
基於新浪微博的男女性擇偶觀資料分析(下)
各位朋友,大家好,我是Payne,歡迎大家關注我的部落格。我的部落格地址是:https://qinyuanpei.github.io。對於今天這篇文章的主題,相信經常關注我部落格的朋友一定不會陌生。因為在2017年年底的時候,我曾以此為題寫作了一篇文章:基於新浪微博的男女擇偶觀資料分析(上)。這篇文章記錄了我當時腦海中閃爍著的細微想法,即當你發現一件事物背後是由哲學或者心理學這類玄奧的科學在驅動的時候,不妨考慮使用數學的思維來讓一切因素數量化,我想這是最初資料分析讓我感興趣的一個原因。因為當時對文字的處理了解得非常粗淺,所以在第一次寫作這篇文章的時候,實際的工作不過是在分詞後繪製詞雲而已。等到我完成對微信好友資訊的資料分析以後,我意識到微博這裡其實可以繼續發掘。關於微信好友資訊的資料分析,可以參考這篇文章:
故事背景
關於故事背景,我在 基於新浪微博的男女擇偶觀資料分析(上) 這篇文章中說得非常清楚啦。起因就是我想知道,男性和女性在選擇伴侶的時候,到底更為關注哪些因素?在對微信好友資訊進行資料分析的時候,我們可以非常直接地確定,譬如性別、簽名、頭像、位置這四個不同的維度,這是因為我們處理的是結構化的資料。什麼是結構化的資料呢?一個非常直觀的認識是,這些資料可以按照二維表的方式組織起來。可對於微博這樣一個無結構的文字資料型別,我們除了對詞頻、詞性等因素做常規統計分析以外,好像完全找不到一個合理有效的方案,因為我們很容易就明白一件事情,即:在短短的140個字元中,人類語言的多樣性被放大到淋漓盡致
常見的技術方法
這篇文章涉及的領域稱為文字分類或者主題提取,而針對微博、簡訊、評論等這類短文字的分類,則被稱為短文字分類。為什麼要進行文字分類呢?第一,提取出潛在主題以後可以幫助我們做進一步的分析。譬如博主這裡想要從相親類微博中分析男性和女性的擇偶觀,首先要解決的就是主題建模問題,因為在擇偶過程中要考慮的因素會非常多,我們到底要選取哪些因素來分析呢?這些因素在特定領域中被稱為特徵,所以文字分類的過程伴隨著特徵提取。第二,短文字資料通常只有一個主題,看起來這是在簡化我們的分析過程,實則傳統的基於文件的主題模型演算法在這裡難以適用。
傳統主題提取模型通常由文字預處理、文字向量化、主題挖掘和主題表示等多個流程組成,每個流程都會有多種處理方法,不同的組合方法會產生不同的建模結果。目前,人們在傳統主題提取模型的基礎上,發展起了以CNN和RNN為代表的深度學習方法,在這裡我們依然關注傳統主題提取模型,因為這個領域對博主而言是個陌生的領域,這裡我們更多的是關注傳統主題提取模型。按照傳統主題提取模型,文字分類問題被拆分為特徵工程和分類器兩個部分,其中,特徵工程的作用是將文字轉化為計算機可以理解的格式,並提供強特徵表達能力,即特徵資訊可以用以分類,而分類器基本上是統計學相關的內容,其作用是根據特徵對資料進行分類。下面來簡單介紹下常見的技術方法。
特徵工程
特徵工程覆蓋了文字預處理、特徵提取和文字表示三個流程。文字預處理通常指分詞和去除停用詞這兩個過程,可以說分詞是自然語言處理的基本前提。特徵提取實際上囊括兩個部分,即特徵項的選擇和特徵項權重的計算。選擇特徵項的基本思路是:根據某個評價指標對原始資料進行排序,然後從中選擇分數最高的評價指標,同時過濾掉其餘的評價指標。通常可以選擇的評價指標有文件頻率、互資訊、資訊增益等,而特徵權重的計算主要是經典的TF-IDF演算法及其擴充套件演算法。文字表示是指將文字預處理後轉化為計算機可以理解的格式,是決定分類效果最重要的部分。傳統做法是使用詞袋模型(BOW)或者向量空間模型(VSM),比如Word2Vec就是一個將詞語轉化為向量的相關專案。因為向量模型完全忽視文字的上下文,所以為了彌補這種技術上的不足,業界同時使用基於語義的文字表示方法,比如常見的LDA語義模型。
分類器
分類器主要是統計學裡的分類方法,基本上大部分的機器學習方法都在文字分類領域有所應用,比如最常見的樸素貝葉斯演算法(Naive Bayes)、KNN、支援向量機(SVM)、最大熵(MaxEnt)、決策樹和神經網路等等。簡單來說,假設我們所有的資料樣本可以劃分為訓練集和測試集。首先,分類器可以在訓練集上執行分類演算法以生成分類模型;其次,分類器可以通過分類模型對測試集進行預測以生成預測結果;最後,分類器可以計算出相關的評價指標以評估分類的效果。這裡最常用的兩個評價指標是準確率和召回率,前者關注的是資料的準確性,後者關注的是資料的全面性。
TF-IDF與樸素貝葉斯
TF-IDF(term frequency–inverse document frequency)是一種被用於資訊檢索與資料探勘的統計學方法,常常被用來評估某個字詞對於一個檔案集或者是一個語料庫中的一份文件的重要程度。在特徵工程這裡我們提到,特徵工程中主要通過特徵權重來對資料進行排序和分類,因此TF-IDF本質上是一種加權技術。TF-IDF的主要思想是:字詞的重要性與它在檔案中出現的次數成正比上升,與此同時與它在語料庫中出現的頻率成反比下降。這句話是什麼意思呢?如果某個詞或者短語在一篇文章中出現的頻率(即TF)較高,並且在其它文章中出現的頻率(即IDF)較低,那麼就可以人為這個詞或者短語可以作為一個特徵,具備較好的類別區分能力,因此適合用來作為分類的標準。TF-IDF實際上是TF * IDF,即TF(term frequency,詞頻)與IDF(inverse document frequency,逆文件頻率)的乘積,具體我們通過下面的公式來理解:
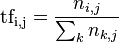
顯然,這裡的TF表示某一詞條在文件中出現的頻率。再看IDF:
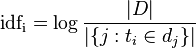
這裡的D表示語料庫中文件的數目,而分母表示的是含有指定詞的文件的數目,這裡兩者求商後取對數即可得到IDF。需要注意的是,當該詞語不在語料庫中時,理論上分母會變成0,這將導致計算無法繼續下去,因此為了修正這一錯誤,我們在分母上加1,這樣就可以得到IDF更為一般的計算公式。按照這樣的思路,我們將兩段文字分完詞以後,分別計算每一個詞的tf-idf並按照tf-idf對其進行排序,然後選取前N個元素作為其關鍵字,這樣我們就獲得了兩個N維向量,按照向量理論的相關知識,兩個向量間的夾角越小,其相關性越顯著,這就是文字相似度判斷的常規做法,在這個過程中,我們覆蓋到了文字預處理、特徵提取和文字表示三個過程,相信大家會對這個過程有更好的理解。
好了,那麼什麼是特徵呢?這裡計算出來的tf-idf實際上就是一組特徵,這個特徵是上下文無關、完全基於頻率分析的結果,現在這些結果都是計算機可以處理的數值型別,所以特徵工程要做的事情,就是從這些數值中分析出某一種規律出來。譬如,我們通過分析大量的氣象資料,認為明天有80%的概率會下雨,那麼此時下雨的概率0.8就可以作為一個特徵值,在排除干擾因素的影響以後,我們可以做一個簡單的分類,如果下雨的概率超過0.8即認為明天會下雨,反之則不會下雨。這是一個接近理想的二值化模型,在數學中我們有一種概率分佈模型稱為0-1分佈,即一件事情只有兩個可能,如果該事件會發生的概率為p,則該事件不會發生的概率為1-p。如果所有的問題都可以簡化到這種程度,我相信我們會覺得這個世界枯燥無比,因為一切非黑即白、非此即彼,這會是我們所希望的世界的樣子嗎?
為什麼在這裡我要提到概率呢?因為這和我們下面要提到的樸素貝葉斯有關。事實上,樸素貝葉斯的理論基礎,正是我們所熟悉的條件概率。根據概率的相關知識,我們有以下公式,即全概率公式:P(A|B) = P(AB)/P(B)。我們對A和B進行交換,同理可得:P(B|A) = P(A/B)/P(A)。由此我們即得到了貝葉斯公式:
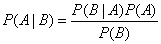
所以,樸素貝葉斯本質上是一種基於概率理論的分類演算法。我們知道條件概率成立的前提是各個事件都是獨立的,因此在樸素貝葉斯演算法中假設所有特徵間都是獨立的,可當我們逐漸地瞭解這個世界,就會明白這個世界並不是非黑即白、非此即彼的,甚至一件事情會受到來自方方面面的因素影響,就像我們從前學習物理的時候喜歡用控制變數法一樣,總有一天你會明白當時的想法太天真。樸素貝葉斯演算法中的“樸素”,通常被翻譯為Naive,而這個詞就是表示天真的意思,這正是樸素貝葉斯的名稱由來,它簡單粗暴地認為各個特徵間是相互獨立的,有人認為這種假設是相當不嚴謹的,所以相當排斥這種分類的理論,所幸樸素貝葉斯在實際應用中分類效果良好,尤其是在解決垃圾郵件過濾這類問題上,所以到今天為止,樸素貝葉斯依然是一個相當經典的分類演算法,它是一個根據給定特性/屬性,基於條件概率為樣本賦予某個類別標籤的模型。
資料分析
好了,講述這些理論知識實在是一件苦差事,因為讓讀者瞭解一套新的知識,遠遠比讓自己瞭解一套新的知識容易,所以在描述這些理論的時候,我努力地避免給大家留下晦澀深奧地印象,可這樣難免會讓讀者覺得我不太專業。可是,誰讓我們生活在一個被無數前輩開墾過地世界裡呢?作為一個資深的“調包俠”,這些理論我們能理解多少算多少,最終我們需要的只是一個庫而已,所以在正式進入下面的內容時,我們首先來梳理俠整體資料分析的思路,這樣我們就能對整個過程有一個相對感性的認識了。關於如何從新浪微博抓取資料,這個我們在上篇有詳細的介紹,這裡不再重複闡述,所有資料我們都儲存在資料庫裡,下面的圖示不再展示關於資料庫的細節:
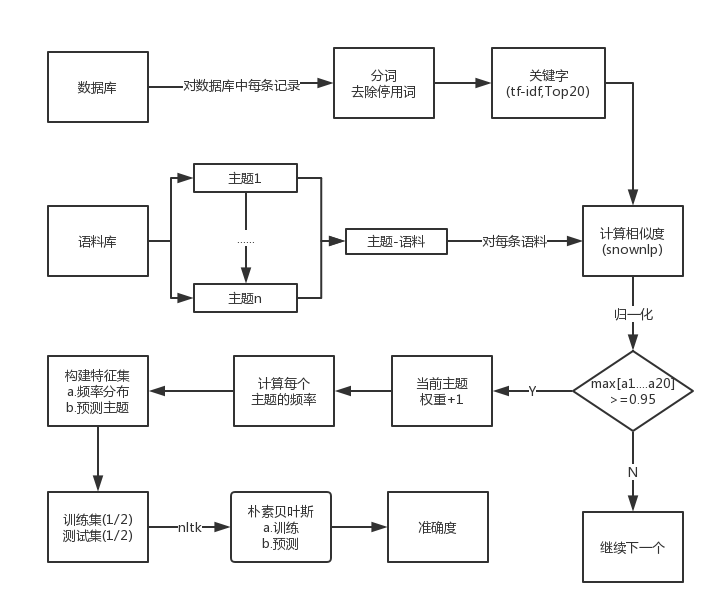
簡單來講,這是一個有監督的、使用二元分類的特徵提取過程。這裡的語料庫是由人工進行編制的文字資料,語料庫的好壞將直接影響到分類的效果。比如說,我們希望提取的特徵是陝西省的地理資訊,那麼我們就需要準備一個,由陝西省所轄的所有地級市組成的文字檔案,這裡為了方便後續處理,我們建議每行存放一個短文字資訊。
接下來,我們會從資料庫中讀取所有的資料,然後進行預處理操作,這裡的預處理是指分詞和去除停用詞,停用詞表是從網路上下載的,然後根據我們自己的需要再在基礎上進行新增,我們會選取前20個詞語作為關鍵詞,這裡使用了結巴分詞的相關介面,其演算法原理正是tf-idf。我們會使用這20個關鍵詞,和語料庫中每一個主題下的內容進行比較,這裡的相似度由SnowNLP提供支援,其計算結果是一個20維的向量,我們對向量進行歸一化後,如果其向量中所有維度的值的最大值>=0.95,則認為該文字和這一主題相關,因此該主題的權重會增加1,否則會繼續計算下一個文字的相似度。
我們彙總所有主題的權重,即可統計出各個主題出現的頻率。比如我們這裡關注A、B、C三個主題,而經過計算這三個主題各自出現的頻率為0.1、0.8和0.1,所以我們這裡可以理解為:這裡有80%的把握認為文字和B主題有關,由此我們選取出了分類的特徵,這裡我們使用一個元組來表示特徵,其表示為([0.1,0.8,0.1],”B”)。依次類推,我們就獲得了全部的特徵資訊。接下來,我們使用nltk中提供的樸素貝葉斯分類器對內容進行分類,訓練集和測試集合各佔50%,最終通過準確度來評估整個分類的效果。
特徵分析
特徵分析的難點主要在特徵的提取,在這裡我們通過不同主題的頻率來選取特徵:
def buildFeatures(sentence,document):
tokens = jieba.analyse.extract_tags(sentence)
tokens = list(filter(lambda x:x.strip() not in stopwords, tokens))
features = {}
for (subject,contents) in document.items():
for content in contents:
if(similarText(tokens,content)):
if(subject in features):
features[subject]+=1
else:
features[subject]=1
total = sum(features.values())
for subject in features.keys():
features[subject] = features[subject] / total
# 特徵歸一化
for subject in subjects:
if(subject not in features.keys()):
features[subject] = 0
# 預測結果
max_value = max(features.values())
suggest_subject = ' '
for (key,value) in features.items():
if(value == max_value):
suggest_subject = key
return features, suggest_subject其中,stopwords我們從一個指定檔案中讀取:
