
微信公眾號批量爬取——Java版
最近需要爬取微信公眾號的文章資訊。在網上找了找發現微信公眾號爬取的難點在於公眾號文章連結在pc端是打不開的,要用微信的自帶瀏覽器(拿到微信客戶端補充的引數,才可以在其它平臺開啟),這就給爬蟲程式造成很大困擾。後來在知乎上看到了一位大牛用php寫的微信公眾號爬取程式,就直接按大佬的思路整了整搞成java的了。改造途中遇到蠻多細節問題,拿出來分享一下。
附上大牛文章連結:https://zhuanlan.zhihu.com/c_65943221 寫php的或者只需要爬取思路的可以直接看這個,思路寫的非常詳細。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
系統的基本思路是在安卓模擬器上執行微信,模擬器設定代理,通過代理伺服器攔截微信資料,將得到的資料傳送給自己的程式進行處理。
需要準備的環境:nodejs,anyproxy代理,安卓模擬器
nodejs下載地址:http://nodejs.cn/download/,我下載的是windows版的,下好直接安裝就行。安裝好後,直接執行C:\Program Files\nodejs\npm.cmd 會自動配置好環境。
anyproxy安裝:按上一步安裝好nodejs之後,直接在cmd執行 npm install -g anyproxy 就會安裝了
安卓模擬器隨便在網上下一個就好了,一大堆。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
首先為代理伺服器安裝證書,anyproxy預設不解析https連結,安裝證書後就可以解析了,在cmd執行anyproxy --root 就會安裝證書,之後還得在模擬器也下載這個證書。
然後輸入anyproxy -i 命令 開啟代理服務。(記得加上引數!)

記住這個ip和埠,之後安卓模擬器的代理就用這個。現在用瀏覽器開啟網頁:http://localhost:8002/ 這是anyproxy的網頁介面,用於顯示http傳輸資料。
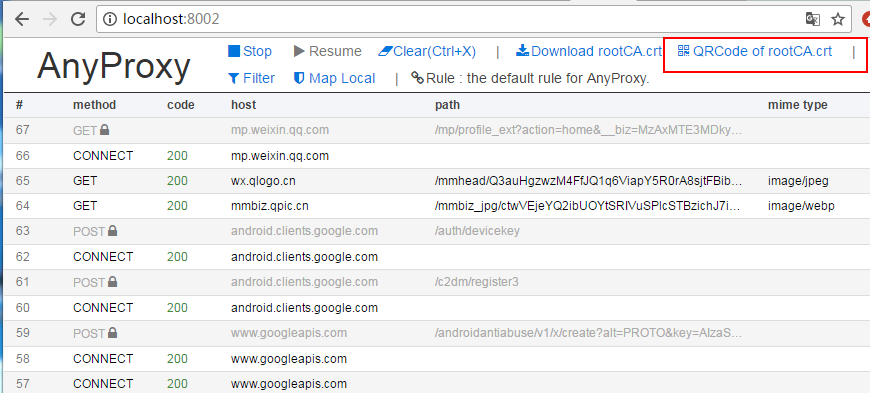
點選上面紅框框裡面的選單,會出一個二維碼,用安卓模擬器掃碼識別,模擬器(手機)就會下載證書了,安裝上就好了。
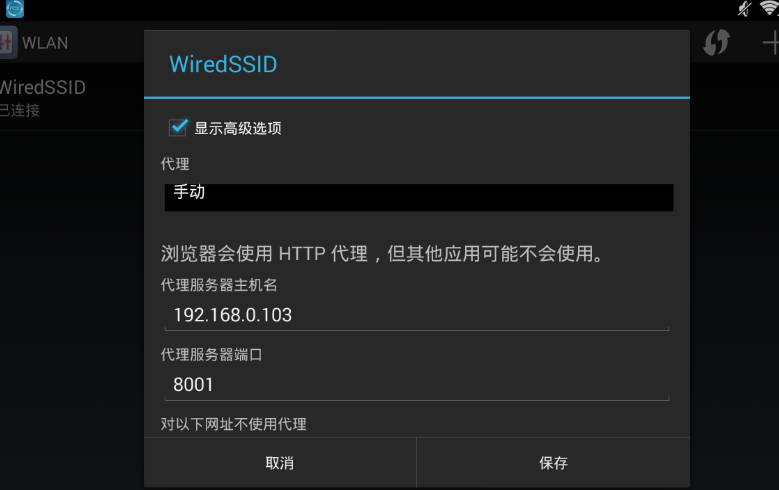
現在準備為模擬器設定代理,代理方式設定為手動,代理ip為執行anyproxy機器的ip,埠是8001
到這裡準備工作基本完成,在模擬器上開啟微信隨便開啟一個公眾號的文章,就能從你剛開啟的web介面中看到anyproxy抓取到的資料:
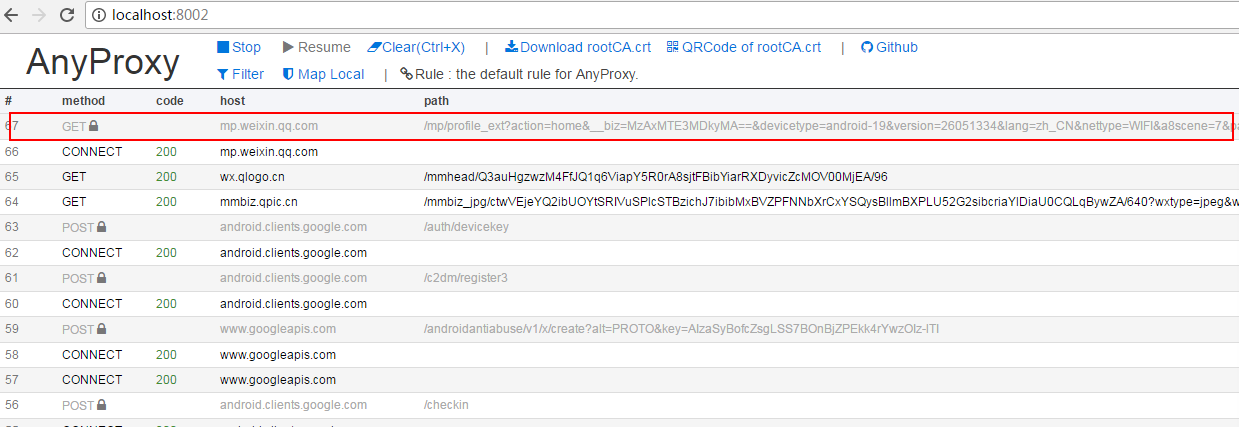
上面紅框內就是微信文章的連結,點選進去可以看到具體的資料。如果response body裡面什麼都沒有可能證書安裝有問題。
如果上面都走通了,就可以接著往下走了。
這裡我們靠代理服務抓微信資料,但總不能抓取一條資料就自己操作一下微信,那樣還不如直接人工複製。所以我們需要微信客戶端自己跳轉頁面。這時就可以使用anyproxy攔截微信伺服器返回的資料,往裡面注入頁面跳轉程式碼,再把加工的資料返回給模擬器實現微信客戶端自動跳轉。
開啟anyproxy中的一個叫rule_default.js的js檔案,windows下該檔案在:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
在檔案裡面有個叫replaceServerResDataAsync: function(req,res,serverResData,callback)的方法,這個方法就是負責對anyproxy拿到的資料進行各種操作。一開始應該只有callback(serverResData);這條語句的意思是直接返回伺服器響應資料給客戶端。直接刪掉這條語句,替換成大牛寫的如下程式碼。這裡的程式碼我並沒有做什麼改動,裡面的註釋也解釋的給非常清楚,直接按邏輯看懂就行,問題不大。

1 replaceServerResDataAsync: function(req,res,serverResData,callback){ 2 if(/mp\/getmasssendmsg/i.test(req.url)){//當連結地址為公眾號歷史訊息頁面時(第一種頁面形式) 3 //console.log("開始第一種頁面爬取"); 4 if(serverResData.toString() !== ""){ 5 6 try {//防止報錯退出程式 7 var reg = /msgList = (.