
Mybatis原始碼解析 —— Sql解析詳解
引言
Mybatis框架極大地簡化了ORM,讓使用者自定義sql語句,再將查詢結果對映到Java類中,其中很關鍵的一部分就是,將使用者寫的sql語句(以xml或者註解形式)解析成資料庫可執行的sql語句。
本文將會介紹這整個的解析過程。
Sql解析架構
本文將以一下的註解定義為例,剖析整個解析過程。
@Select({"<script>",
"SELECT account",
"FROM user",
"WHERE id IN",
"<foreach item='item' index='index' collection='list'" Sql解析其實分成了兩部分,第一部分是將註解/xml中定義的sql語句轉化成記憶體中的MappedStatement,也就是將script部分轉化成記憶體中的MappedStatement,這部分發生在Mybatis初始化的時候,第二部分則是根據MappedStatement以及傳入的引數,生成可以直接執行的sql語句,這部分發生在mapper函式被呼叫的時候。
從註解/xml 定義到MappedStatement
首先,我們要明白什麼是MappedStatement,先來看看MappedStatment的類定義。
public final class MappedStatement {
private String resource; //來源,一般為檔名或者是註解的類名
private Configuration configuration; //Mybatis的全域性唯一Configuration
private String id; //標誌符,可以用於快取
private Integer fetchSize; //每次需要查詢的行數(可選) 可以說,MappedStatement裡面包含了Mybatis有關Sql執行的所有特性,在這裡我們能夠找到Mybatis在Sql執行層面支援哪些特性,比如說可以支援定製化的資料庫列到Java屬性的對映,定製化的主鍵生成器。
對MappedStatement有一定的瞭解之後,我們就可以接著看整個的處理流程了。
處理流程如下圖所示:
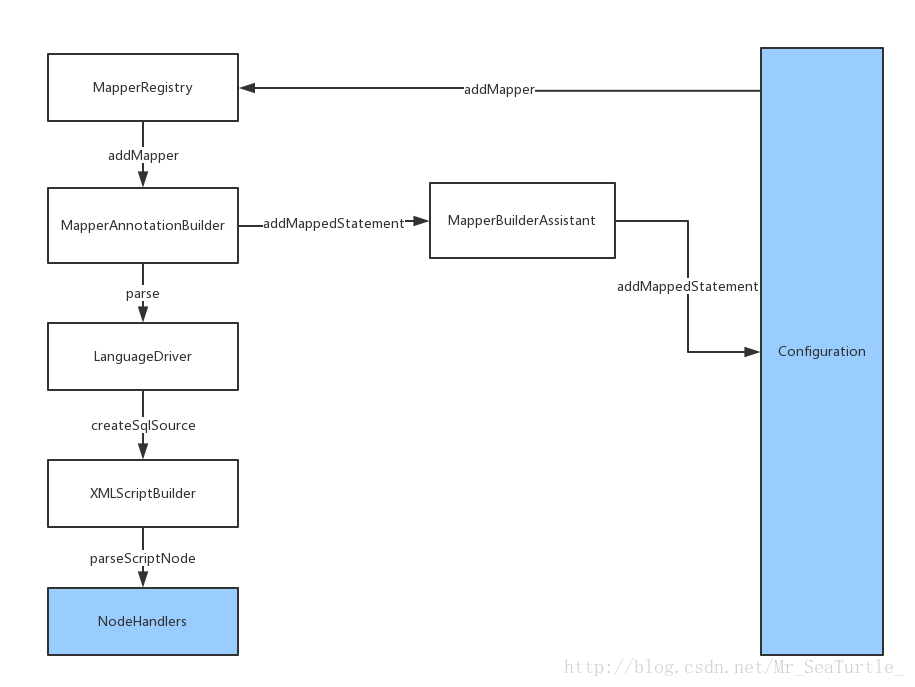
在這裡,我們能夠看到清晰的分層結構,從Configuration到具體的NodeHandlers,其實解析的任務一層層分解下來了。另外,最後解析生成的MappedStatement也會註冊到Configuration中,保證了Configuration持有對所有MappedStatement的引用。
接下來,我們看一些具體的處理邏輯,也是比較有意思的部分。
XMLLanguageDriver
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
// issue #3
if (script.startsWith("<script>")) {
XPathParser parser = new XPathParser(script, false, configuration.getVariables(), new XMLMapperEntityResolver());
return createSqlSource(configuration, parser.evalNode("/script"), parameterType);
} else {
// issue #127
script = PropertyParser.parse(script, configuration.getVariables());
TextSqlNode textSqlNode = new TextSqlNode(script);
if (textSqlNode.isDynamic()) {
return new DynamicSqlSource(configuration, textSqlNode);
} else {
return new RawSqlSource(configuration, script, parameterType);
}
}
}在XMLLanguageDriver中,真正發生瞭解析我們定義在XML/註解中的語句,這裡的解析分成了兩部分,第一部分,初始化一個Parser,第二部分,對Parser解析出來的節點再進行下一步解析。
