
一次 MySQL 索引優化的經歷
專案背景:一個類似雲盤的工具,主伺服器上的 MySQL(InnoDB 引擎) 儲存檔案 MD5 值,客戶端需要在主伺服器上查詢檔案的 MD5 來獲取檔案所在伺服器的 IP 和檔案路徑。
問題:在主伺服器上如何能更快的查詢到檔案對應的 MD5。
下面我們通過實際的資料測試來比較不同情況的效能。
前期準備
生成測試資料
由於實際上沒有很大的資料量,所以很難測試出效能的不同,這裡我用 Java 寫了一個隨機生成 32 位 MD5 值的程式碼以模仿實際情況。
單條值如下:
vkQA87d2a9YB5x51VzRcNoS2pbQr5mjv
package tryCode;
import 生成了 1 w、10 w、50 w 條測試資料分別存入 3 個表中。為簡單起見,表中僅存了主鍵和 MD5 值。
mysql> show tables;
+---------------+
| Tables_in_try |
+---------------+
| MD5 |
| MD5_2 |
| MD5_3 |
+---------------+
3 rows in set (0.00 sec)
mysql> desc MD5;
+-------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+----------------+
| uid | int(32) | NO | PRI | NULL | auto_increment |
| md5 | char(32) | NO | | NULL | |
+-------+----------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
我們看下選擇性:
mysql> select count(distinct md5)/count(*) from MD5;
+------------------------------+
| count(distinct md5)/count(*) |
+------------------------------+
| 1.0000 |
+------------------------------+
1 row in set (0.03 sec)
mysql> select count(distinct md5)/count(*) from MD5_2;
+------------------------------+
| count(distinct md5)/count(*) |
+------------------------------+
| 1.0000 |
+------------------------------+
1 row in set (0.45 sec)
mysql> select count(distinct md5)/count(*) from MD5_3;
+------------------------------+
| count(distinct md5)/count(*) |
+------------------------------+
| 1.0000 |
+------------------------------+
1 row in set (2.95 sec)
選擇性為 1 說明隨機性很好,沒有重複的 MD5 值。
索引的選擇性 = 不重複的索引值 / 資料表的記錄總數
選擇性越高,效能越好。
關閉查詢快取
為了測試資料的準確性,我們關閉查詢快取以避免影響測試結果。
查詢快取也是一個很大的主題,一方面在某些情況下 MySQL 的查詢快取可以極大的提高效能,但另一方面,查詢快取可能成為效能的瓶頸。感興趣可以查閱相關資料:)
修改配置檔案 mysqld.cnf:
我的在 /etc/mysql/mysql.conf.d/下
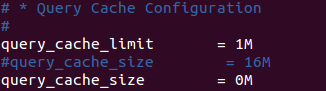
重啟 MySQL
service mysql restart
無自建索引
我們先來看看無自建索引,也就是沒有在資料表上顯式建立索引。這裡我們使用的是 MySQL InnoDB 引擎,關於 InnoDB 引擎的索引相關知識可戳這裡。
在我們沒有顯式指定索引時,MySQL 也會預設幫我們建立索引。因為 MySQL InnoDB 表本身就為一個聚簇索引,預設使用主鍵建立,裡面儲存 B-Tree 和資料行。 注意聚簇索引本身不是一種索引,而是一種資料儲存格式。一張表只能有一個聚簇索引,如下圖:
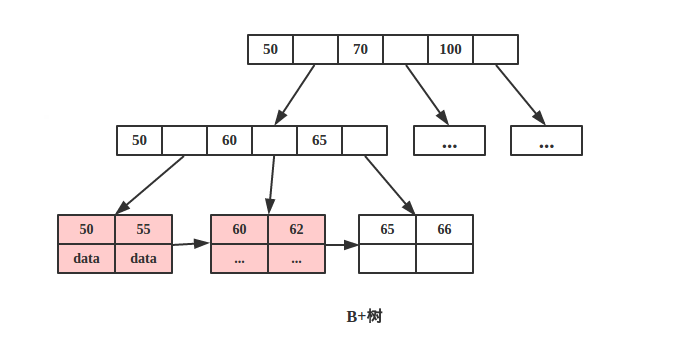
圖中僅有葉子節點儲存 data,非葉子節點儲存 key 的副本。
注意:如果沒有定義主鍵,InooDB 會選擇一個唯一的非空索引代替。如果沒有這樣的索引,InnoDB 會隱式定義一個主鍵為聚簇索引。
主鍵我們一般定義為一個可自增的整型。也就是說預設我們表上的 MD5 欄位是沒有索引的,當查詢某一條 MD5 時,會 掃描全表。通過 EXPLAIN 可以看到。
mysql> explain select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB";
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | MD5_3 | ALL | NULL | NULL | NULL | NULL | 455637 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+--------+-------------+
1 row in set (0.00 sec)
上圖中的 type 是 ALL,說明為全表掃描。
我們來驗證一下,選擇有 50 w 條資料的表,查詢第一條資料和最後一條資料,看看耗時。
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB";
+----------------------------------+
| md5 |
+----------------------------------+
| 5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB |
+----------------------------------+
1 row in set (0.12 sec)
mysql> select md5 from MD5_3 where md5 = "5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9";
+----------------------------------+
| md5 |
+----------------------------------+
