
python機器學習之10分鐘掌握pandas
微信公眾號:資料探勘與分析學習
1.建立物件
通過傳遞值列表來建立Series,讓pandas建立一個預設的整數索引:

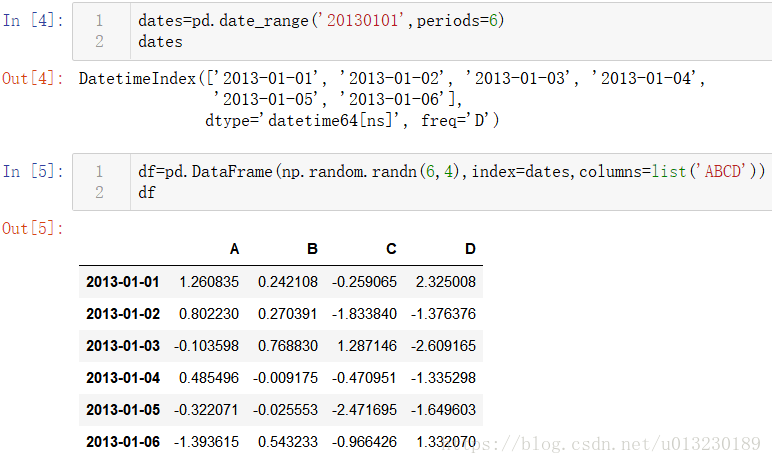
通過傳遞帶有日期時間索引和標記列的NumPy陣列來建立DataFrame:
通過傳遞可以轉換為類似series的物件的dict來建立DataFrame。

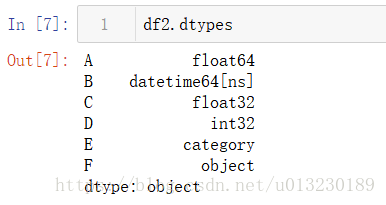
生成的DataFrame的列具有不同的dtypes。
2.檢視資料
以下是檢視frame的頂部和底部行的方法:

顯示索引,列和基礎NumPy資料:

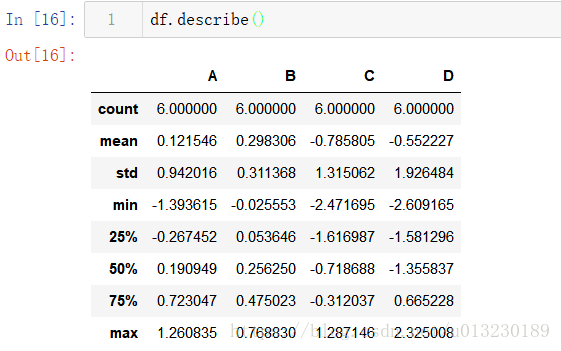
Describe()方法顯示了資料的快速統計摘要:
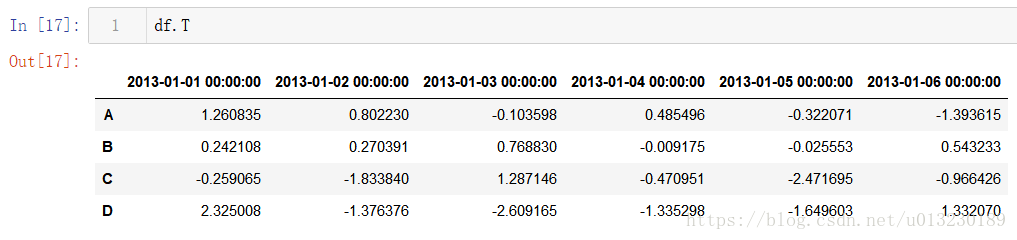
資料轉置:
根據某個軸排序

3.資料選擇
選擇一列產生一個Series,相當於df.A.

通過[]選擇,對行進行切片。

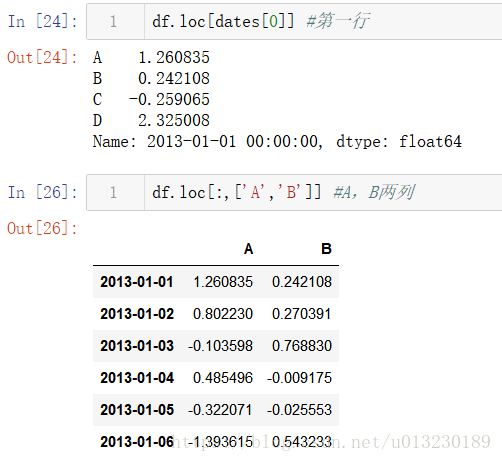
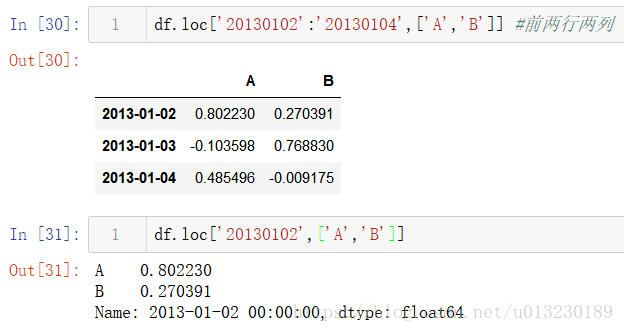
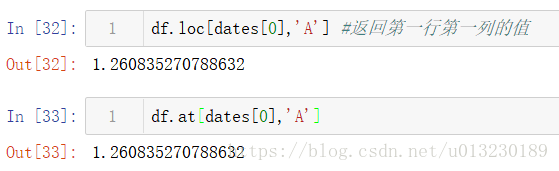
根據標籤選擇
根據位置選擇:





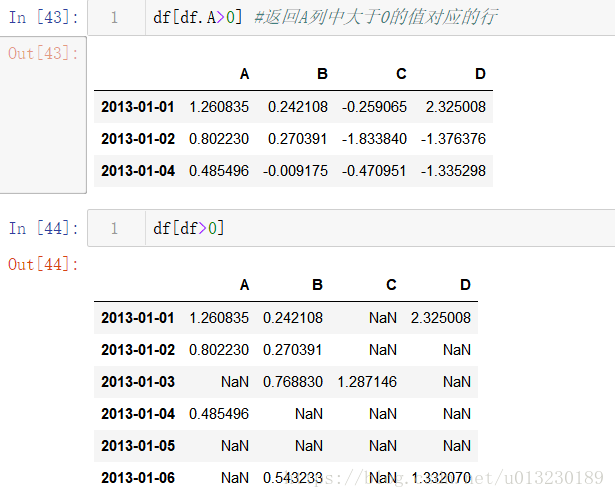
布林型別索引
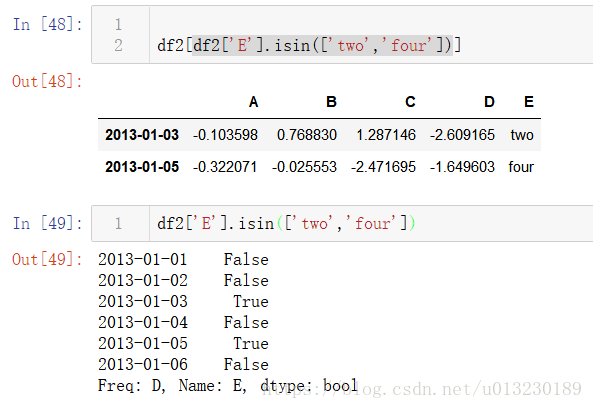
使用isin()方法過濾
設定值

4.缺失值
pandas主要使用值np.nan來表示缺失的資料。 它預設不包含在計算中。
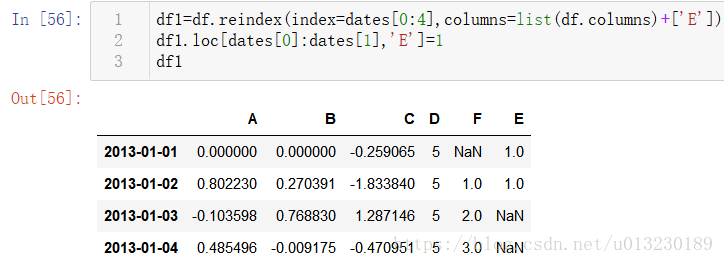
重建索引允許您更改/新增/刪除指定軸上的索引。 這將返回資料的副本。
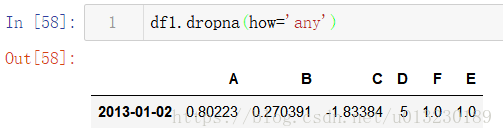
刪除含有缺失值的行
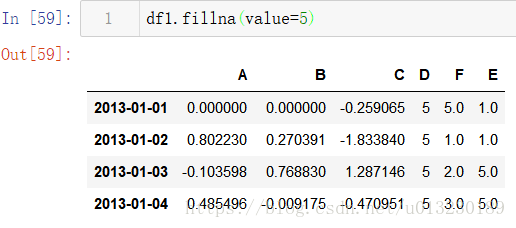
填充缺失值
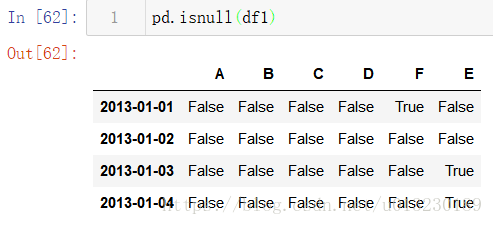
獲取值為nan的布林掩碼。
5.操作
5.1 統計
操作通常排除丟失的資料。
執行描述性統計:

使用具有不同維度的物件進行操作並需要對齊。 此外,pandas會自動沿指定維度進行廣播。

5.2 apply函式
將函式應用於資料:

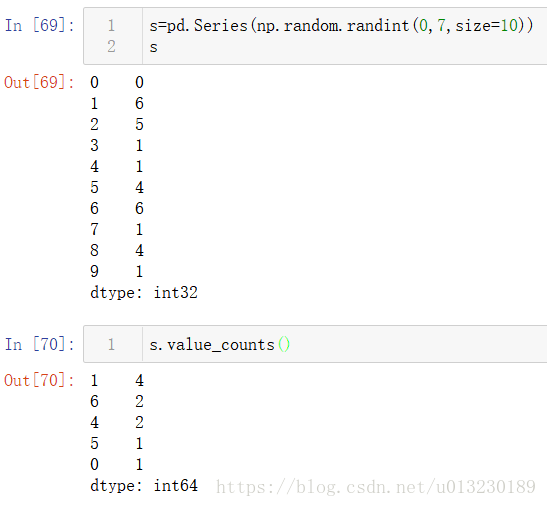
5.3 Histogramming(直方圖化)
5.4 字串方法
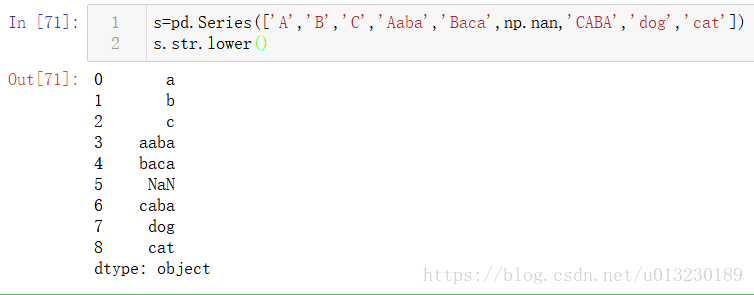
Series在str屬性中配備了一組字串處理方法,可以輕鬆地對陣列的每個元素進行操作,如下面的程式碼片段所示。請注意,str中的模式匹配通常預設使用正則表示式(在某些情況下總是使用它們)。
6.合併(merge)
6.1 concat
pandas提供了各種工具,可以在連線/合併型別操作的情況下,輕鬆地將Series,DataFrame和Panel物件與索引和關係代數功能的各種設定邏輯組合在一起。
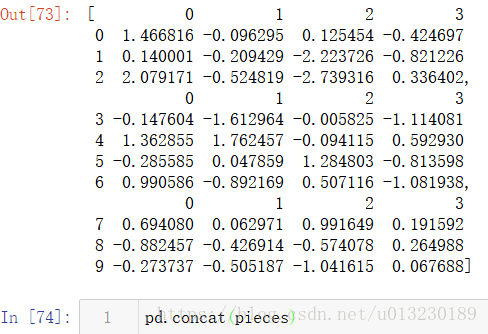
使用concat()連線pandas物件:

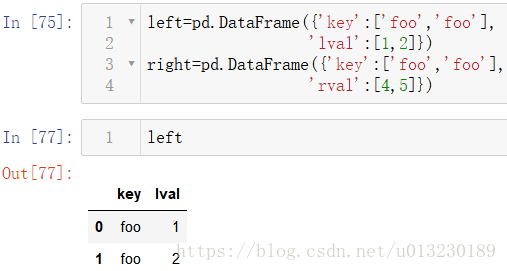
6.2 Join

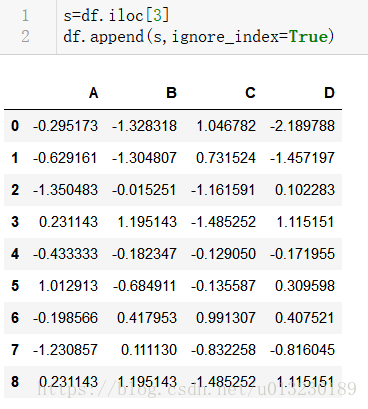
6.3 Append
新增行到dataframe

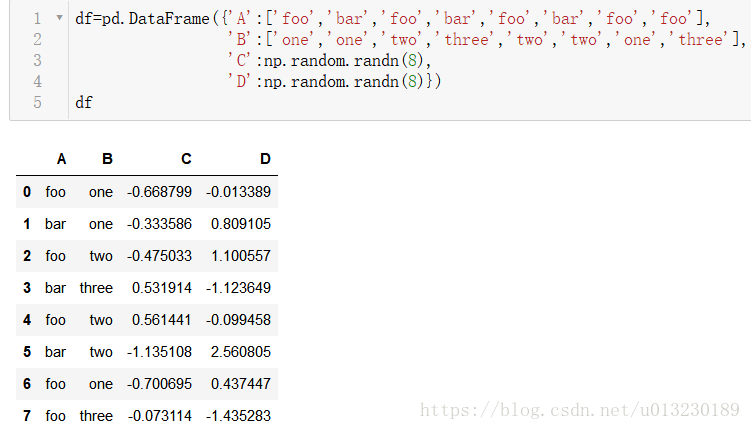
7.Grouping
通過“group by”,我們指的是涉及以下一個或多個步驟的過程:
- 根據某些標準將資料拆分為組
- 將函式獨立應用於每個組
- 將結果組合到資料結構中
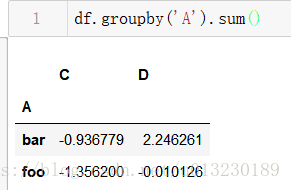
按多列分組形成分層索引,我們再次應用sum函式。