*?);/;//定義歷史訊息正則匹配規則 8 var ret = reg.exec(serverResData.toString());//轉換變數為string 9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//這個函式是後文定義的,將匹配到的歷史訊息json傳送到自己的伺服器 10 var http = require('http'); 11 http.get('http://xxx/getWxHis', function(res) {//這個地址是自己伺服器上的一個程式,目的是為了獲取到下一個連結地址,將地址放在一個js指令碼中,將頁面自動跳轉到下一頁。後文將介紹getWxHis.php的原理。 12 res.on('data', function(chunk){ 13 callback(chunk+serverResData);//將返回的程式碼插入到歷史訊息頁面中,並返回顯示出來 14 }) 15 }); 16 }catch(e){//如果上面的正則沒有匹配到,那麼這個頁面內容可能是公眾號歷史訊息頁面向下翻動的第二頁,因為歷史訊息第一頁是html格式的,第二頁就是json格式的。 17 //console.log("開始第一種頁面爬取向下翻形式"); 18 try { 19 var json = JSON.parse(serverResData.toString()); 20 if (json.general_msg_list != []) { 21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//這個函式和上面的一樣是後文定義的,將第二頁歷史訊息的json傳送到自己的伺服器 22 } 23 }catch(e){ 24 console.log(e);//錯誤捕捉 25 } 26 callback(serverResData);//直接返回第二頁json內容 27 } 28 } 29 //console.log("開始第一種頁面爬取 結束"); 30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//當連結地址為公眾號歷史訊息頁面時(第二種頁面形式) 31 try { 32 var reg = /var msgList = \'(.*?)\';/;//定義歷史訊息正則匹配規則(和第一種頁面形式的正則不同) 33 var ret = reg.exec(serverResData.toString());//轉換變數為string 34 HttpPost(ret[1],req.url,"/xxx/showBiz");//這個函式是後文定義的,將匹配到的歷史訊息json傳送到自己的伺服器 35 var http = require('http'); 36 http.get('xxx/getWxHis', function(res) {//這個地址是自己伺服器上的一個程式,目的是為了獲取到下一個連結地址,將地址放在一個js指令碼中,將頁面自動跳轉到下一頁。後文將介紹getWxHis.php的原理。 37 res.on('data', function(chunk){ 38 callback(chunk+serverResData);//將返回的程式碼插入到歷史訊息頁面中,並返回顯示出來 39 }) 40 }); 41 }catch(e){ 42 //console.log(e); 43 callback(serverResData); 44 } 45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二種頁面表現形式的向下翻頁後的json 46 try { 47 var json = JSON.parse(serverResData.toString()); 48 if (json.general_msg_list != []) { 49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//這個函式和上面的一樣是後文定義的,將第二頁歷史訊息的json傳送到自己的伺服器 50 } 51 }catch(e){ 52 console.log(e); 53 } 54 callback(serverResData); 55 }else if(/mp\/getappmsgext/i.test(req.url)){//當連結地址為公眾號文章閱讀量和點贊量時 56 try { 57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函式是後文定義的,功能是將文章閱讀量點贊量的json傳送到伺服器 58 }catch(e){ 59 60 } 61 callback(serverResData); 62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//當連結地址為公眾號文章時(rumor這個地址是公眾號文章被闢謠了) 63 try { 64 var http = require('http'); 65 http.get('http://xxx/getWxPost', function(res) {//這個地址是自己伺服器上的另一個程式,目的是為了獲取到下一個連結地址,將地址放在一個js指令碼中,將頁面自動跳轉到下一頁。後文將介紹getWxPost.php的原理。 66 res.on('data', function(chunk){ 67 callback(chunk+serverResData); 68 }) 69 }); 70 }catch(e){ 71 callback(serverResData); 72 } 73 }else{ 74 callback(serverResData); 75 } 76 //callback(serverResData); 77 },
這裡簡單解釋一下,微信公眾號的歷史訊息頁連結有兩種形式:一種以 mp.weixin.qq.com/mp/getmasssendmsg 開頭,另一種是 mp.weixin.qq.com/mp/profile_ext 開頭。歷史頁是可以向下翻的,如果向下翻將觸發js事件傳送請求得到json資料(下一頁內容)。還有公眾號文章連結,以及文章的閱讀量和點贊量的連結(返回的是json資料),這幾種連結的形式是固定的可以通過邏輯判斷來區分。這裡有個問題就是歷史頁如果需要全部爬取到該怎麼做到。我的思路是通過js去模擬滑鼠向下滑動,從而觸發提交載入下一部分列表的請求。或者直接利用anyproxy分析下滑載入的請求,直接向微信伺服器發生這個請求。但都有一個問題就是如何判斷已經沒有餘下資料了。我是爬取最新資料,暫時沒這個需求,可能以後要。如果有需求的可以嘗試一下。
下圖是上文中的HttpPost方法內容。
1 function HttpPost(str,url,path) {//將json傳送到伺服器,str為json內容,url為歷史訊息頁面地址,path是接收程式的路徑和檔名 2 console.log("開始執行轉發操作"); 3 try{ 4 var http = require('http'); 5 var data = { 6 str: encodeURIComponent(str), 7 url: encodeURIComponent(url) 8 }; 9 data = require('querystring').stringify(data); 10 var options = { 11 method: "POST", 12 host: "xxx",//注意沒有http://,這是伺服器的域名。 13 port: xxx, 14 path: path,//接收程式的路徑和檔名 15 headers: { 16 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 17 "Content-Length": data.length 18 } 19 }; 20 var req = http.request(options, function (res) { 21 res.setEncoding('utf8'); 22 res.on('data', function (chunk) { 23 console.log('BODY: ' + chunk); 24 }); 25 }); 26 req.on('error', function (e) { 27 console.log('problem with request: ' + e.message); 28 }); 29 30 req.write(data); 31 req.end(); 32 }catch(e){ 33 console.log("錯誤資訊:"+e); 34 } 35 console.log("轉發操作結束"); 36 }
做完以上工作,接下來就是按自己業務來完成服務端程式碼了,我們的服務用於接收代理伺服器發過來的資料進行處理,進行持久化操作,同時向代理伺服器傳送需要注入到微信的js程式碼。針對代理伺服器攔截到的幾種不同連結發來的資料,我們就需要設計相應的方法來處理這些資料。從anyproxy處理微信資料的js方法replaceServerResDataAsync: function(req,res,serverResData,callback)中,我們可以知道至少需要對公眾號歷史頁資料、公眾號文章頁資料、公眾號文章點贊量和閱讀量資料設計三種方法來處理。同時我們還需要設計一個方法來生成爬取任務,完成公眾號的輪尋爬取。如果需要爬取更多資料,可以從anyproxy抓取到的連結中分析出更多需要的資料,然後往replaceServerResDataAsync: function(req,res,serverResData,callback)中新增判定,攔截到需要的資料傳送到自己的伺服器,相應的在服務端新增方法處理該類資料就行了。