stopwords = open('stopwords.txt','rt',encoding='utf-8').readlines()這裡有一個計算句子和主題相似度的方法similarText(),其定義如下:
# 文字相似度
def similarText(tokens,content):
snow = SnowNLP(tokens)
similar = snow.sim(content)
norm = math.sqrt(sum(map(lambda x:x*x,similar)))
if(norm == 0):
return False
similar = map(lambda x:x/norm,similar)
return max(similar)>=0.95我們通過下面的程式碼來構建特徵,以及使用樸素貝葉斯分類器進行分類,核心程式碼如下:
def analyseFeatures():
rows = loadData()
document = loadDocument(subjects)
features = [buildFeatures(row[0],document) for row in rows]
length = len(features)
print('資料集: ' + str(length))
cut_length = int(length * 0.5)
print('訓練集: ' + str(cut_length))
train_set = features[0:cut_length]
print('測試集: ' + str(length - cut_length))
test_set = features[cut_length:]
classifier = nltk.NaiveBayesClassifier.train(train_set)
train_accuracy = nltk.classify.accuracy(classifier,train_set)
print('準確度: ' + str(train_accuracy))
counts = Counter(map(lambda x: x[1],test_set))
for key, count in counts.items():
freq = count/len(test_set)
print("主題<{0}>: {1}".format(key,freq))下面是特徵提取相關的結果,因為最近對語料庫進行了調整,所以準確度只有92%,用一位前輩的話說,資料分析就像煉丹,在結果沒有出來以前,沒有人知道答案會是什麼。這裡使用的是nltk內建的樸素貝葉斯分類器,而nltk是一個自然語言處理相關的庫,感興趣的朋友可以自行了解,這裡推薦一本書:《NLTK基礎教程(用NLTK和Python庫構建機器學習應用)》。下圖中展示了各個主題在整個微博文字中所佔的比重:
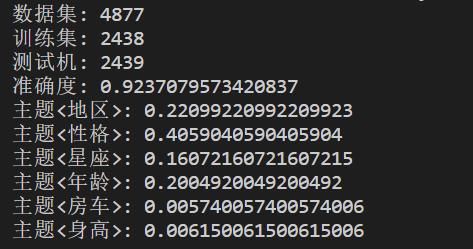
年齡分佈
對於男女性的年齡分佈,我們通過正則來提取微博中年齡相關的數值,然後統計不同年齡出現的頻數,並將其繪製為柱形統計圖,相關程式碼實現如下:
def analyseAge():
ages = []
rows = loadData()
pattern = re.compile(r'\d{2}\年|\d{2}\歲')
for row in rows:
text = row[0].decode('utf-8')
matches = pattern.findall(text)
if(len(matches)>0):
match = matches[0]
if(u'年' in match):
now = datetime.datetime.now().year
birth = int(''.join(re.findall(r'\d',match)))
ages.append(now - 1900 - birth)
else:
ages.append(int(''.join(re.findall(r'\d',match))))
ages = list(filter(lambda x: x>10 and x<40, ages))
freqs = Counter(ages).items()
freqs = sorted(freqs,key=lambda x:x[0],reverse=False)
freqs = dict(freqs)
drawing.bar('男女性擇偶觀資料分析:年齡分佈',freqs,'年齡','人數',None) 通過圖表,我們可以發現:擇偶年齡重點集中在24~28歲之間,並且整個年齡區間符合正態分佈。每年過年的時候,我們都會聽到年輕人被催婚的聲音,甚至作為一個單身的人,每一個節日都像是我們的忌日,因為無論在哪裡,你都可以被秀恩愛或者被撒狗糧。“哪有人會喜歡孤獨呢?不過是不喜歡失望”,當這句話出現在我的Kindle螢幕上,出現在村上春樹的《挪威的森林》裡,我突然有種扎心的感覺。有一天,當我不在視愛情為必需品時,我突然意識到生命裡有太多比感情重要的事情。我不希望我們因為一句年齡到了就去結婚,如果人生的一切都有期限都要按部就班,那麼為什麼我們不能平靜地面對衰老和死亡呢?人天生起點就是不一樣的,所以你不必努力去迎合別人定製的標準,就像學生時代大家面對的是同一張考卷,有的人交卷交得早,有的人交卷交得晚,有的人考試成績好,有的人考試成績差,可這不過是一場考試而已,不是嗎?如果我的時間不能浪費在我喜歡的人身上,我寧願永遠將時間浪費在自己的身上,除了生與死以外,結婚和繁衍並不是必答題,我可以不結婚啊,一如我可以交白卷啊!