而最後生成的SqlSource也分成了兩個種,分別為RawSqlSource以及DynamicSqlSource。這樣做的好處是,RawSqlSource可以在引數替換完成後直接執行,更加簡單高效。
接下來再來看看解析具體Node的方法,XMLScriptBuilder
List<SqlNode> parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<SqlNode>();
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
String nodeName = child.getNode().getNodeName();
//使用具體的Handler進行處理
NodeHandler handler = nodeHandlers(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
handler.handleNode(child, contents);
isDynamic = true;
}
}
return contents;
}所以,由上可知,最後我們寫在Sql定義中的</foreach>這樣的元素,會由實際的handler(ForEachHandler)來進行處理,並且最後也會生成特定的SqlNode用於動態Sql的生成。這樣就確保了Mybatis對於元素可擴充套件性的支援,同時保證了Sql的動態化。
以上,就是從我們的定義,到MappedStatement的整個過程,在這個過程裡面,結構化的XML語言被轉化成了具體記憶體裡面的一個個SqlNode,而像ResultMap這樣的註解,則被轉化成了MappedStatement裡面其它的具體屬性。
接下來,我們將會使用MappedStatement,進行可執行的Sql生成。
從MappedStatement到可執行的Sql
從MappedStatement到可執行的Sql部分相對來說就比較簡單了,裡面只涉及到從RawSqlSource/DynamicSqlSource到StaticSqlSource的轉換。
Mybatis中Sql的執行是由Executor進行的,而在執行之前,獲取了MappedStatement之後,Executor會呼叫MappedStatement的getBoundSql方法,具體流程圖如下:
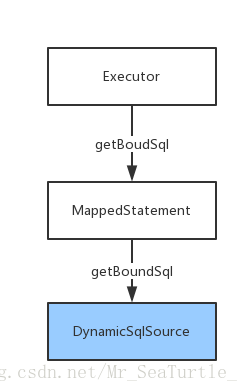
而在DynamicSqlSource中具體程式碼如下:
@Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
//首先,通過node的apply方法,動態生成佔位符,以及相應的引數對映關係
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
//然後,再使用SqlSourceBuilder轉化成staticSqlSource,這裡也會對引數對映關係進行解析
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
//這裡的bouldSql中的sql就已經是可執行的sql了
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}在這裡,我們能夠看到之前由XMLNode轉化而成的SqlNode起作用了,通過其中的Apply方法,會根據引數的長度來新增動態的?佔位符。
而返回的StaticSqlSource將會交由Executor進行包含引數設定,執行結構對映成Java例項在內的一系列操作,這個將會在後續的文章中繼續解析。
結語
本文主要介紹了Mybatis中的Sql解析過程,包含兩部分,第一部分是從XML標籤/註解到記憶體中的MappedStatement,第二部分則是從MappedStatement到StaticSqlSource。
這裡面,我們能看到Mybatis框架的幾個優點:
將Sql語句的動態部分與靜態部分分隔開來
在啟動時就提前解析XML檔案/註解為MappedStatement,提高了效率(不需要執行一次解析一次)
通過標籤使得Mybatis的動態Sql具有更加強大的擴充套件性,也體現了開閉原則。
通過這篇文章,我們能夠學習一個Sql生成器的構建思路。也能夠更加全面的瞭解到Mybatis Sql解析所支援的功能。