
Hadoop平臺安全機制Kerberos認證
日前筆者在使用flume採集資料直接入到Hadoop平臺HDFS上時,由於Hadoop平臺採用了Kerberos認證機制。flume配置上是致辭kerberos認證的,但由於flume要採集的節點並不在叢集內,所以需要學習Kerberos在Hadoop上的應用。
1、Kerberos協議
Kerberos協議:
Kerberos協議主要用於計算機網路的身份鑑別(Authentication), 其特點是使用者只需輸入一次身份驗證資訊就可以憑藉此驗證獲得的票據(ticket-granting ticket)訪問多個服務,即SSO(Single Sign On)。由於在每個Client和Service之間建立了共享金鑰,使得該協議具有相當的安全性。
條件
先來看看Kerberos協議的前提條件:
如下圖所示,Client與KDC, KDC與Service 在協議工作前已經有了各自的共享金鑰,並且由於協議中的訊息無法穿透防火牆,這些條件就限制了Kerberos協議往往用於一個組織的內部, 使其應用場景不同於X.509 PKI。
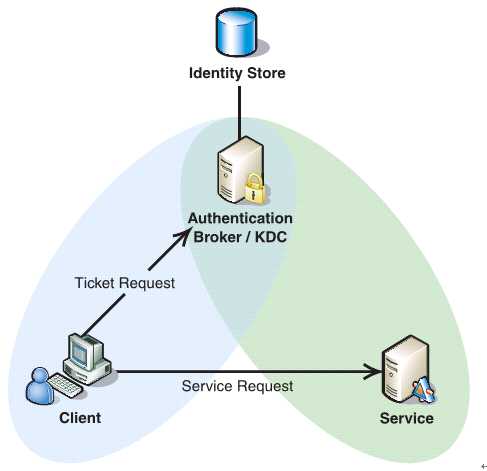
過程
Kerberos協議分為兩個部分:
1 . Client向KDC傳送自己的身份資訊,KDC從Ticket Granting Service得到TGT(ticket-granting ticket), 並用協議開始前Client與KDC之間的金鑰將TGT加密回覆給Client。
此時只有真正的Client才能利用它與KDC之間的金鑰將加密後的TGT解密,從而獲得TGT。
(此過程避免了Client直接向KDC傳送密碼,以求通過驗證的不安全方式)
2. Client利用之前獲得的TGT向KDC請求其他Service的Ticket,從而通過其他Service的身份鑑別。
Kerberos協議的重點在於第二部分,簡介如下:
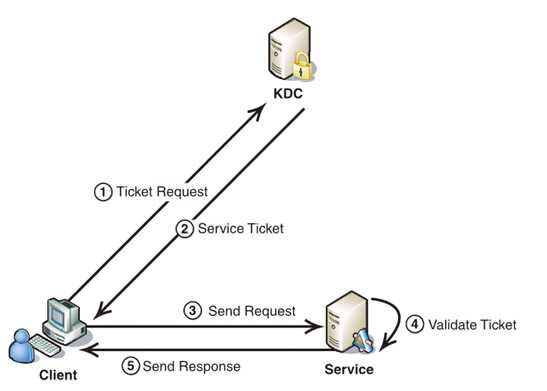
1. Client將之前獲得TGT和要請求的服務資訊(服務名等)傳送給KDC,KDC中的Ticket Granting Service將為Client和Service之間生成一個Session Key用於Service對Client的身份鑑別。然後KDC將這個Session Key和使用者名稱,使用者地址(IP),服務名,有效期, 時間戳一起包裝成一個Ticket(這些資訊最終用於Service對Client的身份鑑別)傳送給Service, 不過Kerberos協議並沒有直接將Ticket傳送給Service,而是通過Client轉發給Service.所以有了第二步。
2. 此時KDC將剛才的Ticket轉發給Client。由於這個Ticket是要給Service的,不能讓Client看到,所以KDC用協議開始前KDC與Service之間的金鑰將Ticket加密後再發送給Client。同時為了讓Client和Service之間共享那個祕密(KDC在第一步為它們建立的Session Key), KDC用Client與它之間的金鑰將Session Key加密隨加密的Ticket一起返回給Client。
3. 為了完成Ticket的傳遞,Client將剛才收到的Ticket轉發到Service. 由於Client不知道KDC與Service之間的金鑰,所以它無法算改Ticket中的資訊。同時Client將收到的Session Key解密出來,然後將自己的使用者名稱,使用者地址(IP)打包成Authenticator用Session Key加密也傳送給Service。
4. Service 收到Ticket後利用它與KDC之間的金鑰將Ticket中的資訊解密出來,從而獲得Session Key和使用者名稱,使用者地址(IP),服務名,有效期。然後再用Session Key將Authenticator解密從而獲得使用者名稱,使用者地址(IP)將其與之前Ticket中解密出來的使用者名稱,使用者地址(IP)做比較從而驗證Client的身份。
5. 如果Service有返回結果,將其返回給Client。
總結
概括起來說Kerberos協議主要做了兩件事
1. Ticket的安全傳遞。
2. Session Key的安全釋出。
再加上時間戳的使用就很大程度上的保證了使用者鑑別的安全性。並且利用Session Key,在通過鑑別之後Client和Service之間傳遞的訊息也可以獲得Confidentiality(機密性), Integrity(完整性)的保證。不過由於沒有使用非對稱金鑰自然也就無法具有抗否認性,這也限制了它的應用。不過相對而言它比X.509 PKI的身份鑑別方式實施起來要簡單多了。
從kerberos協議的基礎原理,在Hadoop上的應用,主要也就是兩個過程,KDC為客戶端上生成TGT,客戶端和服務端通過TGT認證後通訊。
2、Hadoop叢集內應用kerberos認證
Hadoop叢集內部使用Kerberos進行認證

具體的執行過程可以舉例如下:

使用kerberos進行驗證的原因
如此,維護KDC資料庫是應用kerberos協議的基礎。下面就看Hadoop上怎麼增加Kerberos認證。
- 可靠 Hadoop 本身並沒有認證功能和建立使用者組功能,使用依靠外圍的認證系統
- 高效 Kerberos使用對稱鑰匙操作,比SSL的公共金鑰快
- 操作簡單 使用者可以方便進行操作,不需要很複雜的指令。比如廢除一個使用者只需要從Kerbores的KDC資料庫中刪除即可。
3、Hadoop平臺上新增Kerberos認證,首要兩步:
1)第一步自然是部署KDC,並配置KDC伺服器上的相關檔案,其中/etc/krb5.conf要複製到叢集內所有機子,並建立principal資料庫。2)建立認證規則principals和keytab,這個很重要,就是生成每個客戶端相應的祕鑰,Keytab是融合主機和Linux上賬號而生成的,複製keytab到相應節點。
可參考:http://blog.chinaunix.net/uid-1838361-id-3243243.html
4、Hadoop通過kerberos安全認證的分析
Hadoop加入Kerberos認證機制,使得叢集中的節點是信賴的。Kerberos首先通過KDC生成指定節點包含主機和賬號資訊的金鑰,然後將認證的金鑰在叢集部署時事先放到可靠的節點上。叢集執行時,叢集內的節點使用金鑰得到認證,只有被認證過節點才能正常使用。企圖冒充的節點由於沒有事先得到的金鑰資訊,無法與叢集內部的節點通訊。防止了惡意的使用或篡改Hadoop叢集的問題,確保了Hadoop叢集的可靠安全。
1)Hadoop的安全問題
——使用者到伺服器的認證問題
NameNode,,JobTracker上沒有使用者認證
使用者可以偽裝成其他使用者入侵到一個HDFS 或者MapReduce叢集上。
DataNode上沒有認證
Datanode對讀入輸出並沒有認證。導致如果一些客戶端如果知道block的ID,就可以任意的訪問DataNode上block的資料
JobTracker上沒有認證
可以任意的殺死或更改使用者的jobs,可以更改JobTracker的工作狀態
——伺服器到伺服器的認證問題
沒有DataNode, TaskTracker的認證
使用者可以偽裝成datanode ,tasktracker,去接受JobTracker, Namenode的任務指派。
2)Kerberos解決方案
kerberos實現的是機器級別的安全認證,也就是前面提到的服務到服務的認證問題。事先對叢集中確定的機器由管理員手動新增到kerberos資料庫中,在KDC上分別產生主機與各個節點的keytab(包含了host和對應節點的名字,還有他們之間的金鑰),並將這些keytab分發到對應的節點上。通過這些keytab檔案,節點可以從KDC上獲得與目標節點通訊的金鑰,進而被目標節點所認證,提供相應的服務,防止了被冒充的可能性。
——解決伺服器到伺服器的認證
由於kerberos對叢集裡的所有機器都分發了keytab,相互之間使用金鑰進行通訊,確保不會冒充伺服器的情況。叢集中的機器就是它們所宣稱的,是可靠的。
防止了使用者偽裝成Datanode,Tasktracker,去接受JobTracker,Namenode的任務指派。
——解決client到伺服器的認證
Kerberos對可信任的客戶端提供認證,確保他們可以執行作業的相關操作。防止使用者惡意冒充client提交作業的情況。
使用者無法偽裝成其他使用者入侵到一個HDFS 或者MapReduce叢集上
使用者即使知道datanode的相關資訊,也無法讀取HDFS上的資料
使用者無法傳送對於作業的操作到JobTracker上
——對使用者級別上的認證並沒有實現
無法控制使用者提交作業的操作。不能夠實現限制使用者提交作業的許可權。不能控制哪些使用者可以提交該型別的作業,哪些使用者不能提交該型別的作業。這個可以通過ACL來控制,對具體檔案的讀寫訪問進行有效管理。此前筆者對ACL有一個初步的瞭解,見部落格http://blog.csdn.net/fjssharpsword/article/details/51280335
實際上,Hadoop平臺自身也在不斷完善,而對其整合的元件和整體機制瞭解,筆者也在不斷加深,此前的一些錯誤認識也在不斷調整。