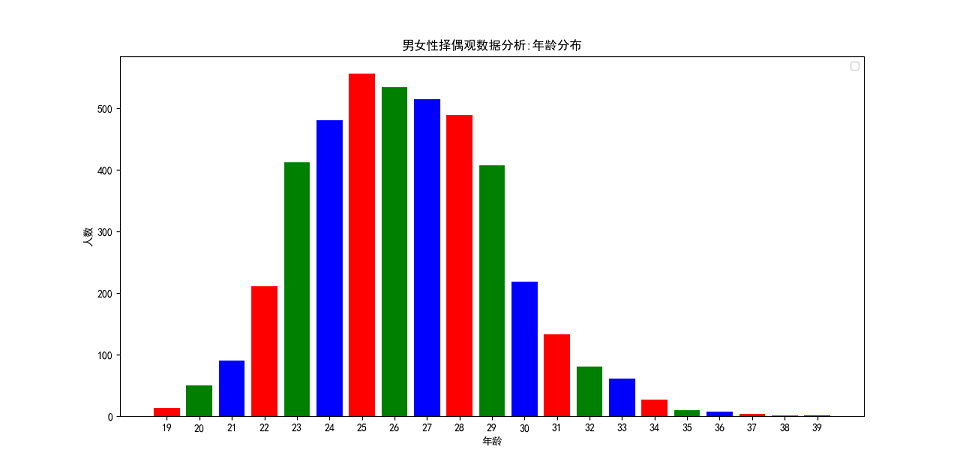
性別組成
性別組成,我們主要從微博中的關鍵字入手,因為這些微博明確了擇偶的是男嘉賓還是女嘉賓,我們通過這些特徵就可以分析出男女性別比例。相關程式碼實現如下:
def analyseSex():
rows = loadData()
sexs = {'male':0, "female":0}
for row in rows:
text = row[0].decode('utf-8')
if u'男嘉賓[向右]' in text:
sexs['male']+=1
elif u'女嘉賓[向右]' in text:
sexs['female']+=1
drawing.pie('男女性擇偶觀資料分析:男女性別比例',sexs,None) 通過下面的圖表,我們可以非常直觀地看到,男性數量是超過女性數量的,兩者比例接近1.38:1。這和目前中國的實際基本相符,考慮到人們有更多的相親渠道可以選擇,我認為實際的比例應該會更大,媒體稱適婚男性比女性多出3000萬,性別比例的失衡難免會讓男生找不到物件。可找不著物件有什麼關係呢?人生短短一世,活著時候能見到最多不過四世同堂,血緣關係並不能讓後輩替你完成未竟之事,當一個離開了這個世界,它與世界的關聯就變得微乎其微,時間會讓記憶逐漸模糊直至遺忘,你無法將這點微弱的安全感寄託在某一個人身上,人生而有涯,而知無涯,能在這個世界裡流傳下去的只有思想,我不想和任何人去攀比,因為生而為人,我很抱歉。
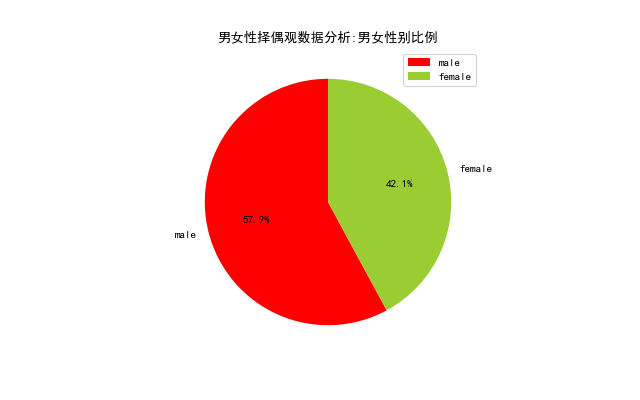
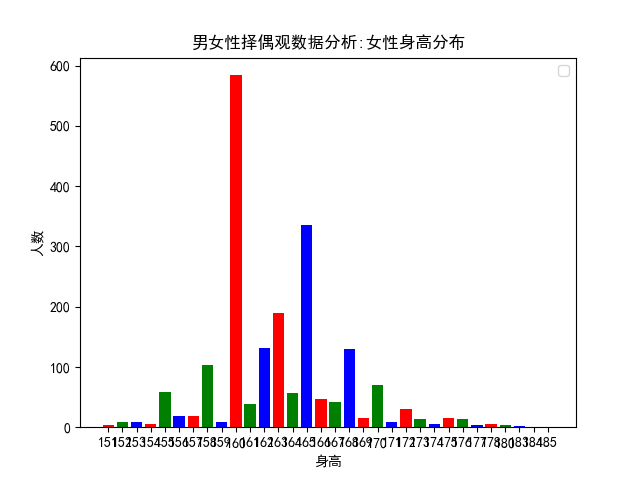
身高分佈
身高分佈,同樣採用關鍵字匹配的方式實現,不同的是,擇偶者通常會在微博中給出自己的身高以及對伴侶期望的身高,由此我們對微博中的身高進行了提取,分別獲得了男性、女性身高分佈及其身高差分佈。這是我最開始研究這個問題的初衷,現在的結果印證了當時的想法,我內心其實是特別開心的,這正是為什麼要花時間和精力寫這篇文章的原因所在。這裡,相關的程式碼實現如下:
# 身高分佈
def analyseHeight():
heights = []
rows = loadData()
pattern = re.compile(r'1\d{2}|\d{1}\.\d{1,2}|\d{1}\米\d{2}')
for row in rows:
text = row[0].decode('utf-8')
matches = pattern.findall(text)
if(len(matches)>1):
matches = map(lambda x:int(''.join(re.findall(r'\d',x))),matches)
matches = list(filter(lambda x: x<190 and x>150, matches))
