
【深度學習】Batch Normalizaton 的作用及理論基礎詳解
文章開始前,先講一下 Batch Normalization 有什麼好處。
- 加速神經網路的訓練過程。
- 減少對 Dropout 的依賴
- 可以用比較大的學習率去訓練網路,然後不用在意權重引數的初始化問題。
其實,最重要的就是第一點,Batch Norm 可以加速神經網路的訓練
它號稱可以加快神經網路訓練時間達到 14 倍之多。

上圖 a,揭露的是有 Batch Norm 和沒有的訓練速度對比,資料集是 MNIST。b、c 說明的是經過 Batch Norm 後資料的分佈更穩定。
所以,如果你之前沒有嘗試過,你就可以把它嘗試一下。
怎麼使用呢?
一般的機器學習框架如 Tensorflow 和 Pytorch 等等,都有現成的 API 可供呼叫。
你只需要將它新增到啟用函式前面或者後面就可以了。
如果,你想了解它的原理和理論的話,可以繼續閱讀下面的內容。
Batch Normalization
訓練神經網路,SGD 是最廣為人知的方法,它結合方向傳播的機制,在每一步訓練過程中動態更新網路的權重數值。
W 代表權重, 代表學習率, 是每次訓練時對應的 W 的梯度,所以學習率和梯度越大,W 變化也就越快。
我們都知道深度神經網路,難於訓練。這是因為隨著前向傳播的進行,每個層的 input 值的分佈都會發生變化,這種現象被稱為 internal covariate shift,這也導致了人們需要認真處理好引數的初始化和用較小的學習率去訓練網路,而學習率越小,訓練的時間就越長。
如果大家對 internal covariate shift 概念有些模糊的話,那麼怎麼樣去理解呢?
大家看下面這張圖。

神經網路是一層接一層的,每一層的輸出可以當作是前一層的輸入。比如 L1 層的輸出就是 L2 的輸入,L2 的輸出就是 L3 的輸入。
如果輸入的值的分佈區間變化太大的話,那麼每一次訓練的時候,每一層都需要去適應新的輸入值的分佈,這使得模型比較難以穩定下來,而神經網路訓練的過程其實就是一個模型引數逐漸穩定的過程。
比如,如果輸入代表一個人的某 4 個特徵,第一次訓練時是 144、2、3、10,神經網路用一些變數去擬合。
但第二次訓練時變成了 2,100,3,28,這個時候神經網路需要重新擬合,但因為某些數值變化太大,所以神經網路相對上一次就改動很大。
第三次訓練時輸入又變成了 20、7、3、18,神經網路又需要做很大的改動。
如果這樣持續下去,神經網路要花很長的時間才能穩定下來。
所以,得找一個辦法去約束輸入的值的分佈,讓它們不能總是發生急劇的變化,即使要變化,也讓它儘量在一個可控的範圍內,這樣神經網路更新權重時不會那麼動盪。
於是,有人提出了自己的解決方法,這就是 Batch Normalization,它號稱可以加快神經網路訓練時間達到 14 倍之多。
神經網路的訓練一般和 2 個引數有關:梯度、學習率。這兩個數值越大,訓練速度就越快。
所以我們希望以比較大的學習率進行訓練,但學習率過高的話,網路反而收斂不了,所以,我們又希望能想辦法控制反向傳播時的梯度,讓它們儘可能高。
我們看看大名鼎鼎的 Sigmoid 啟用函式影象。

