
基於改進的K-means演算法在共享交通行業客戶細分中的應用
對應實現程式碼:傳送門(實現程式碼專注於方案的實現,k-means演算法的改進並沒有在程式碼雲中體現,為方便實現直接採用sklearn標準庫演算法)
摘要:資訊時代的來臨使得企業營銷焦點從產品中心轉變為客戶中心,客戶關係管理成為企業的核心問題。準確的客戶分類結果是企業優化營銷資源分配的重要依據,客戶分類越來越成為客戶關係管理中亟待解決的關鍵問題之一。面對共享單車行業激烈的市場競爭,各個共享交通公司都推出了更優惠的營銷方式來吸引更多的客戶,本文藉助國內某高校的校園蘿蔔車共享交通平臺,建立了合理的客戶價值評估模型—LRFMD模型,基於改進的K-means演算法對客戶進行聚類分析,比較不同客戶群的客戶價值,並制定相應的營銷策略,對不同的客戶群提供個性化的客戶服務。實證研究表明,本文所提出的模型和改進演算法可以有效的對共享交通客戶進行分類,能夠區分無價值、高價值客戶。
關鍵詞:客戶關係管理;客戶分類;共享交通;LRFMD模型;K-means演算法
引言
近幾年,中國共享交通行業風起雲湧,大量資本蜂擁而至,摩拜、ofo、滴滴各種形式的共享單車和租車公司將中國的共享交通市場炒得萬分火熱,其迅速走紅、全民關注的態勢,也說明了大眾出行是一個擁有巨大的民生需求的市場。如何利用這些海量的客戶出行資料來進行細分,針對不同價值的客戶制定優化的個性化服務方案,採取不同的營銷策略,將有限的資源集中於高價值客戶,實現企業利潤最大化目標是目前非常熱門的研究課題。
1 構建LRFMD客戶細分模型
本文將客戶關係長度L、消費時間間隔R、消費頻率F、駕駛距離M和平均折扣係數D五個指標作為蘿蔔車公司識別客戶價值指標(見表1),記為LRFMD模型。
表 1 指標含義
模型 | L | R | F | M | D |
蘿蔔車LRFMD模型 | 會員註冊時間距觀測視窗結束的月數 | 客戶最近一次乘坐駕駛蘿蔔車距觀測視窗結束的月數 | 客戶在觀測視窗內駕駛蘿蔔車的次數 | 客戶在觀測視窗內累計的行駛里程 | 客戶在觀測視窗內駕駛蘿蔔車所享受的折扣係數的平均值 |
注:觀測視窗:以過去某個時間點為結束時間,某一時間長度作為寬度,得到歷史時間範圍內的一個時間段。
針對蘿蔔車的LRFMD模型,如果採用傳統的RFM模型分析的的屬性分箱方法,如圖1所示,它是依據屬性平均值進行劃分,其中大於平均值的表示為↑,小於平均值的表示為↓,該模型雖然也能識別出最有價值的客戶,但是細分的客戶群太多,提高了針對性營銷的成本。因此本文采用聚類的方法識別客戶價值。基於改進的K-means演算法,通過對蘿蔔車客戶價值的LRFMD模型的五個指標進行聚類,識別出最有價值客戶。
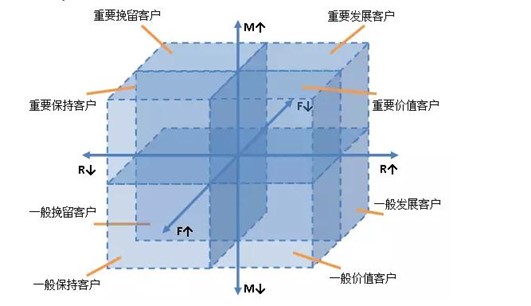
圖 1 RFM模型分析
本文基於改進的K-means演算法在共享交通行業客戶細分的總體流程如圖2所示。
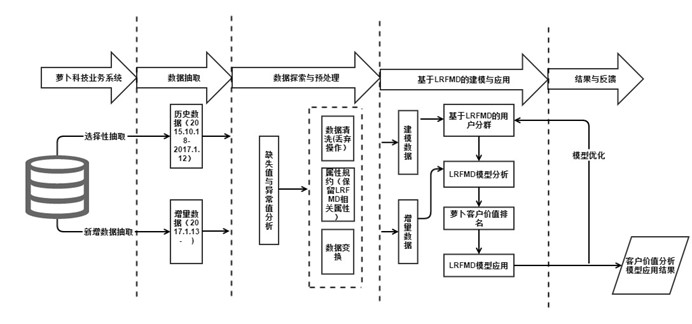
圖 2 基於改進的K-means演算法在共享交通行業客戶細分的總體流程
基於改進的K-means演算法在共享交通行業客戶細分的總體流程主要包括以下步驟。
- 從蘿蔔車在某高校運營的資料來源中進行選擇性抽取與新增資料抽取分別形成歷史資料和增量資料。
- 對步驟1)中形成的兩個資料集進行資料探索分析與預處理,包括資料缺失值與異常值的探索分析,資料的屬性規約、清洗和變換。
- 利用步驟2)中形成的已完成資料預處理的建模資料,基於改進的K-means演算法,通過客戶價值的LRFMD模型進行客戶分群,對各個客戶群進行特徵分析,識別出有價值的客戶。
- 針對模型結果得到不同價值的客戶,採用不同的營銷手段,提供定製化服務。
