Python2 Python3 爬取趕集網租房資訊,帶原始碼分析
阿新 • • 發佈:2019-02-18
*之前偶然看了某個騰訊公開課的視訊,寫的爬取趕集網的租房資訊,這幾天突然想起來,於是自己分析了一下趕集網的資訊,然後自己寫了一遍,寫完又用用Python3重寫了一遍.之中也遇見了少許的坑.記一下.算是一個總結.*
python2 爬取趕集網租房資訊與網站分析
- 分析目標網站url
- 尋找目標標籤
- 獲取,並寫入csv檔案
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
URL = 'http://jn.ganji.com/fang1/o{page}p{price}/' Python3 爬取趕集網i租房資訊
要注意的點
- urlparse.urljoin 改為urllib.urlparse.urljoin
# python2
from urlparse import urljoin
# Python3
from urllib.parse import urljoin- Python3中csv對bytes和str兩種型別進行了嚴格區分,open的寫入格式應該進行改變wb->w
- 設定utf8編碼格式
with open('info.csv','w',encoding='utf8') as f :
csv_writer = csv.writer(f,delimiter=',')完整程式碼如下
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import requests
import csv
URL = 'http://jn.ganji.com/fang1/o{page}p{price}/'
# h: house o:page p:price
# http://jn.ganji.com/fang1/tianqiao/b1000e1577/
# jn jinan fang1 zufang tiaoqiao:tianqiaoqu b:begin 1000 e:end start 1755
# fang5 為二手房 zhipin 為 招聘 趕集網的url劃分的都很簡單,時間充足完全可以獲取非常多的資訊
ADDR = 'http://bj.ganji.com/'
start_page =1
end_page = 5
price =1
'''
URL = 'http://jn.ganji.com/fang1/h{huxing}o{page}b{beginPrice}e{endPrice}/'
# 選擇戶型為h1-h5
# 輸入價位為 begin or end
price='b1000e2000'
# 戶型為
'''
# 預設為utf8開啟,否則會以預設編碼GBK寫入
with open('info.csv','w',encoding='utf8') as f :
csv_writer = csv.writer(f,delimiter=',')
print('starting')
while start_page<end_page:
start_page+=1
print('get{0}'.format(URL.format(page = start_page,price=price)))
response = requests.get(URL.format(page = start_page,price=price))
html=BeautifulSoup(response.text,'html.parser')
house_list = html.select('.f-list > .f-list-item > .f-list-item-wrap')
#check house_list
if not house_list:
print('No house_list')
break
for house in house_list:
house_title = house.select('.title > a')[0].string
house_addr = house.select('.address > .area > a')[-1].string
house_price = house.select('.info > .price > .num')[0].string
house_url = urljoin(ADDR, house.select('.title > a ')[0]['href'])
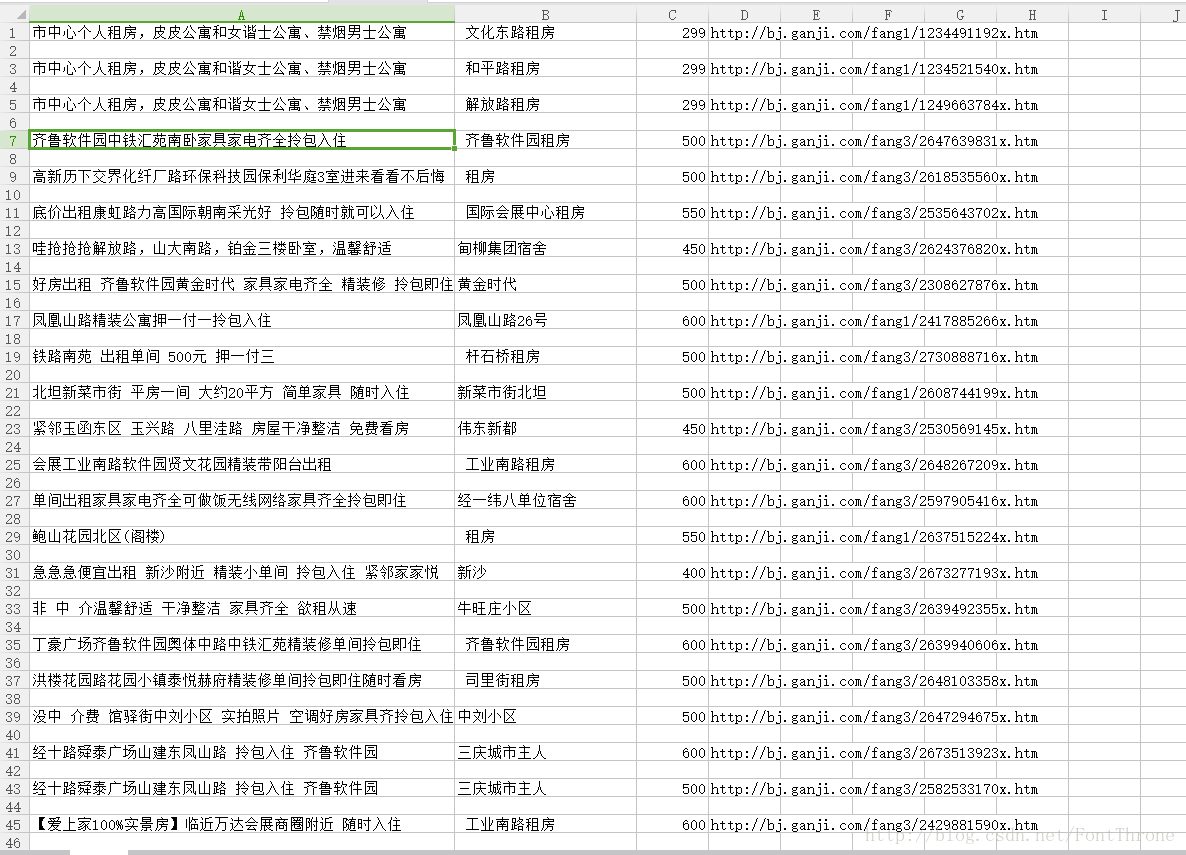
csv_writer.writerow([house_title,house_addr,house_price,house_url])
print('ending')最後的csv檔案展示一下: