(十八)Python爬蟲:XPath的使用
經歷了爬取豆瓣電影TOP250資料我們會發現使用正則表示式其實並沒有多麼方便,有沒有更加好的工具呢?答案當然是有的。接下來將使用三個篇幅分別介紹XPath,Beautiful Soup和pyquery這三個解析庫。
XPath介紹
XPath即為XML路徑語言,它是一種用來確定XML(標準通用標記語言的子集)文件中某部分位置的語言。XPath基於XML的樹狀結構,有不同型別的節點,包括元素節點,屬性節點和文字節點,提供在資料結構樹中找尋節點的能力。 起初 XPath 的提出的初衷是將其作為一個通用的、介於XPointer與XSLT間的語法模型。但是 XPath 很快的被開發者採用來當作小型查詢語言。*[來自360百科]*現在我們使用它對HTML文件進行搜尋。
lxml的安裝
lxml庫是Python的一個解析庫,支援HTML和XML的解析,支援XPath。下面介紹在Windows,Linux和Mac上的安裝。
Windows下的安裝
首先使用命令`pip3 install lxml`進行安裝。如果沒有錯誤資訊說明安裝成功了;如果出現錯誤,比如缺少libxml2庫,使用wheel檔案離線安裝。提供Win64位,Python3.6的lxml安裝包:https://pan.baidu.com/s/1wM1xKxCxOH8QOWclp6iasw。使用命令`pip3 install lxml-4.2.4-cp36-cp36m-win_amd64.whl`進行安裝。Linux下的安裝
- Centos、Red Hat:
yum groupinstall -y development tools
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel
- Ubuntu、Debian和Deepin:
sudo apt-get install -y python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
安裝好這些必要的類庫後重試命令pip3 install lxml進行安裝。
Mac下的安裝
首先也是使用命令`pip3 install lxml`進行安裝。如果沒有錯誤資訊說明安裝成功了。如果報錯一般都是缺少必要的庫,執行命令`xcode-select --install`。再次重試安裝命令。驗證安裝
 如果匯入lxml庫沒有錯誤則證明安裝成功了! ## XPath常用規則 ##| 表示式 | 描述 |
|---|---|
| nodename | 選擇這個節點名的所有子節點 |
| / | 從當前節點選擇直接子節點 |
| // | 從當前節點選取子孫節點 |
| . | 選擇當前節點 |
| … | 選取當前節點的父節點 |
| @ | 選取屬性 |
標籤補全
以下是一段HTML:
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
顯然,這段HTML中的節點沒有閉合,我們可以使用lxml中的etree模組進行補全。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('UTF-8'))
可以看見etree不僅將節點閉合了還添加了其他需要的標籤。

除了直接讀取文字進行解析,etree也可以讀取檔案進行解析。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('UTF-8'))

獲取所有節點
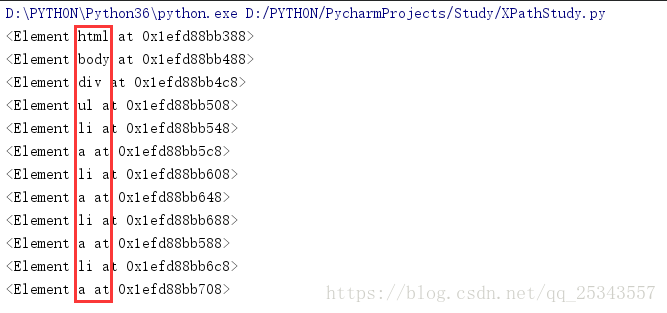
根據XPath常用規則可以知道通過//可以查詢當前節點下的子孫節點,以上面的html為例獲取所有節點。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//*')#'//'表示獲取當前節點子孫節點,'*'表示所有節點,'//*'表示獲取當前節點下所有節點
for item in result:
print(item)
如果我們不要獲取所有節點而是指定獲取某個名稱的節點,只需要將*改為指定節點名稱即可。如獲取所有的li節點
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li')#將*改為li,表示只獲取名稱為li的子孫節點
#返回一個列表
for item in result:
print(item)

獲取子節點
根據XPath常用規則我們可以使用/或//獲取子孫節點或子節點。現在我要獲取li節點下的a節點。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li/a')#//li選擇所有的li節點,/a選擇li節點下的直接子節點a