1.1 資料抽取
以2017/1/12為結束時間,選取寬度為一年多的時間段作為分析觀測視窗,抽取觀測視窗內有駕駛記錄的所有使用者的詳細資料形成歷史資料。對於後續新增的客戶詳細資訊,以後續新增資料中最新的時間點作為結束時間,採用上述同樣的方法進行抽取,形成增量資料。
從蘿蔔車某高校後臺資料庫內的車輛資訊以及支付記錄等詳細資料中,根據末次駕駛日期Last_Drive_Time,抽取2015/10/18-2017/1/12內所有客戶的詳細資料,總共有50715條記錄。其中包含了使用者ID、使用者編號、開車裡程、積分、罰款、折扣等28個屬性。
1.2 資料探索分析
本文的探索分析是對資料進行缺失值分析與異常值分析,分析出資料的規律與異常值。通過對資料觀察發現原始資料中存在支付金額(cost)為0,折扣(discount)為0,總行駛里程大於0的記錄。這種現象可能是使用者免費試用或者積分兌換產生的。本文查詢每列屬性觀測值中空置個數、最大值、最小值的探索結果如下所示:
表 2 資料探索結果分析表
屬性名稱 | 空值記錄數 | 最大值 | 最小值 |
User_id | 0 | 47042 | 1939 |
Current_miles | 0 | 13710 | 0 |
… | … | … | … |
Cost | 11 | 78.1 | -29.4 |
Car_id | 0 | 246 | 68 |
1.3 資料預處理
本文主要採用資料清洗、屬性規約與資料變換的預處理方法。
1.資料清洗
- 丟棄缺失值
- 丟棄Cost、Money屬性中值小於0的記錄
2.屬性規約
原始資料中屬性太多(共31個屬性),根據本文提出的LRFMD模型,選擇與LRFMD指標相關的6個屬性,即User_id,Start_time,Load_time,Cost,Money,bonus。
3.資料變換
資料變換是將資料轉換成"適當的"格式,以適應挖掘任務及演算法的需要。本文主要採用的資料變換方式為屬性構造和資料標準化。
由於原始資料中並沒有直接給出LRFMD模型的5個指標,需要通過原始資料提取這五個指標,具體的計算方式如下。
- L = Load_time – Start_time
注:使用者註冊時間距觀測視窗結束的天數 = 觀測視窗的結束時間 – 註冊時間 [單位 :天]
- R = Last_To_End
注:使用者最近一次駕駛蘿蔔車距離觀測視窗結束的天數 [單位 :天]
- F = Drive_Count
注:使用者在觀測視窗內駕駛蘿蔔車的次數 [單位:次]
- M = Sum_Current_Miles
注:使用者在觀測視窗內駕駛蘿蔔車的總行駛里程 [單位:米]
- D = Sum_Bonus/Count
注:使用者在觀測視窗內駕駛蘿蔔車所享受的折扣係數的平均值 [單位:無]
將5個指標的資料提取後,需要對每個指標的資料分佈情況進行分析,其資料的取值範圍見下表所示。
表 3 LRFMD指標取值範圍
屬性名稱 | L | R | F | M | D |
MAX | 450 | 448 | 369 | 239968 | 111 |
MIN | 1 | 1 | 1 | 0 | 0 |
AVG | 257.39 | 168.54 | 14.57 | 9308.94 | 3.87 |
從表中的資料可以發現,5個指標的取值範圍資料差異較大,為了消除數量級資料帶來的影響,需要對資料進行標準化處理。本文采用Zscore標準差標準化處理方式,處理結果部分資料一覽,如下表所示。
表 4 標準化處理後的資料集
ZL | ZR | ZF | ZM | ZD |