if(len(matches)>1):
height = {}
height['male'] = max(matches)
height['female'] = min(matches)
heights.append(height)
# 男性身高分佈
male_heights = list(map(lambda x:x['male'],heights))
male_heights = Counter(male_heights).items()
male_heights = dict(sorted(male_heights,key=lambda x:x[0],reverse = False))
drawing.bar('男女性擇偶觀資料分析:男性身高分佈',male_heights,'身高','人數',None)
# 女性身高分佈
female_heights = list(map(lambda x:x['female'],heights))
female_heights = Counter(female_heights).items()
female_heights = dict(sorted(female_heights,key=lambda x:x[0],reverse = False))
drawing.bar('男女性擇偶觀資料分析:女性身高分佈',female_heights,'身高','人數',None)
# 男女身高差分佈
substract_heights = list(map(lambda x:x['male']-x['female'],heights))
substract_heights = Counter(substract_heights).items()
substract_heights = dict(sorted(substract_heights,key=lambda x:x[0],reverse = False))
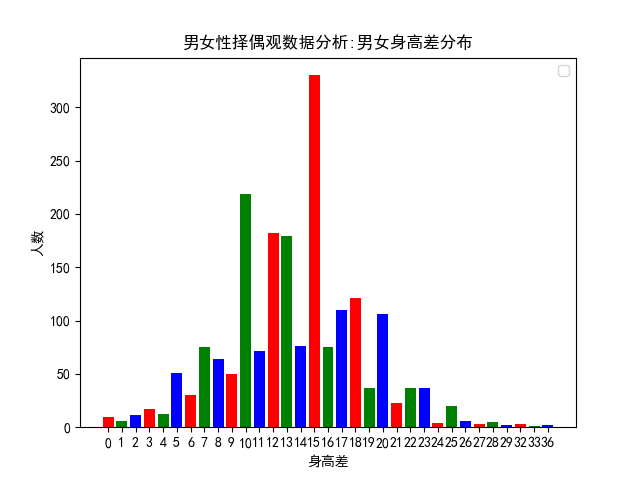
drawing.bar('男女性擇偶觀資料分析:男女身高差分佈',substract_heights,'身高差','人數',None) 雖然女生都希望男生180以上,據說這樣可以舉高高、有安全感,可是作為一個成年人,我們必須勇敢地打破這種不切實際的幻想,因為身高和外貌都是父母給我們的,那些基因裡決定的東西,往往是我們無法通過後天努力來彌補的。如果可以的話,我希望自己再長高5釐米,可如果我再無法長高,我希望你能接受現在的我,接受一個人身高上的缺陷,和接受一個人人性中的缺點,在我看來是一模一樣的。可人類最大的問題, 就在於願意相信自己眼睛看到的,耳朵聽到的,並且這是兩個人建立聯絡的前提,人家願意瞭解你有趣的靈魂,前提是你有一副好看的皮囊,人類啊,說到底是一種比較高階的動物而已,就像動物用皮毛、膚色去吸引同類一樣,如你所見,男生平均身高其實只有175而已!