我是用java寫的服務端程式碼。
處理公眾號歷史頁資料方法:
public void getMsgJson(String str ,String url) throws UnsupportedEncodingException { // TODO Auto-generated method stub String biz = ""; Map<String,String> queryStrs = HttpUrlParser.parseUrl(url); if(queryStrs != null){ biz = queryStrs.get("__biz"); biz = biz + "=="; } /** * 從資料庫中查詢biz是否已經存在,如果不存在則插入, * 這代表著我們新添加了一個採集目標公眾號。 */ List<WeiXin> results = weiXinMapper.selectByBiz(biz); if(results == null || results.size() == 0){ WeiXin weiXin = new WeiXin(); weiXin.setBiz(biz); weiXin.setCollect(System.currentTimeMillis()); weiXinMapper.insert(weiXin); } //System.out.println(str); //解析str變數 List<Object> lists = JsonPath.read(str, "['list']"); for(Object list : lists){ Object json = list; int type = JsonPath.read(json, "['comm_msg_info']['type']"); if(type == 49){//type=49表示是圖文訊息 String content_url = JsonPath.read(json, "$.app_msg_ext_info.content_url"); content_url = content_url.replace("\\", "").replaceAll("amp;", "");//獲得圖文訊息的連結地址 int is_multi = JsonPath.read(json, "$.app_msg_ext_info.is_multi");//是否是多圖文訊息 Integer datetime = JsonPath.read(json, "$.comm_msg_info.datetime");//圖文訊息傳送時間 /** * 在這裡將圖文訊息連結地址插入到採集佇列庫tmplist中 * (佇列庫將在後文介紹,主要目的是建立一個批量採集佇列, * 另一個程式將根據佇列安排下一個採集的公眾號或者文章內容) */ try{ if(content_url != null && !"".equals(content_url)){ TmpList tmpList = new TmpList(); tmpList.setContentUrl(content_url); tmpListMapper.insertSelective(tmpList); } }catch(Exception e){ System.out.println("佇列已存在,不插入!"); } /** * 在這裡根據$content_url從資料庫post中判斷一下是否重複 */ List<Post> postList = postMapper.selectByContentUrl(content_url); boolean contentUrlExist = false; if(postList != null && postList.size() != 0){ contentUrlExist = true; } if(!contentUrlExist){//'資料庫post中不存在相同的$content_url' Integer fileid = JsonPath.read(json, "$.app_msg_ext_info.fileid");//一個微信給的id String title = JsonPath.read(json, "$.app_msg_ext_info.title");//文章標題 String title_encode = URLEncoder.encode(title, "utf-8"); String digest = JsonPath.read(json, "$.app_msg_ext_info.digest");//文章摘要 