我們都知道輸入值越大或者越小,它越靠近 1 和 -1,從函式圖形上可以顯著看到在梯度的變化,只有在 0 的時候梯度最大,然後向兩極逐漸減少到 0,梯度接近為 0 的時候,訓練會變得很慢很慢。
假設輸入是 [1.0,2.3,130,244],前面 2 個還好,後面的就容易將整體的輸出值推向 Sigmoid 影象中梯度的飽和區間,所以我們常對輸入進行標準化,讓輸入值分佈在 0 ~ 1 之間,這有利於網路的訓練。
但是,光對輸入層進行標準化仍然不夠,後面的每一層對應的輸入值怎麼辦呢?
所以,Batch Normalization 就在神經網路的中間層對輸入做標準化。
概率論教科書告訴我們,把 X 標準化的公式如下:
是 X 變數的期望, 是標準差,而 W 就是經過標準化後得到的新的輸入變數,這樣它的值約束在期望附近的範圍,W 內部數值也符合期望為 0,方差為 1。其實,也可以稱這一過程為白化。
W 也被稱為白噪聲,在各個頻率內能量大致相同的訊號被稱為白噪聲。我們知道白色的光其實是許多光的混合,白光包含了各個頻率成分的光,但各個頻率的光能量大致相同,所以才會用白噪聲去形容這種頻率能量分佈大致相同的隨機訊號。
已經有論文證明將輸入進行白噪聲化,可以加速神經網路的訓練,所以問題是怎麼去運用,最簡便的方法就是將每一層的輸入都進行白噪聲化,但是這計算量比較大,Batch Norm 給出了自己的簡化方案。
簡化1:針對 X 的每個神經元做單獨的標準化
假如輸入是 ,那麼可以說 x 有 4 個 feature,其實就算 4 個神經元,論文中稱它們為 activation。
我們只需要針對這 4 個 activation 做標準化,而不是整個 4 個 activation 一起做標準化,因為後者開銷太大了。
需要注意的是,這個時候說的標準化是面向整個訓練集樣本的
但 Batch Norm 不僅僅是做標準化而已,它還加入了縮放和平移,這通過引入了 2 個引數 和 ,這使得標準化的結果能夠更靈活。
試想一下極端情況,有時候未經標準化的輸入其實就是最理想的狀態,強行進行標準化只會讓結果變得更加糟糕,所以 Batch Norm 得避免出現這種情況,而 可以解決這個問題。
如果 同時 ,這樣正好可以把 復原成 。
聽起來很美妙,其實還有一個問題。
我們平常訓練時,都是 mini-batch 的方式訓練的,但是上面的公式無論方差還是期望,都是基於整個訓練集上的資料做的處理,顯然這是不切實際的,因此,整個演算法需要調整和進行再一步的簡化。
你可以想一下,如果訓練集有 10 萬條資料,為了某個 activation 做標準化,你需要將所有的的資料先讀取出來,進行均值和方差計算,這樣好嗎?
簡化2:基於 mini-batch 範圍計算期望和方差
實際上 Batch Norm 的 batch 就是 mini-batch 的 batch,所以它是批量化處理的。演算法如下圖:

相比較於前面的期望和方差計算,現在的 normalization 是針對 mini-batch 的,並不是針對整個資料集的,這使得期望和方差的計算可行和可靠。
上面的 m 是指 mini-batch 的 batch 大小,所以 normalization 某個位置的 activation,均值化的是這一批次同樣位置的 activation 的值,它的分母是 m。
需要注意的是 和 ,並不是超引數,而是訓練的過程學習過來的。
現在有個問題,如果 和 能夠被學習,那麼,它們一定能夠計算出梯度,因為有梯度,所以它們才能夠不斷被更新。
事實上,可以通過鏈式法則推匯出它們的梯度的。

具體更詳細的推導,有興趣的同學可以自行結合前面的公式驗證一下。
既然 和 能夠求得梯度,那麼也就無需懷疑它們能夠學習這一結論了。
如何在 Batch Norm 過的網路中訓練和推導?
我們知道神經網路訓練的過程當中,引數是不斷更新的。
神經網路在推導的過程中,因為不涉及訓練,所以它就不需要更新了。
下面是它的演算法截圖。

神經網路的訓練還是按照前面的演算法進行。
不同的地方是推導階段,Batch Norm 對於期望和方差的取值有所改變。
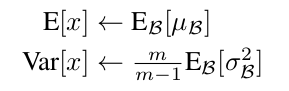
這裡,期望和方差是之前訓練的時候針對多個 mini-batch 移動平均得到的結果。
我們需要注意的一點是,在普通的神經網路層中每一個 activation 對應一對 和 。
在卷積神經網路中,情況有些不同。
Batch Norm 在卷積神經網路上的操作
在全連線層,也是仿射變化中。
如果輸入是,那麼針對這 3 個 activation 單獨做 normalization 就好了。
但是,在卷積神經網路中,有一點點不同,因為卷積過程相當於權值共享,並且它的輸出也有多個 featuremap。
如果,讓 batch norm 仍然符合基本的卷積規律,那麼應該怎麼做呢?
在每一個 mini-batch 中,針對每一個 featuremap 做整體的 normalization,而不是針對 featuremap 上的單個 activation 做 normalization.
這樣做的好處是,把整個 featuremap 當成一個 activation 來看待,每一個 featuremap 對應一對 和 , 所以和 數量減少了。
如果一個 featuremap 的 size 是 [n,m,p,q],n 是 channel 數量,m 是 mini-batch size,p 和 q 是高和寬,所以它有 nmp*q 個神經元。如果針對每個 activation 做 normalization 那麼要儲存太多的引數了。
而針對單個 featuremap 做 normalization 自然可以減少好多引數。