
Spark RDD(DataFrame) 寫入到HIVE的程式碼實現
在實際工作中,經常會遇到這樣的場景,想將計算得到的結果儲存起來,而在Spark中,正常計算結果就是RDD。
而將RDD要實現注入到Hive表中,是需要進行轉化的。
關鍵的步驟,是將RDD轉化為一個SchemaRDD,正常實現方式是定義一個case class.
然後,關鍵轉化程式碼就兩行。
data.toDF().registerTempTable("table1")
sql("create table XXX as select * from table1")
而這裡面,SQL語句是可以修改的,如寫到某個分割槽,新建個表,選取其中幾列等。
實現效果如圖所示:
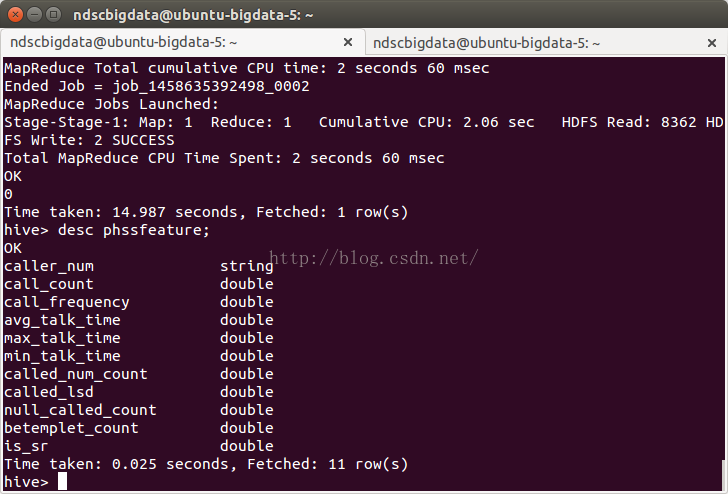
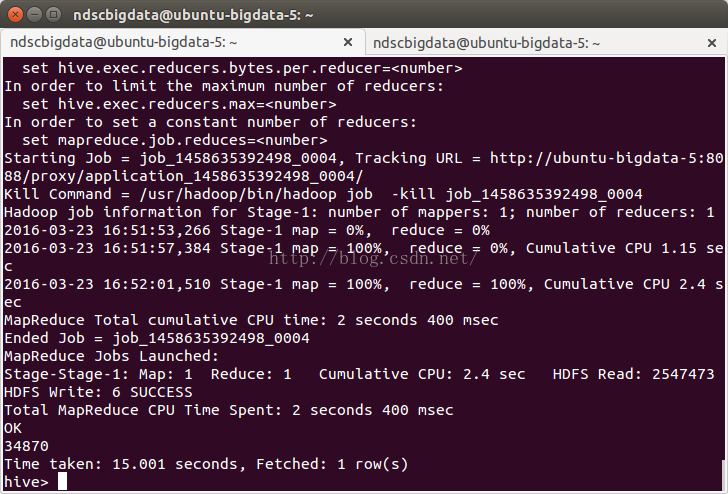
執行完成之後,可以進入HIVE檢視效果,如表的欄位,表的記錄個數等。完勝。
相關推薦
Spark RDD(DataFrame) 寫入到HIVE的程式碼實現
在實際工作中,經常會遇到這樣的場景,想將計算得到的結果儲存起來,而在Spark中,正常計算結果就是RDD。 而將RDD要實現注入到Hive表中,是需要進行轉化的。 關鍵的步驟,是將RDD轉化為一個SchemaRDD,正常實現方式是定義一個case class. 然後,
Spark:將DataFrame寫入Mysql
normal avi sqlt getc height serve saveas ecif access Spark將DataFrame進行一些列處理後,需要將之寫入mysql,下面是實現過程 1.mysql的信息 mysql的信息我保存在了外部的配置文件,這樣方便後續的配
Spark RDD-DataFrame-DataSet三者異同
三者的共性 RDD、DataFrame、Dataset全都是spark平臺下的分散式彈性資料集,為處理超大型資料提供便利 三者都有惰性機制,在進行建立、轉換,如map方法時,不會立即執行,只有在遇到Action如foreach時,三者才會開始遍歷運算,極端情況下,如果程式碼裡面有
將java RDD結果寫入Hive表中
情況一:只需插入一列 JavaRDD<String> titleParticiple = ....; /** * 將分詞結果儲存到Hive表,供資料探查使用 * */ HiveContext hiveCtx = new HiveContext(j
Spark RDD/DataFrame map儲存資料的兩種方式
使用Spark RDD或DataFrame,有時需要在foreachPartition或foreachWith裡面儲存資料到本地或HDFS。 直接儲存資料 當然如果不需要在map裡面儲存資料,那麼針對RDD可以有如下方式 val rdd = // targ
程式碼 | Spark讀取mongoDB資料寫入Hive普通表和分割槽表
版本: spark 2.2.0 hive 1.1.0 scala 2.11.8 hadoop-2.6.0-cdh5.7.0 jdk 1.8 MongoDB 3.6.4 一 原始資料及Hive表 MongoDB資
spark 將dataframe資料寫入Hive分割槽表
從spark1.2 到spark1.3,spark SQL中的SchemaRDD變為了DataFrame,DataFrame相對於SchemaRDD有了較大改變,同時提供了更多好用且方便的API。 DataFrame將資料寫入hive中時,預設的是hive預設資料庫,in
spark rdd轉dataframe 寫入mysql的示例
dataframe是在spark1.3.0中推出的新的api,這讓spark具備了處理大規模結構化資料的能力,在比原有的RDD轉化方式易用的前提下,據說計算效能更還快了兩倍。spark在離線批處理或者實時計算中都可以將rdd轉成dataframe進而通過簡
Spark RDD轉換為DataFrame
person true line ted struct ger fields text san #構造case class,利用反射機制隱式轉換 scala> import spark.implicits._ scala> val rdd= sc.text