1.20882776 | 1.312803469 | -0.185458018 | -0.554793993 | -0.526600821 |
0.956659445 | 1.497281062 | -0.347784511 | -0.554793993 | -0.526600821 |
1.249094637 | 1.83109238 | -0.510111005 | -0.552708063 | -0.322491976 |
0.872614763 | 1.463577819 | -0.550692628 | -0.554793993 | -0.526600821 |
-1.581091175 | -1.016106791 | -0.550692628 | -0.554793993 | -0.526600821 |
1.033287101 | 1.625940291 | -0.510111005 | -0.554793993 | -0.526600821 |
0.847914913 | 1.43860888 | -0.510111005 | -0.554793993 | -0.526600821 |
1.230696342 | -0.901523796 | 1.356643666 | -0.091002535 | 2.085992401 |
2 K-means改進演算法
2.1 K-means演算法
K-means演算法源於訊號處理中的一種向量量化方法,現在則更多地作為一種向量量化方法,現在則更多地作為一種聚類分析方法流星雨資料探勘領域。K-means聚類的目的是:把n個點(可以是樣本的一次觀察或一個例項)劃分到k個聚類中,使得每個點都屬於離他最近的均值(此即聚類中心)對應的聚類,以之作為聚類的標準。這個問題將歸結為一個把資料空間劃分為Voronoi cells的問題[8][9]。這個問題在計算式是NP難,不過存在高效的啟發式演算法。一般情況下,都使用效率比較高的啟發式演算法[10],它們能夠快速收斂於一個區域性最優解。已知觀測集(,,…,),其中每個觀測都是一個d維實向量,K-means聚類要把這n個觀測劃分到k個集合中(k≦n),使得組內平方和(WCSS with-cluster sum of squares)最小。換句話說,它的目標是找到使得下式滿足的聚類:
(1)
其中是中所有點的均值。K-means演算法具體步驟如下。
輸入:樣本資料集X和聚類數k
輸出:k個類
- 隨機選擇k個初始聚類中心;
- 逐個將資料集X中各點按最小距離原則分配給k個聚類中心的某一個;
- 重新計算每個類的聚類中心;
- 若新的聚類中心和原來的聚類中心相等或小於預設閾值,則計算結束,否則轉步驟(2)。
2.2 改進K-means演算法
使得K-means演算法效率很高的兩個關鍵特徵同時也被視為它最大的缺陷:
- 聚類數目k是一個輸入引數。選擇不恰當的k值可能會導致糟糕的聚類結果。這也是為什麼要進行特徵檢查來決定資料集的聚類數目了。
- 收斂到區域性最優解,可能導致"反直觀"的錯誤結果。
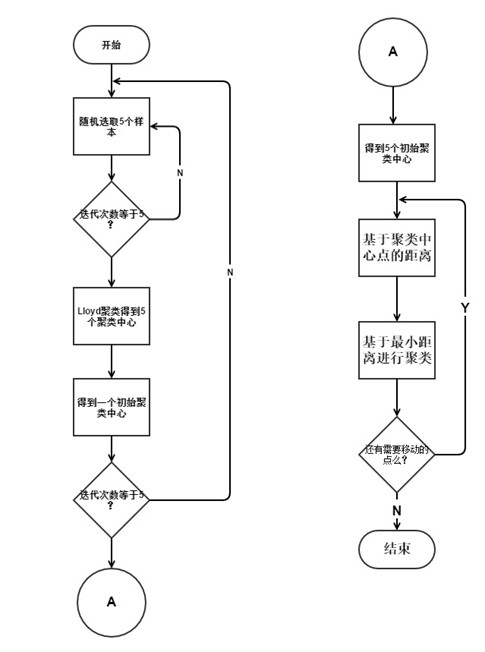
圖 3 改進K-means演算法流程圖
k-均值演算法的一個重要的侷限性即在於它的聚類模型。這一模型的基本思想在於:得到相互分離的球狀聚類,在這些聚類中,均值點趨向收斂於聚類中心。 一般會希望得到的聚類大小大致相當,這樣把每個觀測都分配到離它最近的聚類中心(即均值點)就是比較正確的分配方案。
2.2.1 改進初始聚類中心的選取方法