女性的身高通常不會被作為篩選條件,正如社會群體通常都是對男性提出各種要求一樣,兩個同等條件下的男、女性,人們理所當然地對男性提出了更高的要求,可其實大家都是母親十月懷胎而來,同樣地都在這個世界裡生活了20多年。所以這個世界上有太多地問題,其實都是人們自己造成的。比如女性一定要找一個穿高跟鞋後還要比她高的男性,而男性一定要找一個身高上和他相差不大的女性,男性的身高不足175,同女性的身高不足165一樣,都是人們眼中比較尷尬的身高,可你看這圖表中女性的平均身高是160,那麼,就讓大家一起尷尬吧,不知道當年小平爺爺和拿破崙將軍的夫人心裡是怎麼想的啦!
最初我研究這個問題的時候,我發現微博上有好多身高不足160的女性,要求伴侶期望身高都是175以上,作為一個身高只有170的男生,我感到絕望和悲傷啊,後來和一位朋友聊天,他說他覺得我連170都沒有,我想說人類為什麼要這般奇怪,譬如體重一定要說得比實際輕、身高一定要說得比實際高、年齡一定要說得比實際小……難道這樣不感覺累嗎?那麼到底有多少人希望兩個人的身高差超過20釐米呢?網路上流傳的所謂最萌身高差到底萌不萌呢?你看孟德爾通過豌豆雜交試驗來研究遺傳問題,兩個身高差超過20釐米的人的後代,平均下來難道不是隻有170嗎?圖表表明,男女性之間最佳的身高差是15釐米。
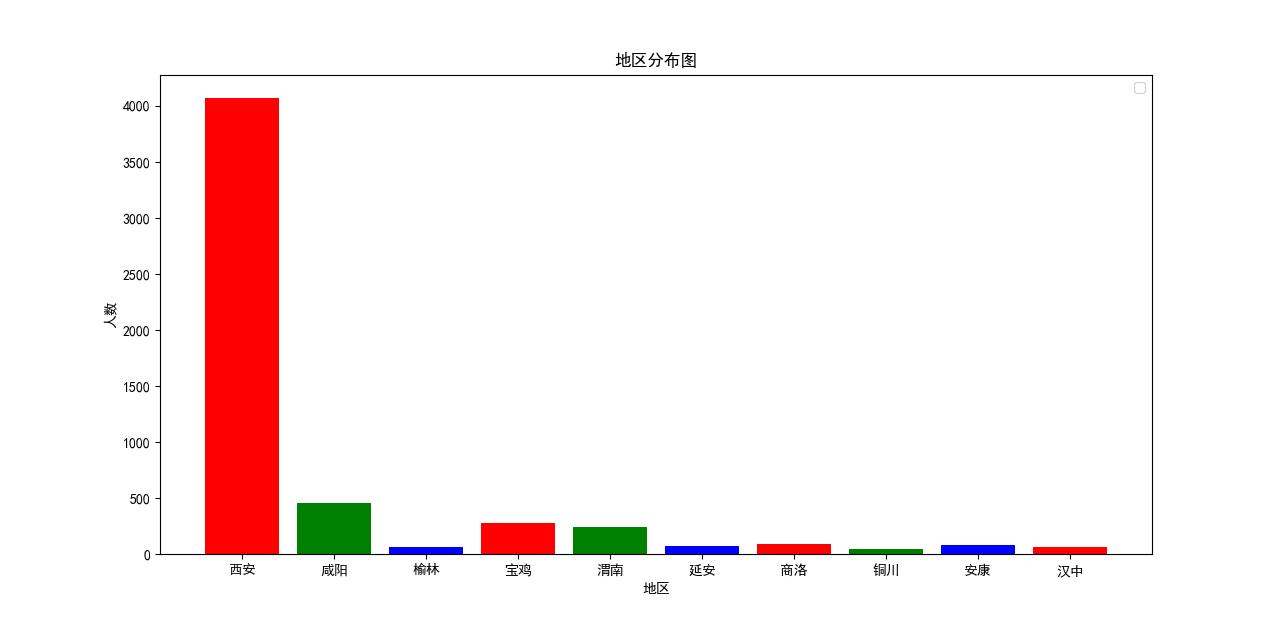
地理分佈
因為在這些微博中會出現相親者的地理資訊,所以我們整理了陝西省各縣市的名稱作為關鍵字,試圖分析出這些相親者的地理分佈,這裡我們簡單繪製了一個柱形圖,相關程式碼實現如下:
# 地區分析
def anslyseLocation():
freqs = { }
citys = [u'西安',u'銅川',u'寶雞',u'咸陽',u'渭南',u'延安',u'漢中',u'榆林',u'安康',u'商洛']
rows = loadData()
for row in rows:
text = row[0].decode('utf-8')
for city in citys:
if(city in text):
if(city in freqs.keys()):
freqs[city]+=1
else:
freqs[city]=1
drawing.bar('地區分佈圖',freqs,'地區','人數',None) 這裡的結果令人齣戲,因為西安作為陝西省的省會城市,在所有地區中一騎絕塵。考慮到在這些微博中”西安”存在干擾,所以這個結果並不是非常嚴謹,不能作為一個有效的分析指標,而且這裡存在同義詞,比如”本地”和”土著”其實都表示西安,而我們統計的時候並沒有考慮這種情況,所以這裡繪製的地區分佈圖表,大家看看就好啦!