| 5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9 |
+----------------------------------+
1 row in set (0.13 sec)結果:第一條資料耗時 0.12 sec,第二條資料耗時 0.13 sec。
基本上耗時相同,咦?不是順序查詢嗎,為什麼第一條和最後一條耗時基本相同。因為 InooDB 預設會掃描全表找出資料而不是查詢到一條就返回。加上 LIMIT 我們來看看。
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" limit 1;
+----------------------------------+
| md5 |
+----------------------------------+
| 5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select md5 from MD5_3 where md5 = "5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9" limit 1;
+----------------------------------+
| md5 |
+----------------------------------+
| 5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9 |
+----------------------------------+
1 row in set (0.12 sec)
加上 LIMIT 我們看到耗時差了很多。第一條資料耗時 0.00 sec,最後一條資料耗時 0.12 sec。
小技巧:當我們需要的資料僅有一行或是唯一的,加上 LIMIT 可以提升效能。
結論:沒有顯式建立索引時,MySQL InnoDB 會掃描全表,查詢的效率是相對低的。
接下來我們顯式建立索引來看看。
自建索引
mysql> create index MD5_3_index on MD5_3(md5);
Query OK, 0 rows affected (3.34 sec)
Records: 0 Duplicates: 0 Warnings: 0通過 EXPLAIN 可以看到 Extra 一欄多了一個 Using index
建立完索引後查詢會預設使用索引:
mysql> select md5 from MD5_3 where md5 = "5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9";
+----------------------------------+
| md5 |
+----------------------------------+
| 5VDUF56jxTF4RQLpRoHybTVc2ZrVmxV9 |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB";
+----------------------------------+
| md5 |
+----------------------------------+
| 5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB |
+----------------------------------+
1 row in set (0.00 sec)
我們看到不管加不加 LIMIT 都是立刻出結果,0.00 sec。
我們通過 profile 來看看精確時間。
開啟 profile:
mysql> set profiling = 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
查詢結果(Query_ID 1.為不建立索引 2.為建立索引):
mysql> show profiles;
+----------+------------+----------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------------------------------+
| 1 | 0.12253700 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 2 | 0.00030075 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
+----------+------------+----------------------------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
我們來計算一下:
0.12253700/0.00030075 = 407.438
50 w 資料顯示建立索引和不建立索引效能差了 400 多倍!由此可見索引的重要性
注:索引帶來的好處可不是這一點點哦:),它還能在高併發的情況下避免死鎖,或者說減少阻塞,因為如果無索引,插入刪除等操作會順序掃描全表,在併發的情況下可能會全表加鎖(MySQL內部有一些優化操作)。而索引僅僅會鎖住滿足查詢的列。可參考這裡
那麼能不能更快一點呢?我們來試試
字首索引
字首索引就是使用資料的部分來做索引,比如上面 32 位 MD5 值,我們可以選擇 16 位或 20 位來做索引。字首索引能使索引更小,更快。但 MySQL 無法使用字首索引做 GROUP BY 和 ORDER BY 操作。
在建立字首索引時要注意的就是計算選擇性。必須先測試資料的選擇性,接近完整的選擇性時才可以使用字首索引。
比如:MD5 值沒有重複的,那麼選擇性為 1,那麼在使用字首索引時必須確定長度為多少時選擇性為 1,以此作為字首,當然越短越好:)。
50 w 隨機 MD5 值字首選擇性如下:
mysql> select count(distinct LEFT(md5, 32))/count(*) from MD5_3;
+----------------------------------------+
| count(distinct LEFT(md5, 32))/count(*) |
+----------------------------------------+
| 1.0000 |
+----------------------------------------+
1 row in set (1.21 sec)
mysql> select count(distinct LEFT(md5, 16))/count(*) from MD5_3;
