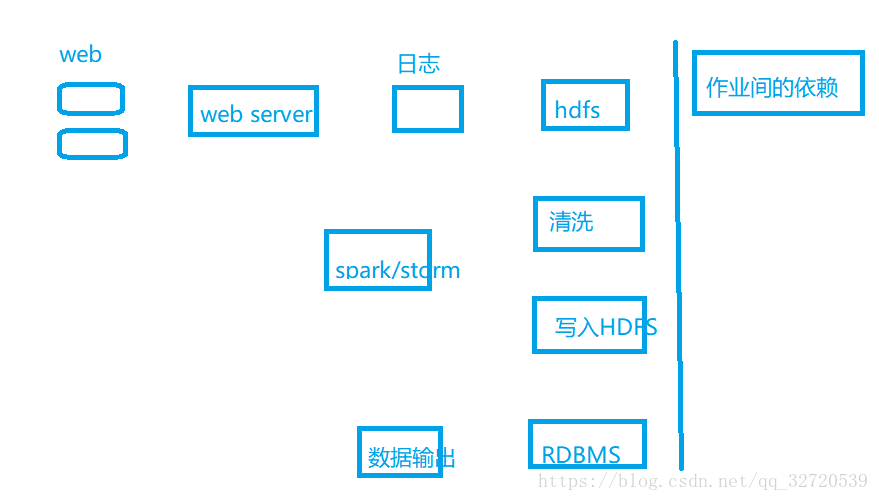
離線資料處理架構
資料採集,清洗,功能需求統計處理,寫入庫,視覺化
1)資料採集 flume專門log data web日誌寫入到hdfs上
2)資料清洗 採用spark、hive、mapreduce清洗完之後可以放在HFDF上或其他分散式計算框架上
3)資料處理 按照需求進行相應業務邏輯統計分析
4)資料處理結果入庫 結果可以存放在RDBMS和NoSQL中,呼叫對應資料庫api
5) 資料視覺化展示 通過圖形化展示的方式展現出來:餅圖、柱圖、地圖、折線圖,百度echarts,hue,zeppelin
專案需求
需求一:統計immoc主站最受歡迎的課程手記的TOPN訪問次數
需求二:按地市統計主站最受歡迎的top N課程 根據ip提取城市(藉助開源專案)
需求三:按流量統計TOP n
日誌分析:
資料清洗:編寫scala程式:1.通過debug檢視欄位,獲取所需欄位 第一步解析 2.轉換成地市、編號
。。。
dataframe儲存到Mysql
資料視覺化:echarts 依附圖片可以使實際看到的比期望看到的更多
常見的視覺化框架:echarts highcharts d3.js //hue zeppelin(不需要開發的)
功能實現
spark on yarn
效能調優(面試優化點)