String source_url = JsonPath.read(json, "$.app_msg_ext_info.source_url");//閱讀原文的連結 source_url = source_url.replace("\\", ""); String cover = JsonPath.read(json, "$.app_msg_ext_info.cover");//封面圖片 cover = cover.replace("\\", ""); /** * 存入資料庫 */ // System.out.println("頭條標題:"+title); // System.out.println("微信ID:"+fileid); // System.out.println("文章摘要:"+digest); // System.out.println("閱讀原文連結:"+source_url); // System.out.println("封面圖片地址:"+cover); Post post = new Post(); post.setBiz(biz); post.setTitle(title); post.setTitleEncode(title_encode); post.setFieldId(fileid); post.setDigest(digest); post.setSourceUrl(source_url); post.setCover(cover); post.setIsTop(1);//標記一下是頭條內容 post.setIsMulti(is_multi); post.setDatetime(datetime); post.setContentUrl(content_url); postMapper.insert(post); } if(is_multi == 1){//如果是多圖文訊息 List<Object> multiLists = JsonPath.read(json, "['app_msg_ext_info']['multi_app_msg_item_list']"); for(Object multiList : multiLists){ Object multiJson = multiList; content_url = JsonPath.read(multiJson, "['content_url']").toString().replace("\\", "").replaceAll("amp;", "");//圖文訊息連結地址 /** * 這裡再次根據$content_url判斷一下資料庫中是否重複以免出錯 */ contentUrlExist = false; List<Post> posts = postMapper.selectByContentUrl(content_url); if(posts != null && posts.size() != 0){ contentUrlExist = true; } if(!contentUrlExist){//'資料庫中不存在相同的$content_url' /** * 在這裡將圖文訊息連結地址插入到採集佇列庫中 * (佇列庫將在後文介紹,主要目的是建立一個批量採集佇列, * 另一個程式將根據佇列安排下一個採集的公眾號或者文章內容) */ if(content_url != null && !"".equals(content_url)){ TmpList tmpListT = new TmpList(); tmpListT.setContentUrl(content_url); tmpListMapper.insertSelective(tmpListT); } String title = JsonPath.read(multiJson, "$.title"); String title_encode = URLEncoder.encode(title, "utf-8"); Integer fileid = JsonPath.read(multiJson, "$.fileid"); String digest = JsonPath.read(multiJson, "$.digest"); String source_url = JsonPath.read(multiJson, "$.source_url"); source_url = source_url.replace("\\", ""); String cover = JsonPath.read(multiJson, "$.cover"); cover = cover.replace("\\", ""); // System.out.println("標題:"+title); // System.out.println("微信ID:"+fileid); // System.out.println("文章摘要:"+digest); // System.out.println("閱讀原文連結:"+source_url); // System.out.println("封面圖片地址:"+cover); Post post = new Post(); post.setBiz(biz); post.setTitle(title); post.setTitleEncode(title_encode); post.setFieldId(fileid); post.setDigest(digest); post.setSourceUrl(source_url); post.setCover(cover); post.setIsTop(0);//標記一下不是頭條內容 post.setIsMulti(is_multi); post.setDatetime(datetime); post.setContentUrl(content_url); postMapper.insert(post); } } } } } }
處理公眾號文章頁的方法:
public String getWxPost() { // TODO Auto-generated method stub /** * 當前頁面為公眾號文章頁面時,讀取這個程式 * 首先刪除採集隊列表中load=1的行 * 然後從隊列表中按照“order by id asc”選擇多行(注意這一行和上面的程式不一樣) */ tmpListMapper.deleteByLoad(1); List<TmpList> queues = tmpListMapper.selectMany(5); String url = ""; if(queues != null && queues.size() != 0 && queues.size() > 1){ TmpList queue = queues.get(0); url = queue.getContentUrl(); queue.setIsload(1); int result = tmpListMapper.updateByPrimaryKey(queue); System.out.println("update result:"+result); }else{ System.out.println("getpost queues is null?"+queues==null?null:queues.size()); WeiXin weiXin = weiXinMapper.selectOne(); String biz = weiXin.getBiz(); if((Math.random()>0.5?1:0) == 1){ url = "http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=" + biz + "#wechat_webview_type=1&wechat_redirect";//拼接公眾號歷史訊息url地址(第一種頁面形式) }else{ url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz + "#wechat_redirect";//拼接公眾號歷史訊息url地址(第二種頁面形式) } url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz + "#wechat_redirect";//拼接公眾號歷史訊息url地址(第二種頁面形式) //更新剛才提到的公眾號表中的採集時間time欄位為當前時間戳。 weiXin.setCollect(System.currentTimeMillis()); int result = weiXinMapper.updateByPrimaryKey(weiXin); System.out.println("getPost weiXin updateResult:"+result); } int randomTime = new Random().nextInt(3) + 3; String jsCode = "<script>setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");</script>"; return jsCode; }
處理公眾號點贊量和閱讀量的方法:
public void getMsgExt(String str,String url) { // TODO Auto-generated method stub String biz = ""; String sn = ""; Map<String,String> queryStrs = HttpUrlParser.parseUrl(url); if(queryStrs != null){ biz = queryStrs.get("__biz"); biz = biz + "=="; sn = queryStrs.get("sn"); sn = "%" + sn + "%"; } /** * $sql = "select * from `文章表` where `biz`='".$biz."' * and `content_url` like '%".$sn."%'" limit 0,1; * 根據biz和sn找到對應的文章 */ Post post = postMapper.selectByBizAndSn(biz, sn); if(post == null){ System.out.println("biz:"+biz); System.out.println("sn:"+sn); tmpListMapper.deleteByLoad(1); return; } // System.out.println("json資料:"+str); Integer read_num; Integer like_num; try{ read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//閱讀量 like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//點贊量 }catch(Exception e){ read_num = 123;//閱讀量 like_num = 321;//點贊量 System.out.println("read_num:"+read_num); System.out.println("like_num:"+相關推薦
微信公眾號批量爬取——Java版
最近需要爬取微信公眾號的文章資訊。在網上找了找發現微信公眾號爬取的難點在於公眾號文章連結在pc端是打不開的,要用微信的自帶瀏覽器(拿到微信客戶端補充的引數,才可以在其它平臺開啟),這就給爬蟲程式造成很大困擾。後來在知乎上看到了一位大牛用php寫的微信公眾號爬取程式,就直接按大佬的思路整了整搞成java的了。
微信文章抓取:微信公眾號文章抓取常識之臨時連結、永久連結
未經允許請勿轉載 曾經嘗試過抓取微信文章的小夥伴,一定很熟悉搜狗微信。搜狗微信是騰訊官方提供的搜尋引擎,專門用來搜尋微信公眾號發表的文章(不包含服務號)。 對於想要獲取微信文章進行研究學習的小夥伴,首先探索的途徑通常是搜狗微信。那麼關於搜狗微信以及微信相關的抓取,需
微信公眾號支付/退款(java環境)開發介紹
開發之前翻閱了很多帖子,結合自己的實際開發情況,將微信支付/退款 流程以及code貼出,希望通過這一篇帖子就能解決你的問題,有不清楚的直接留言,我會及時回覆(ง •̀_•́)ง 一些說明:xxxUtils為工具類,Constant為常量類 為方便開發,所用和微信支付相關co
python3.6 微信公眾號抓爬
專案介紹 本專案針對微信公眾號文章爬取,通過微信公眾號名稱或微訊號,爬取釋出的文章,並對文章進行去重操作 若有其他問題請加群943841699,共同探討技術 本專案借鑑很多其他專案,就不一一列出 原始碼地址 https://gitee.com/xywdy/wechat_c
關於微信公眾號文章抓取
今天公司要我抓取微信公眾號文章,我百度了半天得到的方法有三種: 具體內容我就不復制了請去下面這個連結去看,寫的挺好 微信公眾號文章採集方案 在三者中我選擇了比較穩妥的第二種:對手機微信進行中間人攻擊 因為之前被封過小號,所以感覺解封微信太麻煩 而關於如何中間人攻擊請參考下面的連結
微信公眾號開發的全過程---Java
按照慣例,開頭總得寫點感想 ------------------------------------------------------------------ 業務流程 這個微信官網說的還是很詳細的,還配了圖。我還要再說一遍。 使用者點選一個支付按鈕-->
微信公眾號授權登入(java實現)
步驟: 1、 使用第三方工具,生成內網對映 2、 微信公眾平臺使用測試賬號 3、 測試賬號中需要配置自己的域名,並關注該臨時測試使用的公眾號 4、 下載一個瀏覽器的二維碼外掛 4、 編碼測試 使用花生殼進行內網穿透 注意,因為我使用的是808
搜狗微信公眾號文章抓取
機器能做的事就別讓人來做! 目標: 抓取特定微信公眾號文章 思路:利用selenium模擬瀏覽器行為,進行抓取(理由:搜狗已將文章連結進行處理,且頁面為動態生成) 框架: 步驟: 1、登入搜狗 a、找到登入按鈕並點選 self.browser.