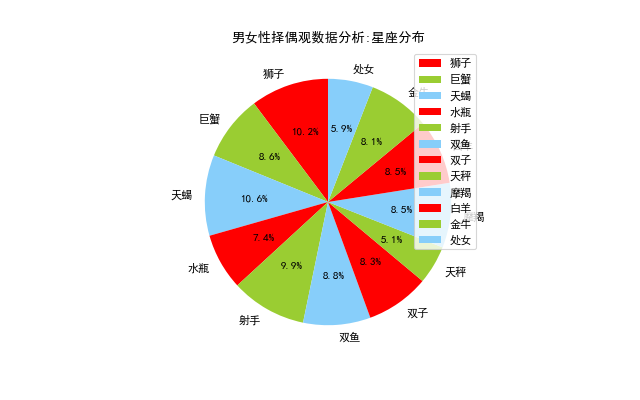
星座分佈
這裡為什麼要分析星座呢?理論上來講,我是不大相信這些東西的,可當你經歷的事情多了以後,你就會下意識地認為這些東西說得很對,我想古代的占卜算卦基本上是同樣的東西,其實世間好多事情之間應該是沒有直接的聯絡的,無非是在千百年的歷史積澱中,逐漸地形成了一套建立在經驗上的理論體系,這就像我們今天所追捧的機器學習,我們有千百年的歷史長河去收集資料,每一個相信這些理論的人都是一個數據樣本,這些理論體系通過不斷地訓練和模擬,逐漸可以正確地預測某些事情,讓我們相信萬事萬物間存在某種聯絡。可即便如此,人類依舊免不了對各種事物存在偏見,比如星座中經常無辜躺槍的處女座、雙子座和天蠍座,人類最擅長的認知方式,就是用一個群體現象來預測個人現象,可諷刺的是樸素貝葉斯就是這樣的思想,所以這裡我們簡單地統計了下各種星座的頻數分佈:
# 星座分析
def analyseStar():
stars = ['白羊','金牛','雙子','巨蟹','獅子','處女','天秤','天蠍','射手','摩羯','水瓶','雙魚']
freqs = {}
rows = loadData()
for row in rows:
text = row[0].decode('utf-8')
for star in stars:
if(star in text):
if(star in freqs.keys()):
freqs[star]+=1
else:
freqs[star]=1
for star in stars:
if(star not in freqs.keys()):
freqs[star] = 0
freqs = Counter(freqs).items()
freqs = dict(freqs)
drawing.pie('男女性擇偶觀資料分析:星座分佈',freqs,None) 這個結果相對客觀些,因為12個星座基本上平分秋色啦,並不存在某種星座獨領風騷的情況,簡直是人與自然的大和諧了呢?
本文小結
這篇文章寫到這裡,我其實已經非常疲憊啦,因為這篇文章的上篇與下篇中間相隔了差不多三個月,而且我寫作上篇的時候,並沒有打算寫這一篇文章出來,再者兩篇文章寫作時的心境完全不同,所以現在寫完這篇文章,終於有種如釋重負的感覺,一來沒有因拖延症而放棄這篇文章,二來為了瞭解相關的理論以及訓練資料花費大量精力,我必須對自己的過去有一個總結,這是我今年年初給自己制定的目標,不管有沒有喜歡我,我總要去做這些事情,不是因為我想要證明什麼或者做給誰看,而是我認為這件事情比某些事情有趣而且重要。這篇文章首先承接上文,交待故事的背景,即為什麼要做這樣的資料分析;然後我們簡單介紹了文字分類的常用的技術方法,主要以特徵工程和分類器為主;接下來我們介紹了兩個經典的理論:tf-idf和樸素貝葉斯,這是本文文字分類的理論基礎;在資料分析這部分,我們對特徵、年齡、性別、身高、地區和星座等進行了分析,並藉助Python中的圖表模組完成了資料的視覺化工作。好啦,以上就是這篇文章的全部內容啦,歡迎大家積極留言和評論,晚安!