
CG中的深度學習 |Siggraph 2017 相關論文總結
這是侑虎科技第249篇文章,感謝作者李旻辰供稿,歡迎轉發分享,未經作者授權請勿轉載。當然,如果您有任何獨到的見解或者發現也歡迎聯絡我們,一起探討。(QQ群:465082844)
本文原載於知乎專欄Graphicon(WonderList論文心願單 - SIGGRAPH 2017 | CG中的深度學習)。同時,作者也是U Sparkle活動參與者哦,UWA歡迎更多開發朋友加入 U Sparkle開發者計劃,這個舞臺有你更精彩!
近年來,深度學習(deep learning)火了。作為一個強大的對映(mapping)構建工具,它席捲了計算機視覺(computer vision)、自然語言處理(natural language processing)等主要研究逆向問題(inverse problem)的計算機科研領域。其實,絕大多數計算機科研問題都著眼於找到一個適用於特定場景的從輸入到輸出的對映,比如:輸入三維世界描述,輸出渲染圖;輸入圖片,輸出文字描述;輸入一句話,輸出對這句話的應答;輸入這幾天股價的浮動,輸出未來股價的走勢等。但是,人類目前對以上列舉的這些對映的認識是有所不同的。
“輸入三維世界描述,輸出渲染圖”是一個典型的正向問題,即存在一套明確的建立這個對映所需遵循的規律,這些規律往往來自於人類千百年來在物理等基礎科學中的研究成果。除此之外,剩下的幾個問題都屬於逆向問題,即並不存在一套明確的對映構建方式或規則,或者說這種規則很難形式化描述,人們只能夠依據經驗來枚舉出所有的對應關係。這時,機器學習(machine learning)/統計學習(statistical learning)就彰顯出了它巨大的價值。它是一些基於統計學的模型,在某些場景中可以通過人們列舉的有限的對應關係,自動“學習”出相應的對映。深度學習,則是其加強版,能將對映學習得更加準確,但計算量也大幅增加。
深度學習目前尚未席捲計算機圖形學(computer graphics)科研領域,並不是因為我們的逆向問題不夠多,而是還沒有一個專為3D圖形資料而設計的深度學習模型(就像專為圖片設計的深度卷積神經網路CNN)。但就今年CG頂會SIGGRAPH剛剛公佈的這些論文來看,這個格局似乎馬上要被打破了。