spark RDD,DataFrame,DataSet 介紹
列式存儲 ren gre rds 包含 執行 這一 ces 中一 彈性分布式數據集(Resilient Distributed Dataset,RDD) RDD是Spark一開始就提供的主要API,從根本上來說,一個RDD就是你的數據的一個不可變的分布式元素集
spark踩坑——dataframe寫入hbase連接異常
查找 inux ron user ora nat 文件 cor 1.8 最近測試環境基於shc[https://github.com/hortonworks-spark/shc]的hbase-connector總是異常連接不到zookeeper,看下報錯日誌: 18/06/
APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
new limit runtime font blank eth epo rmi syn What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If yo
Hive使用druid做連線池程式碼實現
配置文件 hive_jdbc_url=jdbc:hive2://192.168.0.22:10000/default hive.dbname=xxxxx hive_jdbc_username=root hive_jdbc_password=123456 #配置初始化大小、最小、最大 hiv
Spark Word2Vec演算法程式碼實現
1 import com.hankcs.hanlp.tokenizer.NLPTokenizer 2 import org.apache.hadoop.io.{LongWritable, Text} 3 import org.apache.hadoop.mapred.TextInputFormat
第四天 -- Accumulator累加器 -- Spark SQL -- DataFrame -- Hive on Spark
第四天 – Accumulator累加器 – Spark SQL – DataFrame – Hive on Spark 文章目錄 第四天 -- Accumulator累加器 -- Spark SQL -- DataFrame -- Hive on Spark
Spark RDD或Dataframe持久化的選擇
背景 測試資料(df,dataframe格式):800萬條, 4.5G。 計算配置:每個executor的memory為20G,32個核。 測試語句:count條數—df.groupby("_90").count().show() 持久化操作 持久化操作
Java程式碼實現對hive的基本操作
1.匯入jar包 在eclipse上新建java專案,並在專案下建個lib資料夾,然後將jar包放到lib中匯入專案 hive的lib下的 將其全部匯入到專案中 2.測試 在你要測試的hive的主機的/usr/tmp建個student檔案,裡面放入一些
spark streaming 接收kafka資料寫入Hive分割槽表
直接上程式碼 object KafkaToHive{ def main(args: Array[String]){ val sparkConf = new SparkConf().setAppName("KafkaToHive") val sc = new SparkConte
好友推薦—基於關係的java和spark程式碼實現
本文主要實現基於二度好友的推薦。測試資料為自己隨手畫的關係圖把圖片整理成文字資訊如下:a b c d e f y b c a f g c a b d d c a e h q r e f h d a f e a b g g h f b h e g i d i j m n q h
Spark 的鍵值對(pair RDD)操作,Scala實現
一:什麼是Pair RDD? Spark為包含鍵值對對型別的RDD提供了一些專有操作,這些操作就被稱為Pair RDD,Pair RDD是很多程式的構成要素,因為它們提供了並行操作對各個鍵或跨節點重新進行資料分組的操作介面。 二:Pair RDD的操作例項