傳統K-means聚類演算法通過初始中心迭代得到最後的 k 箇中心。這個初始中心可以隨便選也可以隨機選,也可以只取前 k 個樣本作為初始中心。聚類最後的結果與初始聚類中心的關係還是比較密切的,不同的初始中心可能會得到完全不同的結果。文獻[11]提出了基於資料分段的思想來確定出事聚類中心。文獻[12]提出了基於距離估計的方式確定初始聚類中心。文獻[13]提出了K-means++基於最大概率的方式確定初始聚類中心。雖然文獻[13]提出的K-means++演算法可以確定地初始化聚類中心,但是從可擴充套件性來看,它存在一個缺點,那就是它內在的有序性特性:下一個中心點的選擇依賴於已經選擇的中心點。針對該缺點,本文在K-means++的基礎上改變了每次遍歷的取樣策略,每次遍歷取樣O(k)個樣本,重複該取樣過程大約O(logn)次,重複取樣過後共得到O(klogn)個樣本點組成的集合,該集合以常數因子近似於最優解,然後再聚類這O(klogn)個點成k個點,最後將這k個點作為初始聚類中心送入Lloyd迭代中,實際實驗證明O(logn)次重複取樣是不需要的,一般5次重複取樣就可以得到一個較好的聚類初始中心。如圖3所示,方法具體如下:
- 從輸入的資料點集合中隨機選擇O(k)個點作為聚類中心,重複5次取樣,得到 O(5*k) 個樣本點組成的集合 ,再聚類為k個初始中心點;
- 對於資料集中的每一個點x,計算它與最近聚類中心(指已選擇的聚類中心)的距離D(x),並基於歐氏距離的最大概率準則選擇新的聚類中心;
- 重複過程(2)直到找到k個聚類中心。
第(2)步中,依次計算每個資料點與最近的種子點(聚類中心)的距離,依次得到D(1)、D(2)、…、D(n)構成的集合D,其中n表示資料集的大小。在D中,為了避免噪聲,不能直接選取值最大的元素,應該選擇值較大的元素,然後將其對應的資料點作為種子點。本文采用了模糊c在spark中的應用[14]的實現思路:取一個隨機值,用權重的方式來取計算下一個"種子點"。 這個演算法的實現是,先用乘以隨機值Random得到值r,然後用,直到其,此時的點就是下一個"種子點"。
2.2.2 聚類數K值的選取
運用K-means演算法時,需要預先給定聚類數k,該演算法是針對客戶價值細分領域的,可以根據工程經驗將k值取作5。
2.2.3 聚類結果
運用K-means演算法對包含L、R、F、M、D各指標的標準化資料進行聚類,聚類結果如表5、圖4所示。
表 5 客戶分類情況
ZL | ZR | ZF | ZM | ZD | num | per |
-1.26534934 | -0.93586135 | -0.24461487 | -0.22321496 | -0.68739483 | 1030 | 29.59% |
0.56052897 | 0.81107607 | -0.33850695 | -0.35428804 | -0.01618059 | 1415 | 40.65% |
0.6649835 | -0.90491723 | 4.04972263 | 4.07757598 | -0.3143415 | 108 | 3.10% |
0.3475817 | 0.87571874 | -0.53503839 | -0.46243334 | 2.44529302 | 376 | 10.80% |
0.55734129 | -0.75230912 | 0.89627725 | 0.84189442 | -0.28001647 | 552 | 15.86% |
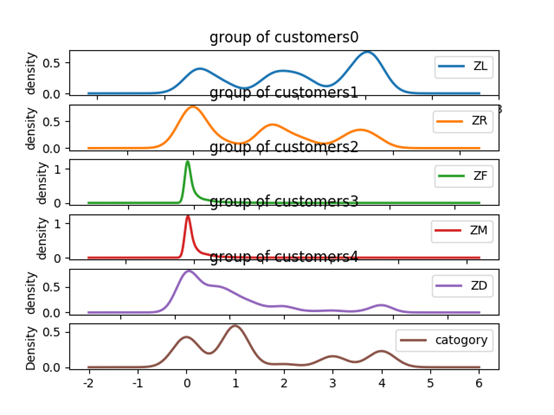
圖 4 聚類圖
3 客戶價值分析
針對聚類結果進行特徵分析,如圖5所示。其中客戶群1在R的屬性上最小;客戶群2在R屬性上最大;客戶群3在L、F、M屬性上最大,R屬性上也較小;客戶群4在D、R屬性上最大。結合蘿蔔車具體業務分析,通過比較各個
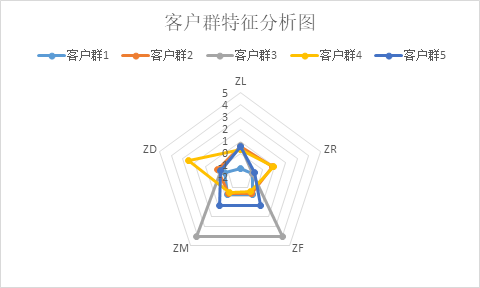
圖 5 客戶群特徵分析圖
指標在群間的大小對某個群的特徵進行評價分析。例如客戶群3在L、F、M屬性上最大,R上屬性最小,因此可以說L、R、F、M在客戶群3上是劣勢特徵。以此類推,從而總結出每個群的優勢和弱勢特徵,具體結果如表6所示。
表 6 客戶群特徵描述表
群類別 | 優勢特徵 | 弱勢特徵 | |||||
客戶群1 | R | L | |||||
客戶群2 | R | ||||||
客戶群3 | L | R | F | M | |||
客戶群4 | R | F | M | ||||
客戶群5 | |||||||
由上述的特徵分析的圖表說明每個客戶群都有著顯著不同的表現特徵,基於該特徵描述,本案例定義五個等級的客戶類別:重要保持客戶、重要發展客戶、重要挽留客戶、一般客戶、低價值客戶。每種客戶類別如下:
- 重要保持客戶: 一般來說,這類客戶的平均折扣率較低(因為蘿蔔車只
會在某些時間點如促銷期進行折扣優惠活動,較低的平均折扣率對應著
較多的使用次數) 最近駕駛蘿蔔車(R)低,駕駛次數(F)且駕駛里程(M)高,會員時間(L)長。他們是蘿蔔車的最理想的客戶型別及忠實使用者,對蘿蔔車的運營貢獻最大,但是所佔比例卻最小( 3.10%)。
- 重要發展客戶:這類客戶雖然會員時間(L)短,但是最近駕駛蘿蔔車(R)小,行駛里程(M)與駕駛次數(F)較高,佔比(29.59%)。
- 重要挽留客戶:這類客戶入會時間(L)長,最近駕駛蘿蔔車(R)較長,但是總的行駛里程(M)與駕駛次數(F)不低,說明這類客戶有挽留的必要,要分析為何最近不使用蘿蔔車了,需要多維持與使用者的互動,佔比(15.86%)。
- 一般客戶與低價值客戶:這類客戶較長時間沒有使用過蘿蔔車,乘坐次
數(F)或者里程(M)比較少,佔比(51.45%)。
根據每種客戶型別的特徵,對各類客戶群進行客戶價值排名,其結果如表7所示。針對不同型別的客戶群提供不同的產品與服務,提升重要發展客戶的價值、穩定和延長重要保持客戶的高水平消費、防範重要挽留客戶的流失並積極進行關係恢復。
表 7 客戶群價值排名
客戶群 | 排名 | 排名含義 |
3 | 1 | 重要保持客戶 |
1 | 2 | 重要發展客戶 |
5 | 3 | 重要挽留客戶 |
2 | 4 | 一般價值客戶 |
4 | 5 | 低價值客戶 |
4 討論及侷限性
本文所提出的模型採用歷史資料建模,隨著時間的變化,分析資料的觀測視窗也在變換。因此,對於新增客戶詳細資訊,考慮業務的實際情況,建議該模型每一個月執行一次,對其新增客戶的聚類中心進行判斷,同時對本次新增客戶的特徵進行分析。如果增量資料的實際情況與判斷結果差異大,需要業務部門重點關注,檢視變化大的原因以及確認模型的穩定性。如果模型穩定性變化大,需要重新訓練模型進行調整。
5 總結
本文藉助國內某高校的校園蘿蔔車共享交通平臺,建立了合理的客戶價值評估模型—LRFMD模型,基於改進的K-means演算法對客戶進行聚類分析,將蘿蔔車客戶分成5種類型,建立客戶群特徵描述表進行客戶價值分析,並提出了相應的營銷策略。實證研究表明,本文所提出的模型和改進演算法可以有效的對共享交通客戶進行分類,能夠區分無價值、高價值客戶。本文提出的特徵工程模型及相應的聚類演算法,也能擴充套件應用到其他領域如航空客戶細分、銀行客戶細分等。
參考文獻
- 羅亮生,張文欣.基於常旅客資料庫的航空公司客戶細分方法研究[J].現代商業,2008(23)
- Xu Xiangbin,Wang Jiaqiang,Tu Huan,et al. Customer classification of E-commerce based on improved RFM model[J]. Journal of Computer Applications,2012,32(5):1439-1442.