+----------------------------------------+
| count(distinct LEFT(md5, 16))/count(*) |
+----------------------------------------+
| 1.0000 |
+----------------------------------------+
1 row in set (0.81 sec)
mysql> select count(distinct LEFT(md5, 7))/count(*) from MD5_3;
+---------------------------------------+
| count(distinct LEFT(md5, 7))/count(*) |
+---------------------------------------+
| 1.0000 |
+---------------------------------------+
1 row in set (0.77 sec)
mysql> select count(distinct LEFT(md5, 6))/count(*) from MD5_3;
+---------------------------------------+
| count(distinct LEFT(md5, 6))/count(*) |
+---------------------------------------+
| 0.9999 |
+---------------------------------------+
1 row in set (0.74 sec)
我們看到了當前綴為 6 時,選擇性變為了 0.9999,不滿足要求,所以字首選擇 7 即可。
這裡我們僅建立一個 16 位字首索引來測試。
建立 16 位字首索引:
mysql> alter table MD5_3 add key(md5(16))
mysql> select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB"查詢結果:
+----------+------------+----------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------------------------------+
| 1 | 0.00024925 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 2 | 0.00025325 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 3 | 0.00022800 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
| 4 | 0.00024625 | select md5 from MD5_3 where md5 = "5IrR8gA5xNzjylvo2fnS19GaHNIg2ZTB" |
+----------+------------+----------------------------------------------------------------------+
平均耗時:0.00024419
比普通索引快了大約 1/5。
可見效能還是有提升的。
Hash 索引
最後,我們來簡單看一下 Hash 索引,因為現在僅假設資料有 50 w 條,當資料量很大時如上千萬條,重複字首就很多了。此時字首索引不一定能優化。我們可以將 MD5 字串進行 Hash,將 Hash 數值結果和對應的 MD5 儲存在同一張表,然後在 Hash 值和 MD5 建立單索引或雙索引(多列索引)。這樣 MySQL InnoDB 會優先比較 Hash 值(左字首),若 Hash 值相同再比較第二列。數值比較會比字串比較快很多。
但這種方法在某些情況下會有缺陷,我們可能需要維護 Hash 值。不過在我的場景下 MD5 值是不變的,固 Hash 值不變。
我們來試試
先給表增加欄位
mysql> alter table MD5_3 add crc int(32) unsigned default 0 not null;
mysql> update MD5_3 set crc = crc32(md5);
Query OK, 500440 rows affected (2.19 sec)
Rows matched: 500440 Changed: 500440 Warnings: 0
可以看到 50W 行資料2.19sec完成,crc速度還是非常快的。
不建立索引測試下兩者速度
mysql> select md5 from MD5_3 where md5 = 'ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I';
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.13 sec)
mysql> select md5 from MD5_3 where crc = crc32('ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I');
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.14 sec)差不多
建立索引看看
mysql> select md5 from MD5_3 where md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select md5 from MD5_3 where
-> crc = crc32("ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I") and
-> md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----------------------------------+
| md5 |
+----------------------------------+
| ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I |
+----------------------------------+
1 row in set (0.00 sec)來看下耗時:
+----------+------------+--------------------------------------------------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+--------------------------------------------------------------------------------------------------------------------------+
| 2 | 0.00058175 | select md5 from MD5_3 where crc = crc32("ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I") and md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I" |
| 3 | 0.00044100 | select md5 from MD5_3 where md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I"
+----------+------------+--------------------------------------------------------------------------------------------------------------------------+
普通索引更快一些,基本差不多,可能因為 CRC32 函式有些耗時。在實際中,我們可以在請求 MD5 前先算好 MD5 的 crc 值再來查詢,這樣速度應該會快些,具體我們應該先測試然後根據實際情況來選擇效能最好的。
在 EXPLAIN 中我發現了一個問題:
mysql> explain select md5 from MD5_3 where crc = crc32("ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I") and md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----+-------------+-------+------+---------------------+-----------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------------+-----------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | MD5_3 | ref | md5_index,crc_index | md5_index | 96 | const | 1 | Using index condition; Using where |
+----+-------------+-------+------+---------------------+-----------+---------+-------+------+------------------------------------+
1 row in set (0.00 sec)
mysql> explain select md5 from MD5_3 where md5 = "ZKT8DyVQ18plvFk2CzLuewIW58q8Pt0I";
+----+-------------+-------+------+---------------+-----------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+-----------+---------+-------+------+--------------------------+
| 1 | SIMPLE | MD5_3 | ref | md5_index | md5_index | 96 | const | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+-----------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
注意 Extra 欄位,一個為 Using index,一個為 Using index condtion。
查了相關資料發現這是 MySQL 5.6新特性—— Index Condition Pushdown(ICP,索引條件下推)
ICP(index condition pushdown)是mysql利用索引(二級索引)元組和篩欄位在索引中的where條件從表中提取資料記錄的一種優化操作。ICP的思想是:儲存引擎在訪問索引的時候檢查篩選欄位在索引中的where條件(pushed index condition,推送的索引條件),如果索引元組中的資料不滿足推送的索引條件,那麼就過濾掉該條資料記錄。
看下 MySQL 手冊的定義:
Index Condition Pushdown (ICP) is an optimization for the case where MySQL retrieves rows from a table using an index. Without ICP, the storage engine traverses the index to locate rows in the base table and returns them to the MySQL server which evaluates the WHERE condition for the rows. With ICP enabled, and if parts of the WHERE condition can be evaluated by using only fields from the index, the MySQL server pushes this part of the WHERE condition down to the storage engine.
簡單來說,就是將本身需要推送到 Server 層的操作在索引上就過濾掉,以提高效能。ICP 可以減少儲存引擎必須訪問基表的次數和 MySQL 伺服器必須訪問儲存引擎的次數。
具體瞭解可以看看這位朋友的文章
順便說一句,MySQL使用的是聚簇索引,我們建立普通索引時,其實是 二級索引,二級索引會儲存 key 和 主鍵,MySQl 會首先在 二級索引 上找到需要的 key,然後獲得對應的主鍵,然後在去聚簇索引上找資料。
對了,當我們確定某一個值是唯一的時,可以設定 唯一約束,MySQL 會預設給唯一約束建立索引~,加快查詢速度。
注意:
MySQL 只會選擇一次索引,若有多個只會選擇一個
MySQL 不是很聰明,有時候我們需要強制指定索引
本文完,如有錯誤,歡迎指正:)
from XiyouLinuxGroup By wwh