微信公眾號支付開發全過程----JAVA
1、生成統一下單介面,獲取prepay_id.需要的引數 ==名稱==從哪裡找到他們:微信官方給了個引數的詳細說明。https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=9_1 部分引數,仍然不知道哪裡找的小夥伴們請繼續向下看appid ==應用ID
微信公眾平臺授權登入(java版)
微信公眾平臺授權登入獲取使用者openid。 微信公眾平臺地址:https://mp.weixin.qq.com/ 微信平臺配置: 2、修改配置 2.1 業務域名配置 JS介面安全域名、網頁授權域名 同理操作就可以了,正常操作業務域名就完成了,剩下兩個步驟直
【微信公眾平臺】微信公眾號“一鍵關注”Android版實現
微信公眾平臺可以說我是看著他成長起來的,我身邊的朋友也有因為他而翻身奴隸把主做的,但是可惜的是我錯過了最初的機會 ,我是在2013年開始接觸到微信公眾平臺,當時他還只是一個幼崽,開始我一頭栽入其中並不斷的挖掘其中的萬種可能,就像是在沙漠中遇到了綠洲一樣,但是
第三百三十節,web爬蟲講解2—urllib庫爬蟲—實戰爬取搜狗微信公眾號
文章 odin data 模塊 webapi 頭信息 hone 微信 android 第三百三十節,web爬蟲講解2—urllib庫爬蟲—實戰爬取搜狗微信公眾號 封裝模塊 #!/usr/bin/env python # -*- coding: utf-8 -*- impo
微信公眾號的文章爬取有三種方式
runner 思路 class 目標 rdquo 創建時間 利用 歷史 三種 a. 通過微信訂閱號在發布文章,可以查找公眾號的文章,方式見微信鏈接。,閱讀數、點贊數、評論數仍無法抓取。 b. 通過搜狗微信搜索微信公眾號,但是文章篇幅仍然後有限制,點贊、閱讀數、和評論數無法
python 多線程方法爬取微信公眾號文章
微信爬蟲 多線程爬蟲 本文在上一篇基礎上增加多線程處理(http://blog.51cto.com/superleedo/2124494 )執行思路:1,規劃好執行流程,建立兩個執行線程,一個控制線程2,線程1用於獲取url,並寫入urlqueue隊列3,線程2,通過線程1的url獲取文章內容,並保
微信PK10平臺開發與用python爬取微信公眾號文章
網址 谷歌瀏覽器 pytho google http 開發 微信 安裝python rom 本文通過微信提供微信PK10平臺開發[q-21528-76294] 網址diguaym.com 的公眾號文章調用接口,實現爬取公眾號文章的功能。註意事項 1.需要安裝python s
Python爬取微信公眾號歷史文章進行資料分析
思路: 1. 安裝代理AnProxy,在手機端安裝CA證書,啟動代理,設定手機代理; 2. 獲取目標微信公眾號的__biz; 3. 進入微信公眾號的歷史頁面; 4. 使用Monkeyrunner控制滑屏;獲取更多的歷史訊息; 5. 記錄文章標題,摘要,建立時間,創作型別,地
使用anyproxy+安卓模擬器自動爬取微信公眾號資料-包括閱讀數和點贊數
本文並非作者原創,本文來自 zsyoung 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/zsyoung/article/details/78849982?utm_source=copy 在這裡只是把相關步驟清晰明化一下: 1.安裝node.js &n
Python 爬蟲爬取指定微信公眾號文章
該方法是依賴於urllib2庫來完成的,首先你需要安裝好你的python環境,然後安裝urllib2庫 程式的起始方法(返回值是公眾號文章列表): def openUrl(): print("啟動爬蟲,開啟搜狗搜尋微信介面") # 載入頁面 url
【Python爬蟲】爬取微信公眾號文章資訊準備工作
有一天發現我關注了好多微信公眾號,那時就想有沒有什麼辦法能夠將微信公眾號的文章弄下來,而且還想將一些文章的精彩評論一起搞下來。參考了一些文章,通過幾天的研究基本上實現了自己的要求,現在記錄一下自己的一些心得。 整個研究過程如下: 1.瞭解微信公眾號文章連結的組成,歷史文章API組成,單個文章
python爬蟲(17)爬出新高度_抓取微信公眾號文章(selenium+phantomjs)(上)
抓取微信公眾號的文章 一.思路分析 目前所知曉的能夠抓取的方法有: 1、微信APP中微信公眾號文章連結的直接抓取(http://mp.weixin.qq.com/s?__biz=MjM5MzU4ODk2MA==&mid=2735446906&idx=1&am