- Wang Kefu. Applied research on AFH customer classification based on data mining technology[J]. Technoeconomics&Management Research,2012(11):24-28.
- 賀玲, 吳玲達, 蔡益朝. 資料探勘中的聚類演算法綜述[J]. 計算機應用研究, 2007, 24(1):10-13.
- 李霞, 楊長海. K-means聚類演算法在客戶細分中的應用[J]. 五邑大學學報(自然科學版), 2008, 22(4):49-52.
- 張靜. 基於K-means聚類演算法的客戶細分研究[D]. 合肥工業大學, 2013.
- 鄭華. 聚類演算法在客戶細分中的應用研究[J]. 製造業自動化, 2010, 32(8):18-21.
- MacKay, David. Chapter 20. An Example Inference Task: Clustering. Information Theory, Inference and Learning Algorithms. Cambridge University Press.2003: 284–292. ISBN 0-521-64298-1. MR 2012999
- Since the square root is a monotone function, this also is the minimum Euclidean distance assignment.
- E.W. Forgy. Cluster analysis of multivariate data: efficiency versus interpretability of classifications. Biometrics. 1965, 21: 768–769.
- Liu C, Zeng L, Zhang J, et al. An optimized K-means clustering algorithm for CMP systems based on data set partition[J]. Journal of Computational Information Systems, 2015, 11(13):4727-4738.
- Raed T. Aldahdooh, Wesam Ashour. DIMK-means "Distance-based Initialization Method for K-means Clustering Algorithm"[J]. International Journal of Intelligent Systems & Applications, 2013, 5(2074-904X):41-51.
- Bahmani B, Moseley B, Vattani A, et al. Scalable K-means++[J]. Proceedings of the Vldb Endowment, 2012, 5(7):622-633.
- Jȩdrzejowicz J, Jȩdrzejowicz P, Wierzbowska I. Apache Spark Implementation of the Distance-Based Kernel-Based Fuzzy C-Means Clustering Classifier[J]. 2016.