for item in result:
print(item)
我們也可以使用//ul//a首先選擇所有的ul節點,再獲取ul節點下的的所有a節點,最後結果也是一樣的。但是使用//ul/a就不行了,首先選擇所有的ul節點,再獲取ul節點下的直接子節點a,然而ul節點下沒有直接子節點a,當然獲取不到。需要深刻理解//和/的不同之處。/用於獲取直接子節點,//用於獲取子孫節點。

根據屬性獲取
根據XPath常用規則可以通過@匹配指定的屬性。我們通過class屬性找最後一個li節點。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li[@class="item-3"]')#最後一個li的class屬性值為item-3,返回列表形式
print(result)
獲取父節點
根據XPath常用規則可以通過..獲取當前節點的父節點。現在我要獲取最後一個a節點的父節點下的class屬性。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//a[@href="https://hao.360.cn/?a1004"]/../@class')
#a[@href="https://hao.360.cn/?a1004"]:選擇href屬性為https://hao.360.cn/?a1004的a節點
#..:選取父節點
#@class:選取class屬性,獲取屬性值
print(result)
獲取文字資訊
很多時候我們找到指定的節點都是要獲取節點內的文字資訊。我們使用text()方法獲取節點中的文字。現在獲取所有a標籤的文字資訊。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//ul//a/text()')
print(result)
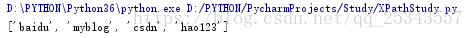
屬性多值匹配
在上面的例子中所有的屬性值都只有一個,如果屬性值有多個還能匹配的上嗎?
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="spitem-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="sp"]')
print(result)
第二個li節點的class屬性有兩個值:sp和item-1。如果我們的xpath匹配規則為//li[@class="sp"]匹配的僅僅是class屬性值只為sp的li節點,這顯然是不存在的。
遇到屬性值有多個的情況我們需要使用contains()函數了,contains()匹配一個屬性值中包含的字串 。包含的字串,而不是某個值。
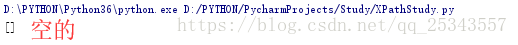
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="sp item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"sp")]/a/text()')
print(result)
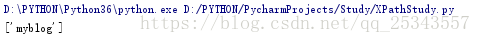
多屬性匹配
屬性多值匹配是節點屬性有許多個值,我們根據一個值獲取符合新增的節點。由於我們很多情況下無法僅僅根據一個屬性值就獲取到目標節點,往往要根據多個屬性來獲取目標節點。
from lxml import etree
text = '''
<div>
<ul>
<li class="sp item-0" name="one"><a href="www.baidu.com">baidu</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"item-0") and @name="one"]/a/text()')#使用and操作符將兩個條件相連。
print(result)
也許你會說這個直接使用name的屬性值就可以得到了,然而,這裡只是作為演示。
下面列出了可用在 XPath 表示式中的運算子:
| 運算子 | 描述 | 例項 | 返回值 |
|---|
如果 price 是 9.80,則返回 true。
如果 price 是 9.90,則返回 false。
!= 不等於 price!=9.80如果 price 是 9.90,則返回 true。
如果 price 是 9.80,則返回 false。
< 小於 price<9.80如果 price 是 9.00,則返回 true。
如果 price 是 9.90,則返回 false。
<= 小於或等於 price<=9.80如果 price 是 9.00,則返回 true。
如果 price 是 9.90,則返回 false。
> 大於 price>9.80如果 price 是 9.90,則返回 true。
如果 price 是 9.80,則返回 false。
>= 大於或等於 price>=9.80如果 price 是 9.90,則返回 true。
如果 price 是 9.70,則返回 false。
or 或 price=9.80 or price=9.70如果 price 是 9.80,則返回 true。
如果 price 是 9.50,則返回 false。
and 與 price>9.00 and price<9.90如果 price 是 9.80,則返回 true。
如果 price 是 8.50,則返回 false。
mod 計算除法的餘數 5 mod 2 1 【上表來源:[w3school 運算子](http://www.w3school.com.cn/xpath/xpath_operators.asp)】根據順序選擇
在上面的操作中我多次找第2個li節點或找最後一個li節點,使用屬性值進行匹配。其實何必呢!我們可以根據順序進行選擇。
from lxml import etree
text = '''
<div>
<ul>
<li class="sp item-0" name="one"><a href="www.baidu.com">baidu</a>
<li class="sp item-1" name="two"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="sp item-2" name="two"><a href="https://www.csdn.net/">csdn</a>
<li class="sp item-3" name="four"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[2]/a/text()')#選擇第二個li節點,獲取a節點的文字
print(result)
result = html.xpath('//li[last()]/a/text()')#選擇最後一個li節點,獲取a節點的文字
print(result)
result = html.xpath('//li[last()-1]/a/text()')#選擇倒數第2個li節點,獲取a節點的文字
print(result)
result = html.xpath('//li[position()<=3]/a/text()')#選擇前三個li節點,獲取a節點的文字
print(result)

我們使用了last()和postion()函式,在XPath中還有很多函式,詳情見:w3school 函式。
XPath 軸
我們可以通過XPath獲取祖先節點,屬性值,兄弟節點等等,這就是XPath的節點軸。軸可定義相對於當前節點的節點集。
| 軸名稱 | 結果 |
|---|---|
| ancestor | 選取當前節點的所有先輩(父、祖父等)。 |
| ancestor-or-self | 選取當前節點的所有先輩(父、祖父等)以及當前節點本身。 |
| attribute | 選取當前節點的所有屬性。 |
| child | 選取當前節點的所有直接子元素。 |
| descendant | 選取當前節點的所有後代元素(子、孫等)。 |
| descendant-or-self | 選取當前節點的所有後代元素(子、孫等)以及當前節點本身。 |
| following | 選取文件中當前節點的結束標籤之後的所有節點。 |
| following-sibling | 選取當前節點之後的所有同級節點。 |
| namespace | 選取當前節點的所有名稱空間節點。 |
| parent | 選取當前節點的父節點。 |
| preceding | 選取文件中當前節點的開始標籤之前的所有同級節點及同級節點下的節點。 |
| preceding-sibling | 選取當前節點之前的所有同級節點。 |
| self | 選取當前節點。 |
使用示例:
from lxml import etree
text = '''
<div>
<ul>
<li class="sp item-0" name="one"><a href="www.baidu.com">baidu</a>
<li class="sp item-1" name="two"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="sp item-2" name="two"><a href="https://www.csdn.net/">csdn</a>
<li class="sp item-3" name="four"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*')#ancestor表示選取當前節點祖先節點,*表示所有節點。合:選擇當前節點的所有祖先節點。
print(result)
result = html.xpath('//li[1]/ancestor::div')#ancestor表示選取當前節點祖先節點,div表示div節點。合:選擇當前節點的div祖先節點。
print(result)
result = html.xpath('//li[1]/ancestor-or-self::*')#ancestor-or-self表示選取當前節點及祖先節點,*表示所有節點。合:選擇當前節點的所有祖先節點及本及本身。
print(result)
result = html.xpath('//li[1]/attribute::*')#attribute表示選取當前節點的所有屬性,*表示所有節點。合:選擇當前節點的所有屬性。
print(result)
result = html.xpath('//li[1]/attribute::name')#attribute表示選取當前節點的所有屬性,name表示name屬性。合:選擇當前節點的name屬性值。
print(result)
result = html.xpath('//ul/child::*')#child表示選取當前節點的所有直接子元素,*表示所有節點。合:選擇ul節點的所有直接子節點。
print(result)
result = html.xpath('//ul/child::li[@name="two"]')#child表示選取當前節點的所有直接子元素,li[@name="two"]表示name屬性值為two的li節點。合:選擇ul節點的所有name屬性值為two的li節點。
print(result)
result = html.xpath('//ul/descendant::*')#descendant表示選取當前節點的所有後代元素(子、孫等),*表示所有節點。合:選擇ul節點的所有子節點。
print(result)
result = html.xpath('//ul/descendant::a/text()')#descendant表示選取當前節點的所有後代元素(子、孫等),a/test()表示a節點的文字內容。合:選擇ul節點的所有a節點的文字內容。
print(result)
result = html.xpath('//li[1]/following::*')#following表示選取文件中當前節點的結束標籤之後的所有節點。,*表示所有節點。合:選擇第一個li節點後的所有節點。
print(result)
result = html.xpath('//li[1]/following-sibling::*')#following-sibling表示選取當前節點之後的所有同級節點。,*表示所有節點。合:選擇第一個li節點後的所有同級節點。
print(result)
result = html.xpath('//li[1]/parent::*')#選取當前節點的父節點。父節點只有一個,祖先節點可能多個。
print(result)
result = html.xpath('//li[3]/preceding::*')#preceding表示選取文件中當前節點的開始標籤之前的所有同級節點及同級節點下的節點。,*表示所有節點。合:選擇第三個li節點前的所有同級節點及同級節點下的子節點。
print(result)
result = html.xpath('//li[3]/preceding-sibling::*')#preceding-sibling表示選取當前節點之前的所有同級節點。,*表示所有節點。合:選擇第三個li節點前的所有同級節點。
print(result)
result = html.xpath('//li[3]/self::*')#選取當前節點。
print(result)

XPath Helper外掛
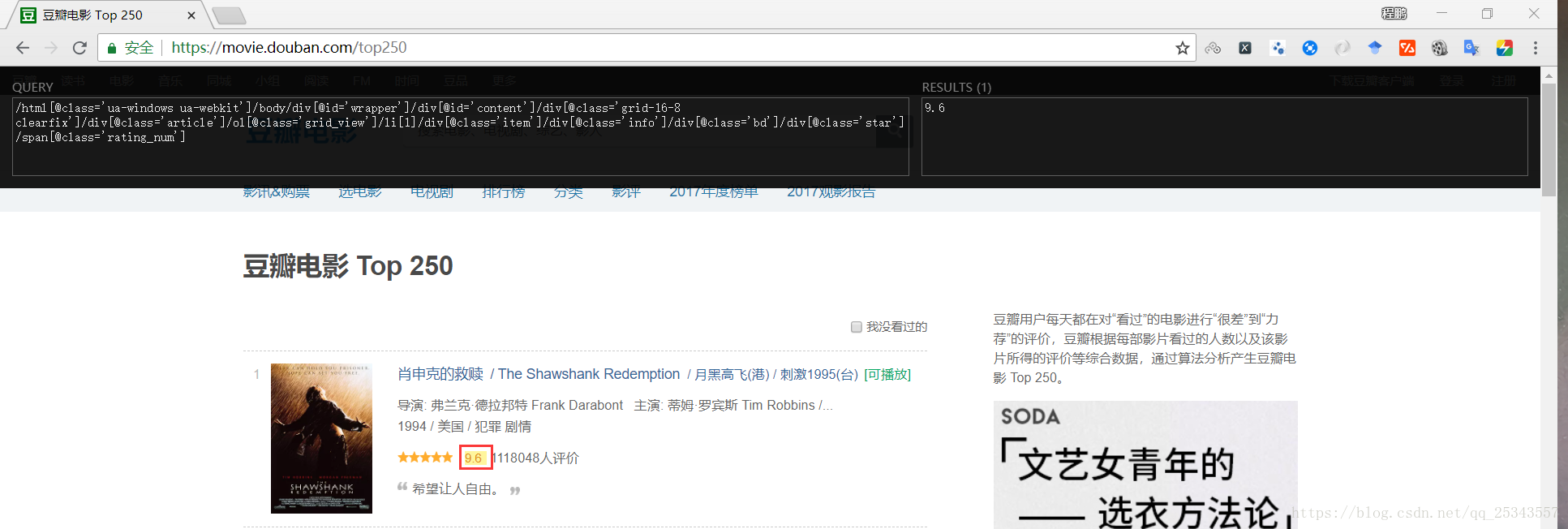
實話說我不想寫XPath的匹配規則,在真正的網頁解析中怎麼可能那麼短的規則。這時候我們就可以使用Chrome的外掛XPath Helper了【下載地址】,使用它我們可以很快速的得到匹配規則。直接將下載下來的crx檔案拖進Chrome擴充套件程式介面安裝即可。
出現紅框內圖示說明安裝成功了。
執行XPath Helper外掛,安裝shift選擇我們需要的內容,自動生成匹配規則。
外掛----讓前面一切“白乾”。_