在3D模型的表面定義了一種卷積運算(convolution),它可以理解成是把表示3D模型表面資料的mesh在2D平面上展開(parameterize)成圖片,作為CNN的輸入。值得一提的是,封閉的3D模型表面必須經過切割才能在2D平面上無重疊地展開,為了讓原本在3D模型上相鄰但由於切割而在展開的2D圖片上分離的資料也能夠一塊經歷同尺度的卷積運算,他們通過保角對映生成了原始模型的4塊方形展開圖(稱為covers),並將切割處拼接起來形成最終的圖片(實際上是一個torus的展開)。該方法能夠應用到人體3D模型語義分割(human shape segmentation)以及解剖形體的對應問題(anatomic shape correspondence)上,並且準確度較前人方法有所提升。前幾天恰逢Adobe CTL研究院的 大神(該論文作者之一)來UBC訪問並講座,筆者還和他探討了為什麼不把展開前後的deformation gradient也包含在展開的資料中的想法,同時也從他那裡得知,目前很多團隊都在嘗試研究適用於深度學習框架的3D圖形資料表示方法(representation),並被告誡入坑慎重。

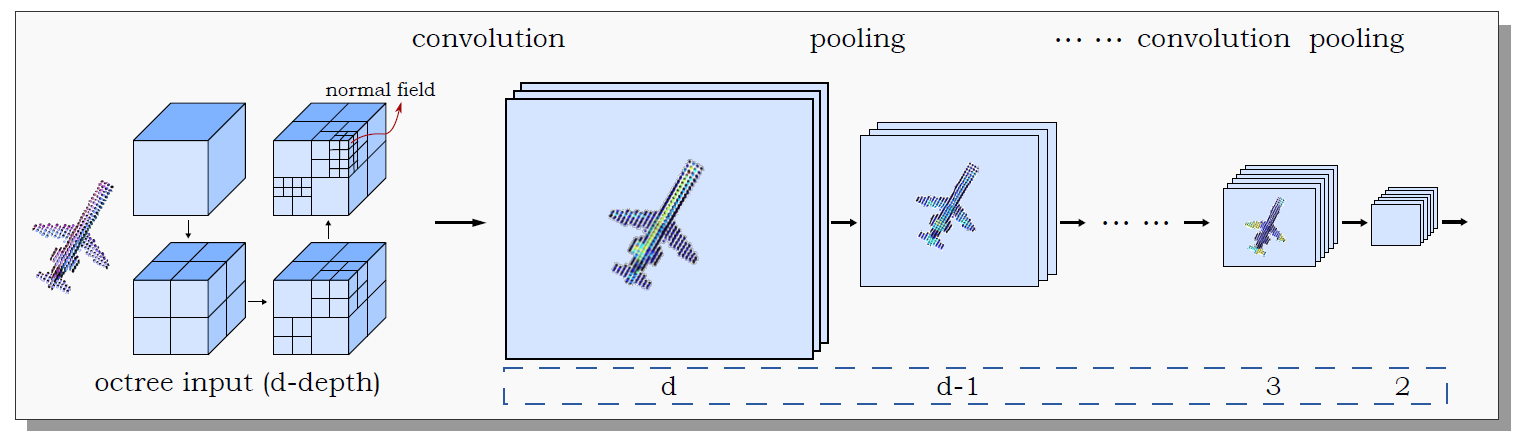
就是又一個研究適用於深度學習框架的3D圖形資料表示方法的工作。他們用空間八叉樹(Octree)表示3D模型,並以葉節點處取樣到的模型表面法向(normal)作為輸入進行3D CNN操作。由於3D CNN操作只在模型表面所位於的葉節點處進行,O-CNN對即使是很精細的3D模型也同樣適用。相較於前人的方法,其在3D模型分類(classification),檢索(retrieval),以及語義分割(semantic segmentation)上都有所的進步。
將人造形體(man-made shapes,比如傢俱、建築、交通工具等)的整體結構(global structure)與區域性形狀(local/part geometry)分開,利用基於遞迴神經網路(RvNN)的自動編碼器(autoencoder)將整體結構編碼成一個低維的特徵向量(feature vector),並利用生成式對抗網路(GAN)的思想訓練一個相應的解碼器(decoder)從而組成了一個整體結構與特徵向量間的雙向轉換器。加之一個根據整體結構生成區域性形狀的模組,一同拼接成了3D人造形體的一整套generative pipeline,在形體分類、區域性匹配、形狀生成(shape synthesis)、形狀插值(shape interpolation)等問題上都有不俗的表現。

利用CNN學習了一個描述粗糙尺度煙霧模擬區域性和精細尺度煙霧模擬區域性對應關係的對映,並且提前進行精細模擬和粗糙模擬生成了很多煙霧特效資料。這使得在新場景中生成精細的煙霧特效時,只需進行快速的粗糙模擬,並根據CNN構建的對映找出與各區域性相對應的精細模擬區域性,然後將其細節形體資訊轉移過來即可。這可不僅僅是節約了特效師製作特效的時間那麼簡單,如果粗糙模擬只是比精細模擬少了很多細節資訊,那藝術家大可以利用粗糙模擬預覽來設計整套特效,然後用選好的設定開始進行精細模擬,這並不會耽誤工作時間。然而問題就在於,粗糙模擬和精細模擬所生成煙霧的整體結構會有所不同,之前設想的煙霧形狀以及位置在精細模擬中可能會變,故這個方法根本就不可行。所以人們通常會發明一些演算法來在保持粗糙煙霧整體結構的條件下增添區域性細節,但其真實性一直是個問題。對此,這項工作利用深度學習給出了另一種思路。
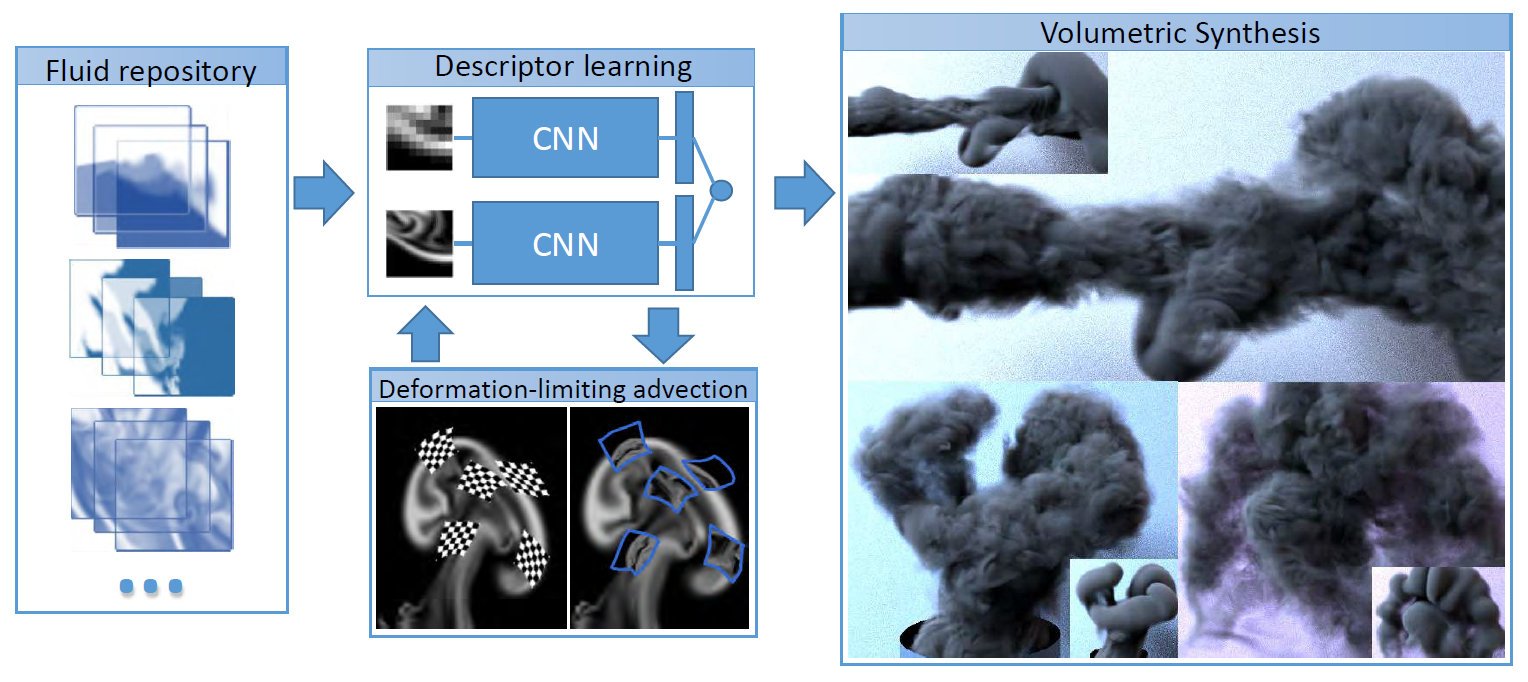
以上的前三項工作都是在嘗試為3D圖形資料尋找適用於深度學習的表達方式,從而使它們能夠被輸入到深度學習框架中去學習出更為簡練的特徵向量,並應用於3D模型的識別、感知與生成等難以直接建模求解的問題。第四項生成煙霧細節的工作略有不同,它並不是說求解物理方程無法生成足夠精細的煙霧特效,而是那樣計算功耗太大,深度學習在這裡充當了催化劑的角色,這也是另一種應用深度學習的思路。

加上筆者之前總結過的一些以及@Raymond的一些,可見(深度)機器學習這套框架在CG領域也逐漸蔓延開來了。
最後我也想說,入坑慎重。因為目前深度學習領域的研究及應用還是很靠經驗和靈性,畢竟大家都還不太清楚它的效能為什麼這麼好,也沒有一套完整的理論能夠對其進行描述與分析。其實筆者也不打算深入研究這個領域,就是跟隨深度學習先驅們瞭解他們最新的進展,想著哪天時機成熟了,可以直接用現成的。對,想得很美。
文末,再次感謝李旻辰的分享,原文所屬知乎專欄:https://zhuanlan.zhihu.com/graphicon
如果您有任何獨到的見解或者發現也歡迎聯絡我們,一起探討。(QQ群:465082844)。
也歡迎大家來積極參與U Sparkle開發者計劃,簡稱"US",代表你和我,代表UWA和開發者在一起!